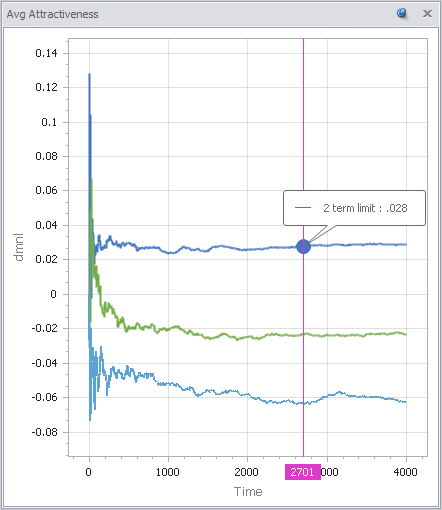
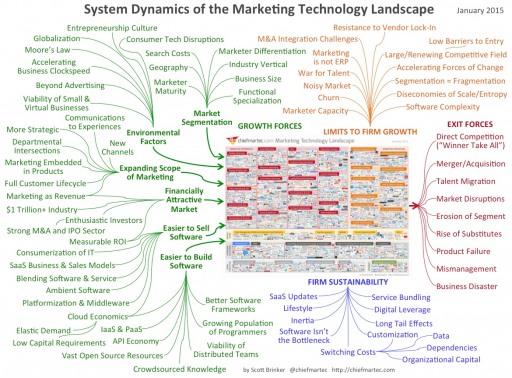
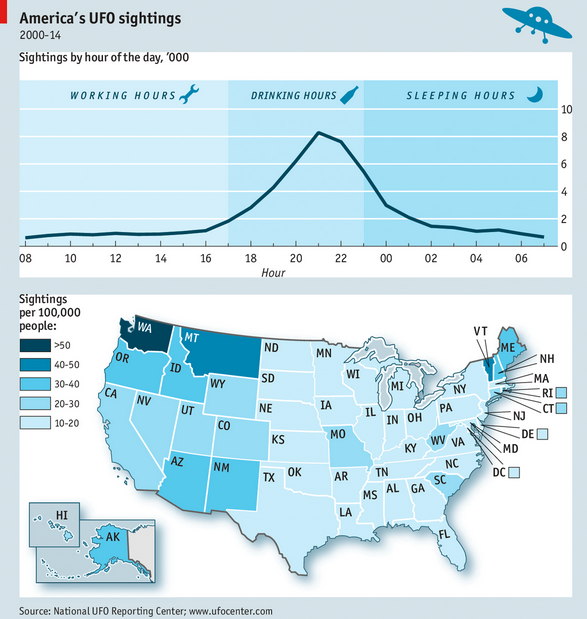
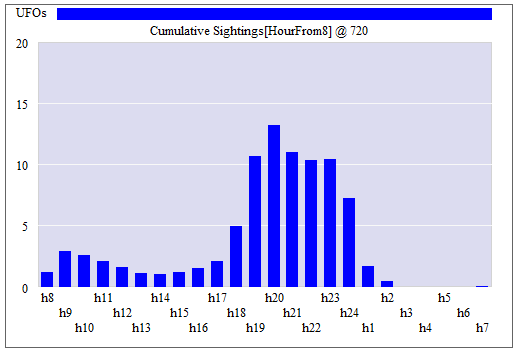
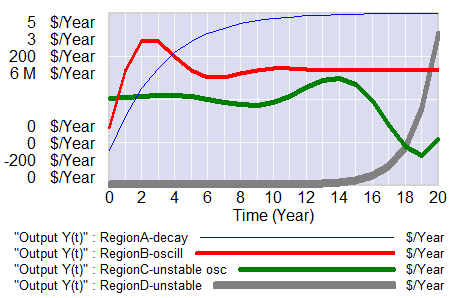
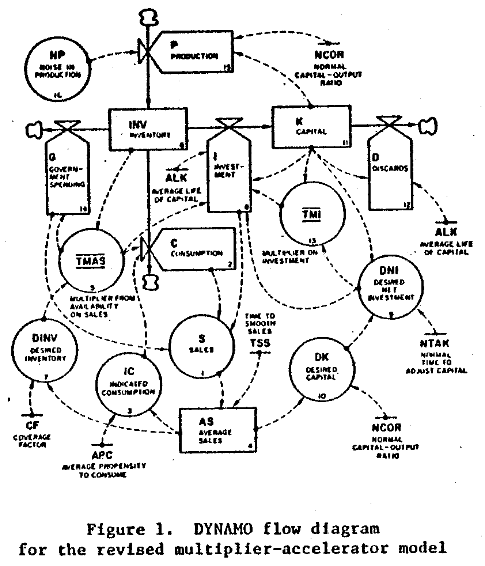
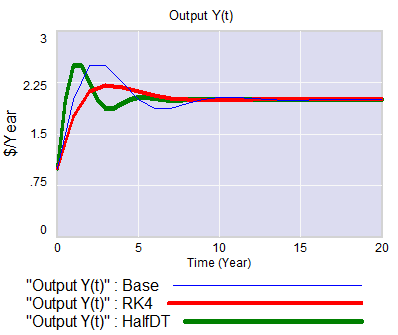
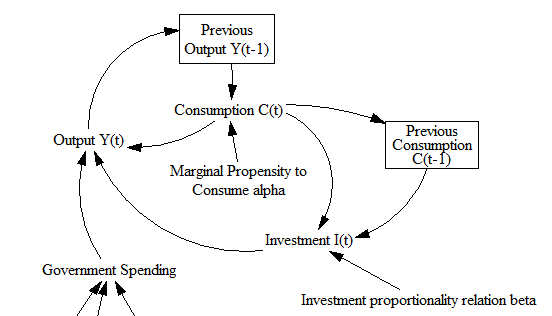
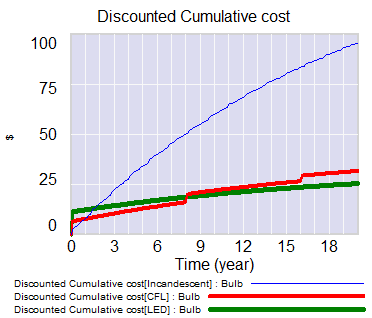
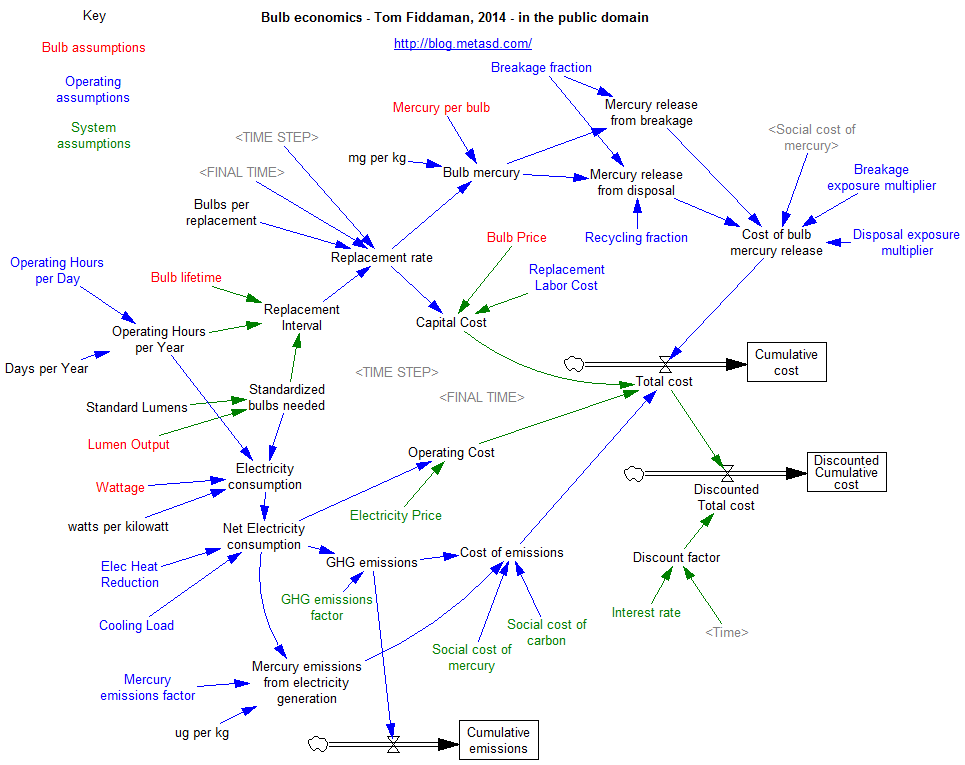
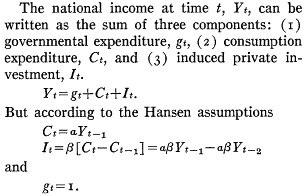A view from simulation & System Dynamics
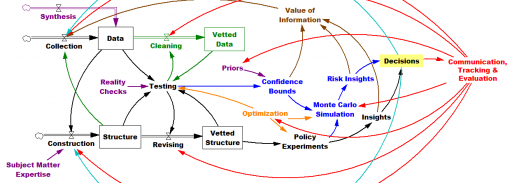
I come to data science from simulation and System Dynamics, which originated in control engineering, rather than from the statistics and database world. For much of my career, I’ve been working on problems in strategy and public policy, where we have some access to mental models and other a priori information, but little formal data. The attribution of success is tough, due to the ambiguity, long time horizons and diverse stakeholders.
I’ve always looked over the fence into the big data pasture with a bit of envy, because it seemed that most projects were more tactical, and establishing value based on immediate operational improvements would be fairly simple. So, I was surprised to see data scientists’ angst over establishing business value for their work:

One part of solving the business value problem comes naturally when you approach things from the engineering point of view. It’s second nature to include an objective function in our models, whether it’s the cash flow NPV for a firm, a project’s duration, or delta-V for a rocket. When you start with an abstract statistical model, you have to be a little more deliberate about representing the goal after the model is estimated (a simulation model may be the delivery vehicle that’s needed).
You can solve a problem whether you start with the model or start with the data, but I think your preferred approach does shape your world view. Here’s my vision of the simulation-centric universe:
The more your aspirations cross organizational silos, the more you need the engineering mindset, because you’ll have data gaps at the boundaries – variations in source, frequency, aggregation and interpretation. You can backfill those gaps with structural knowledge, so that the model-data combination yields good indirect measurements of system state. A machine learning algorithm doesn’t know about dimensional consistency, conservation of people, or accounting identities unless the data reveals such structure, but you probably do. On the other hand, when your problem is local, data is plentiful and your prior knowledge is weak, an algorithm can explore more possibilities than you can dream up in a given amount of time. (Combining the two approaches, by using prior knowledge of structure as “free data” constraints for automated model construction, is an area of active research here at Ventana.)
I think all approaches have a lot in common. We’re all trying to improve performance with systems science, we all have to deal with messy data that’s expensive to process, and we all face challenges formulating problems and staying connected to decision makers. Simulations need better connectivity to data and users, and purely data driven approaches aren’t going to solve our biggest problems without some strategic context, so maybe the big data and simulation worlds should be working with each other more.