My slides are here:
The last page links a number of useful references, including new Vensim workshops on data and calibration.

Don't just do something, stand there! Reflections on the counterintuitive behavior of complex systems, seen through the eyes of System Dynamics, Systems Thinking and simulation.
Hybrid models are the solution to blending endogenous elegance with practicality.
My last post probably sounds like I disagree with Jack Homer’s recommendation to tolerate some exogenous drivers and consideration of policy feasibility. Actually I don’t. In fact, we at Ventana probably do more data-intensive SD than anyone. I build hybrid models all the time.
When philosophizing about the best way to change the world, it’s easy to lose sight of some practical considerations that influence choices:
I think there’s no clear answer – the extent to which endogenous or exogenous elements are preferred has to be a situation-specific decision. In my own work, I often use a two-pronged approach, and two ways to structure that have emerged:
I haven’t had much time to write lately – too busy writing Vensim code, working on En-ROADS, and modeling the STEM workforce.
So, in the meantime, here’s a nice tutorial on the use of ODBC database links with Vensim DSS, from Mohammad Jalali:
This can be a powerful way to ingest a lot of data from diverse sources, and to share and archive simulations.
Big data is always a double-edged sword in consulting projects. Without it, you don’t know much. But with it, your time is consumed with discovering all the flaws of the data, which remain because most likely no one else ever looked at it seriously from a strategic/dynamic perspective before. It’s typically transactionally correct, because people verify that they get their orders and paychecks. But at an aggregate level it’s often rife with categorization mismatches across organizational boundaries and other pathologies.
In a recent conversation about data requirements for future Vensim, a colleague observed that the availability of ready access to ‘big data’ in corporations has had curious side effects. One might have hoped for a flowering of model-driven conversations about the firm. Instead, ubiquitous access to data has led managers to spend less time contemplating what data might actually be important. Crucial data for model calibration are often harder to get than they were in the bad old days, because:
Perhaps this is a consequence of the fact that data collection has become incredibly cheap. In the short run, business is about execution of essentially fixed strategies, and raw data is pretty darn useful for that. The problem is that the long run challenge of formulating strategies requires an investment of time to turn data into models (mental or formal), but modeling hasn’t experienced the same productivity revolution. This could leave companies more strategically blind than ever, and therefore accelerate the process of inadvertently walking off a cliff.
Around the same time, I ran into this Wired article about the power of feedback to change behavior. It details a variety of interesting innovations, from radar speed signs to brainwave headbands. I’ve experimented with similar stuff, like Daytum (found here, clever, but soon abandoned) and the Kill-a-watt (still used occasionally).
In the past two or three years, the plunging price of sensors has begun to foster a feedback-loop revolution. …
And today, their promise couldn’t be greater. The intransigence of human behavior has emerged as the root of most of the world’s biggest challenges. Witness the rise in obesity, the persistence of smoking, the soaring number of people who have one or more chronic diseases. Consider our problems with carbon emissions, where managing personal energy consumption could be the difference between a climate under control and one beyond help. And feedback loops aren’t just about solving problems. They could create opportunities. Feedback loops can improve how companies motivate and empower their employees, allowing workers to monitor their own productivity and set their own schedules. They could lead to lower consumption of precious resources and more productive use of what we do consume. They could allow people to set and achieve better-defined, more ambitious goals and curb destructive behaviors, replacing them with positive actions. Used in organizations or communities, they can help groups work together to take on more daunting challenges. In short, the feedback loop is an age-old strategy revitalized by state-of-the-art technology. As such, it is perhaps the most promising tool for behavioral change to have come along in decades.
But the applications don’t quite live up to these big ambitions:
… The GreenGoose concept starts with a sheet of stickers, each containing an accelerometer labeled with a cartoon icon of a familiar household object—a refrigerator handle, a water bottle, a toothbrush, a yard rake. But the secret to GreenGoose isn’t the accelerometer; that’s a less-than-a-dollar commodity. The key is the algorithm that Krejcarek’s team has coded into the chip next to the accelerometer that recognizes a particular pattern of movement. For a toothbrush, it’s a rapid back-and-forth that indicates somebody is brushing their teeth. … In essence, GreenGoose uses sensors to spray feedback loops like atomized perfume throughout our daily life—in our homes, our vehicles, our backyards. “Sensors are these little eyes and ears on whatever we do and how we do it,” Krejcarek says. “If a behavior has a pattern, if we can calculate a desired duration and intensity, we can create a system that rewards that behavior and encourages more of it.” Thus the first component of a feedback loop: data gathering.
