Don't just do something, stand there! Reflections on the counterintuitive behavior of complex systems, seen through the eyes of System Dynamics, Systems Thinking and simulation.
Generally, I find the framework useful – it’s a nice way of thinking about the nature of a problem domain and therefore how one might engage. (One caution: the meaning of the chaotic domain differs from that in nonlinear dynamics.)
However, I think the framework’s policy prescription in the complex domain falls short of appreciating the full implications of complexity, at least of dynamic complexity as we think of it in SD: Continue reading “Cynefin, Complexity and Attribution”
The problem is that there isn’t much for skeptics to work with. There aren’t any models that make useful predictions with very low climate sensitivity. In fact, skeptical predictions haven’t really panned out at all. Lindzen’s Adaptive Iris is still alive – sort of – but doesn’t result in a strong negative feedback. The BEST reanalysis didn’t refute previous temperature data. The surfacestations.org effort used crowdsourcing to reveal some serious weather station siting problems, which ultimately amounted to nothing.
And those are really the skeptics’ Greatest Hits. After that, it’s a rapid fall from errors to nuts. No, satellites temperatures don’t show a negative trend. Yes, Fourier and wavelet analyses are typically silly, but fortunately tend to refute themselves quickly. This list could grow long quickly, though skeptics are usually pretty reluctant to make testable models or predictions. That’s why even prominent outlets for climate skepticism have to resort to simple obfuscation.
So, if there’s a silver lining to the proposed panel, it’s that they’d have to put the alleged skeptics’ best foot forward, by collecting and identifying the best models, data and predictions. Then it would be readily apparent what a puny body of evidence that yielded.
When things really warm up, to +9 degrees F (not at all implausible in the long run), 16 of the top 20 analogs are in CO and UT, …
Looking at a lot of these future climate analogs on Google Earth, their common denominator appears to be rattlesnakes. I’m sure they’re all nice places in their own way, but I’m worried about my trees. I’ll continue to hope that my back-of-the-envelope analysis is wrong, but in the meantime I’m going to hedge by managing the forest to prepare for change.
I think there’s a lot more to worry about than trees. Fire, wildlife, orchids, snowpack, water availability, …
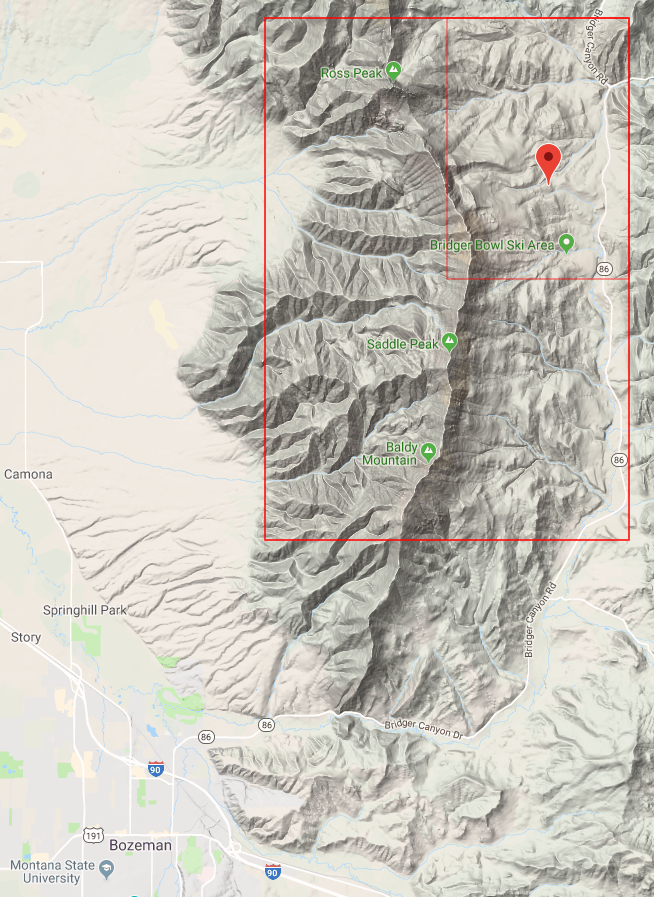
Recently I decided to take another look, partly inspired by the Bureau of Reclamation’s publication of downscaled data. This solves some of the bias correction issues I had in 2008. I grabbed the model output (36 runs from CMIP5) and observations for the 1/8 degree gridpoint containing Bridger Bowl:
Then I used Vensim to do a little data processing, converting the daily time series (which are extremely noisy weather) into 10-year moving averages (i.e., climate). Continue reading “Future Climate of the Bridgers”
This is a brief techy note on compounding in models, prompted by some recent work on financial functions, i.e. compound interest. It’s something you probably know, but don’t think about much. That’s because it’s irrelevant most of the time, except once in a while when it decides to bite you.
Suppose you’re translating someone’s discrete time model, and you decide to translate it to continuous time, because Discrete Time Stinks. The original has: