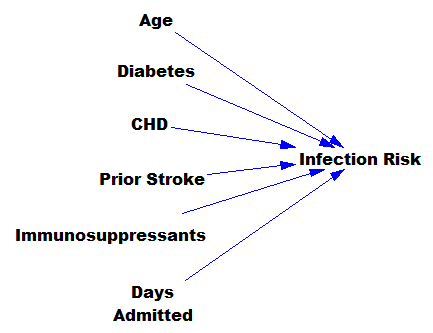
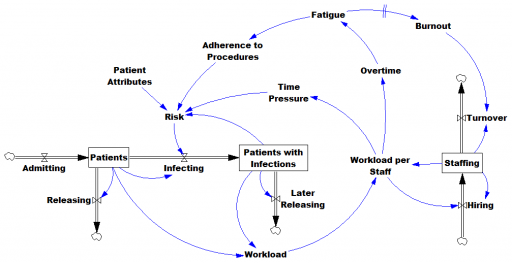
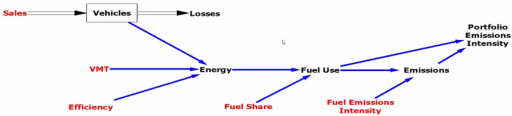
A while back I made a video about spreadsheets, that makes some points about open-loop models vs. real, closed-loop dynamic models:
The short version is that people tend to build this:
when reality works like this:
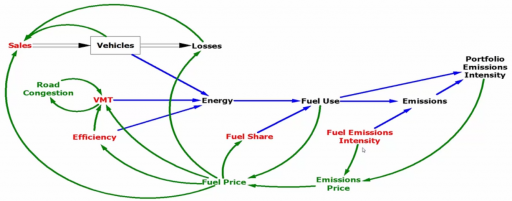
I think there are some understandable reasons to prefer the first, simpler view:
- Just understanding the dynamics of accumulation (here, the vehicle stock) may be mind-blowing enough without adding feedback complexity.
- It’s a start, and certainly better than no model or extrapolation!
Some of the reasons these models get built are a little less appetizing:
- In the short run, some loops really aren’t closed (though the short run is rarely as short as you think, and myopia gets you in trouble).
- They’re quicker and cheaper to build (if you don’t mind less insight).
- Dynamic modeling skills, both for construction and consumption, are not very widespread.
- Open-loop models are easier to calibrate (but a calibration neglecting accumulation and feedback is likely bogus and misleading).
- Open-loop models are easier to manipulate to produce a desired outcome.
I think the last point is key. At Ventana, we’ve discussed – only partly in jest – creating a “propaganda mode” for Vensim and Ventity. This would automate the discovery of a parameterization of a model that both fits history and makes a preferred policy optimal.
Perhaps the ultimate example of this is the RMSM model. 20 years ago, this was the World Bank’s preferred tool for country modeling. When Gerald Barney and Weishuang Qu replicated the model in Vensim, they discovered that is was full of disconnected trees of causality. That would permit creation of a scenario in which GDP growth marched along merrily without any water, for example. Politically, this was actually a feature, not a bug, because some users simply didn’t want to know that their pet project would displace a lot of people or destroy resources.
I think the solution here is to equip people to ask the right questions that close loops. Once there’s an appetite for dynamic, operational thinking, we can supply good modelers to provide the tools.