Then comes the second step: relevance. GreenGoose converts the data into points, with a certain amount of action translating into a certain number of points, say 30 seconds of teeth brushing for two points. And here Krejcarek gets noticeably excited. “The points can be used in games on our website,” he says. “Think FarmVille but with live data.” Krejcarek plans to open the platform to game developers, who he hopes will create games that are simple, easy, and sticky. A few hours of raking leaves might build up points that can be used in a gardening game. And the games induce people to earn more points, which means repeating good behaviors. The idea, Krejcarek says, is to “create a bridge between the real world and the virtual world. This has all got to be fun.”
This strikes me as a rehash of the corporate experience: use cheap data to solve execution problems, but leave the big strategic questions unaddressed. The torrent of the measurable might even push the crucial intangibles – love, justice, happiness, wisdom – further toward the unmanaged margins of our existence.
My guess is that these technologies can help us solve our universal personal problems, particularly in areas like health and fitness where rewards are proximate in time and space. There might even be beneficial spillovers from healthier, happier personal lifestyles to reduced resource demand and
But I don’t see them doing much to solve global environmental problems, or even large-scale universal problems like urban decay and poverty. Those problems exist, not for lack of data, but for lack of feedback that is compelling to the same degree as the pressures of markets and other financial and social systems, which aren’t all about fun. In the US, we’re not even willing to entertain the idea of creating climate feedback loops. I suspect that the solutions to our biggest problems awaits some other technology that makes us much more productive at devising good strategies based on shared mental models.
Baseline Scenario has a nice post on bad data:
To make a vast generalization, we live in a society where quantitative data are becoming more and more important. Some of this is because of the vast increase in the availability of data, which is itself largely due to computers. Some is because of the vast increase in the capacity to process data, which is also largely due to computers. …
But this comes with a problem. The problem is that we do not currently collect and scrub good enough data to support this recent fascination with numbers, and on top of that our brains are not wired to understand data. And if you have a lot riding on bad data that is poorly understood, then people will distort the data or find other ways to game the system to their advantage.
In spite of ubiquitous enterprise computing, bad data is the norm in my experience with corporate consulting. At one company, I had access to very extensive data on product pricing, promotion, advertising, placement, etc., but the information system archived everything inaccessibly on a rolling 3-year horizon. That made it impossible to see long term dynamics of brand equity, which was really the most fundamental driver of the firm’s success. Our experience with large projects includes instances where managers don’t want to know the true state of the system, and therefore refuse to collect or provide needed data – even when billions are at stake. And some firms jealously guard data within stovepipes – it’s hard to optimize the system when the finance group keeps the true product revenue stream secret in order to retain leverage over the marketing group.
People worry about garbage-in-garbage out, but modeling can actually be the antidote to bad data. If you pay attention to quality, the process of building a model will reveal all kinds of gaps in data. We recently discovered that various sources of vehicle fleet data are in serious disagreement, because of double-counting of transactions and interstate sales, and undercounting of inspections. Once data issues are known, a model can be used to remove biases and filter noise (your GPS probably runs a Kalman Filter to combine a simple physical model of your trajectory with noisy satellite measurements).
Not just any model will do; causal models are important. It’s hard to discover that your data fails to observe physical laws or other reality checks with a model that permits negative cows and buries the acceleration of gravity in a regression coefficient.
The problem is, a lot of people have developed an immune response against models, because there are so many that don’t pay attention to quality and serve primarily propagandistic purposes. The only antidote for that, I think, is to teach modeling skills, or at least model consumption skills, so that they know the right questions to ask in order to separate the babies from the bathwater.
Rendering is a process that converts waste animal tissue into stable, value-added materials. Rendering can refer to any processing of animal byproducts into more useful materials, or more narrowly to the rendering of whole animal fatty tissue into purified fats like lard or tallow. …
The majority of tissue processed comes from slaughterhouses, but also includes restaurant grease and butcher shop trimmings. This material can include the fatty tissue, bones, and offal, as well as entire carcasses of animals condemned at slaughterhouses, and those that have died on farms (deadstock), in transit, etc. …
Converting data from public sources and business archives into quality material, suitable for use in modeling, is often equally arduous if not quite so disgusting. Just substitute “back office systems” for “slaughterhouses,” “basement paper archives” for “fatty tissue, bones, and offal,” etc. Electronic systems create vast quantities of the stuff, but much of it could be aptly described as “deadstock.” The problem is that people can easily tolerate some dreck in material that they’re just browsing for information, so systems don’t go to great lengths to eliminate it. Models are pickier – a few extra zeroes somewhere can really affect calibration, for example.
There’s an interesting new weapon in the war against arcane formats, inconsistent field coding and other data flaws, google refine. It’s apparently a Freebase spinoff. I’ve only used it for one task so far: grouping ad hoc text in a column, recognizing that “Ventana Systems,” “Ventana Systems, Inc.,” and “Ventanna Systems” all mean the same thing. It has useful filtering and clustering tools that largely automate such painful manual tasks. It can also do something else I’ve often hungered for in the past: transform an indented list into a table format. I suspect there’s much more depth that I haven’t even seen. Best of all, it’s fairly easy to get started.
It won’t cure all sins of corporate data management, like throwing away everything more than a few years old, but I’ll definitely reach for it next time I have a platefull of messy data to clean up for a model. Check it out.
No animals were harmed in the writing of this post.
The following is another extended excerpt from Jim Thompson and Jim Hines’ work on financial guarantee programs. The motivation was a client request for comparison of modeling results to data. The report pushes back a little, explaining some important limitations of model-data comparisons (though it ultimately also fulfills the request). I have a slightly different perspective, which I’ll try to indicate with some comments, but on the whole I find this to be an insightful and provocative essay.
First and Foremost, we do not want to give credence to the erroneous belief that good models match historical time series and bad models don’t. Second, we do not want to over-emphasize the importance of modeling to the process which we have undertaken, nor to imply that modeling is an end-product.
In this report we indicate why a good match between simulated and historical time series is not always important or interesting and how it can be misleading Note we are talking about comparing model output and historical time series. We do not address the separate issue of the use of data in creating computer model. In fact, we made heavy use of data in constructing our model and interpreting the output — including first hand experience, interviews, written descriptions, and time series.
This is a key point. Models that don’t report fit to data are often accused of not using any. In fact, fit to numerical data is only one of a number of tests of model quality that can be performed. Alone, it’s rather weak. In a consulting engagement, I once ran across a marketing science model that yielded a spectacular fit of sales volume against data, given advertising, price, holidays, and other inputs – R^2 of .95 or so. It turns out that the model was a linear regression, with a “seasonality” parameter for every week. Because there were only 3 years of data, those 52 parameters were largely responsible for the good fit (R^2 fell to < .7 if they were omitted). The underlying model was a linear regression that failed all kinds of reality checks.
There are lots of good reasons for building models without data. However, if you want to measure something (i.e. estimate model parameters), produce results that are closely calibrated to history, or drive your model with historical inputs, you need data. Most statistical modeling you’ll see involves static or dynamically simple models and well-behaved datasets: nice flat files with uniform time steps, units matching (or, alarmingly, ignored), and no missing points. Things are generally much messier with a system dynamics model, which typically has broad scope and (one would hope) lots of dynamics. The diversity of data needed to accompany a model presents several challenges:
The mathematics for handling the technical estimation problems were developed by Fred Schweppe and others at MIT decades ago. David Peterson’s thesis lays out the details for SD-type models, and most of the functionality described is built into Vensim. It’s also possible, of course, to go a simpler route; even hand calibration is often effective and reasonably quick when coupled with Synthesim.
Either way, you have to get your data corralled first. For a simple model, I’ll build the data right into the dynamic model. But for complicated models, I usually don’t want the main model bogged down with units conversions and links to a zillion files. In that case, I first build a separate datamodel, which does all the integration and passes cleaned-up series to the main model as a fast binary file (an ordinary Vensim .vdf). In creating the data infrastructure, I try to maximize three things:
This can be quite a bit of work up front, but the payoff is large: less model rework later, easy updates, and higher quality. It’s also easier generate graphics or statistics that help others to gain confidence in the model, though it’s sometimes important to help them recognize that goodness of fit is a weak test of quality.
It’s good to build the data infrastructure before you start modeling, because that way your drivers and quality control checks are in place as you build structure, so you avoid the pitfalls of an end-of-pipe inspection process. A frequent finding in our corporate work has been that cherished data is in fact rubbish, or means something quite different that what users have historically assumed. Ventana colleague Bill Arthur argues that modern IT practices are making the situation worse, not better, because firms aren’t retaining data as long (perhaps a misplaced side effect of a mania for freshness).
Continue reading “The Obscure Art of Datamodeling in Vensim”
System dynamics models handle data in various ways. Traditionally, time series inputs were embedded in so-called lookups or table functions (DYNAMO users will remember TABHL for example). Lookups are really best suited for graphically describing a functional relationship. They’re really cool in Vensim’s Synthesim mode, where you can change the shape of a relationship and watch the behavioral consequence in real time.
Time series data can be thought of as f(time), so lookups are often used as data containers. This works decently when you have a limited amount of data, but isn’t really suitable for industrial strength modeling. Those familiar with advanced versions of Vensim may be aware of data variables – a special class of equation designed for working with time series data rather than endogenous structure.
There are many advantages to working with data variables:
I think there are just two reasons to use lookups as containers for data:
Otherwise, go for data variables. Occasionally, there are technical limitations that make it impossible to accomplish something with a data equation, but in those cases the solution is generally a separate data model rather than use of lookups. More on that soon.
I’ve been testing a data mining and visualization tool called Tableau. It seems to be a hot topic in that world, and I can see why. It’s a very elegant way to access large database servers, slicing and dicing many different ways via a clean interface. It works equally well on small datasets in Excel. It’s very user-friendly, though it helps a lot to understand the relational or multidimensional data model you’re using. Plus it just looks good. I tried it out on some graphics I wanted to generate for a collaborative workshop on the Western Climate Initiative. Two examples:
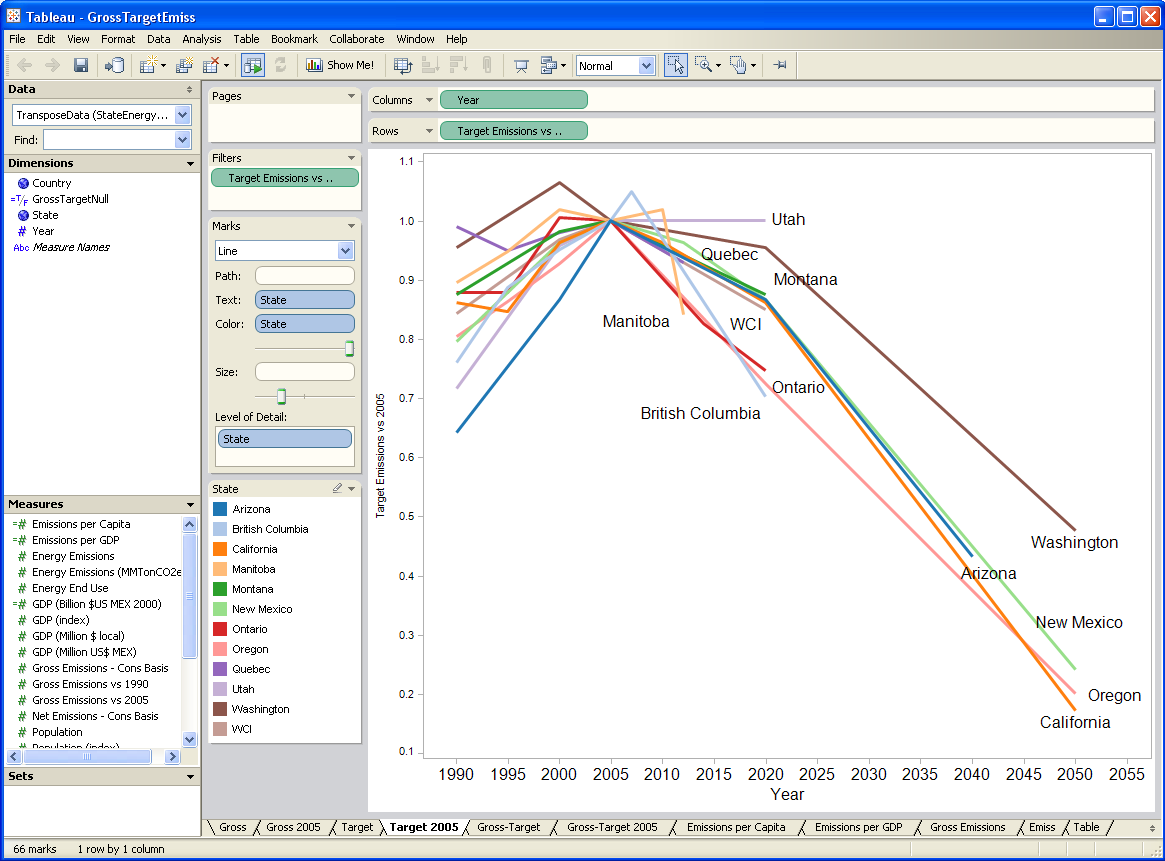
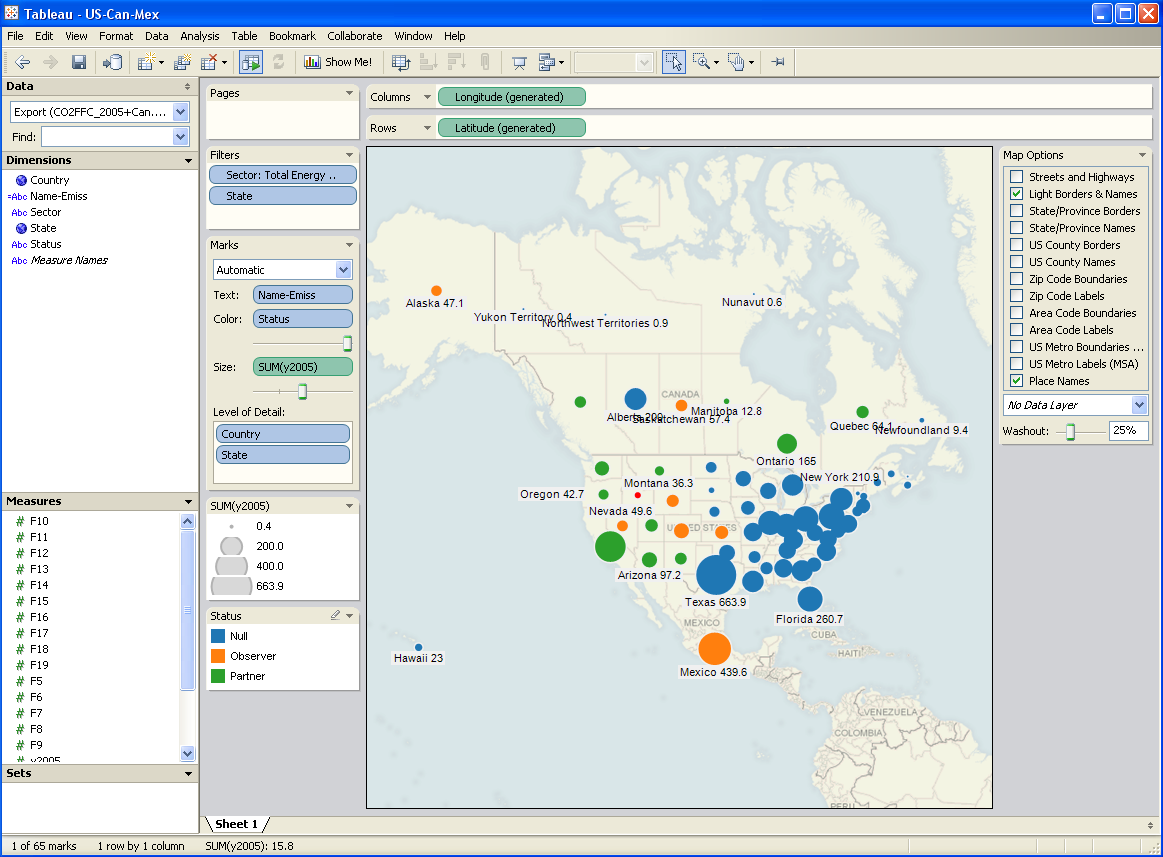
A year or two back, I created a tool, based on VisAD, that uses the Vensim .dll to do multidimensional visualization of model output. It’s much cruder, but cooler in one way: it does interactive 3D. Anyway, I hoped that Tableau, used with Vensim, would be a good replacement for my unfinished tool.
After some experimentation, I think there’s a lot of potential, but it’s not going to be the match made in heaven that I hoped for. Cycle time is one obstacle: data can be exported from Vensim in .tab, .xls, or a relational table format (known as “data list” in the export dialog). If you go the text route (.tab), you have to pass through Excel to convert it to .csv, which Tableau reads. If you go the .xls route, you don’t need to pass through Excel, but may need to close/open the Tableau workspace to avoid file lock collisions. The relational format works, but yields a fundamentally different description of the data, which may be harder to work with.
I think where the pairing might really shine is with model output exported to a database server via Vensim’s ODBC features. I’m lukewarm on doing that with relational databases, because they just don’t get time series. A multidimensional database would be much better, but unfortunately I don’t have time to try at the moment.
Whether it works with models or not, Tableau is a nice tool, and I’d recommend a test drive.