I ran across an interesting dynamic model of the opioid epidemic that makes a good target for replication and critique:
Prevention of Prescription Opioid Misuse and Projected Overdose Deaths in the United States
Qiushi Chen; Marc R. Larochelle; Davis T. Weaver; et al.
Importance Deaths due to opioid overdose have tripled in the last decade. Efforts to curb this trend have focused on restricting the prescription opioid supply; however, the near-term effects of such efforts are unknown.
Objective To project effects of interventions to lower prescription opioid misuse on opioid overdose deaths from 2016 to 2025.
Design, Setting, and Participants This system dynamics (mathematical) model of the US opioid epidemic projected outcomes of simulated individuals who engage in nonmedical prescription or illicit opioid use from 2016 to 2025. The analysis was performed in 2018 by retrospectively calibrating the model from 2002 to 2015 data from the National Survey on Drug Use and Health and the Centers for Disease Control and Prevention.
…
Conclusions and Relevance This study’s findings suggest that interventions targeting prescription opioid misuse such as prescription monitoring programs may have a modest effect, at best, on the number of opioid overdose deaths in the near future. Additional policy interventions are urgently needed to change the course of the epidemic.
The model is fully described in supplementary content, but unfortunately it’s implemented in R and described in Greek letters, so it can’t be run directly:
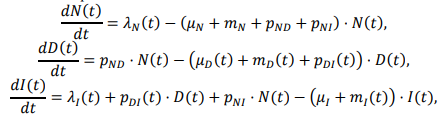
That’s actually OK with me, because I think I learn more from implementing the equations myself than I do if someone hands me a working model.
While R gives you access to tremendous tools, I think it’s not a good environment for designing and testing dynamic models of significant size. You can’t easily inspect everything that’s going on, and there’s no easy facility for interactive testing. So, I was curious whether that would prove problematic in this case, because the model is small.
Here’s what it looks like, replicated in Vensim:
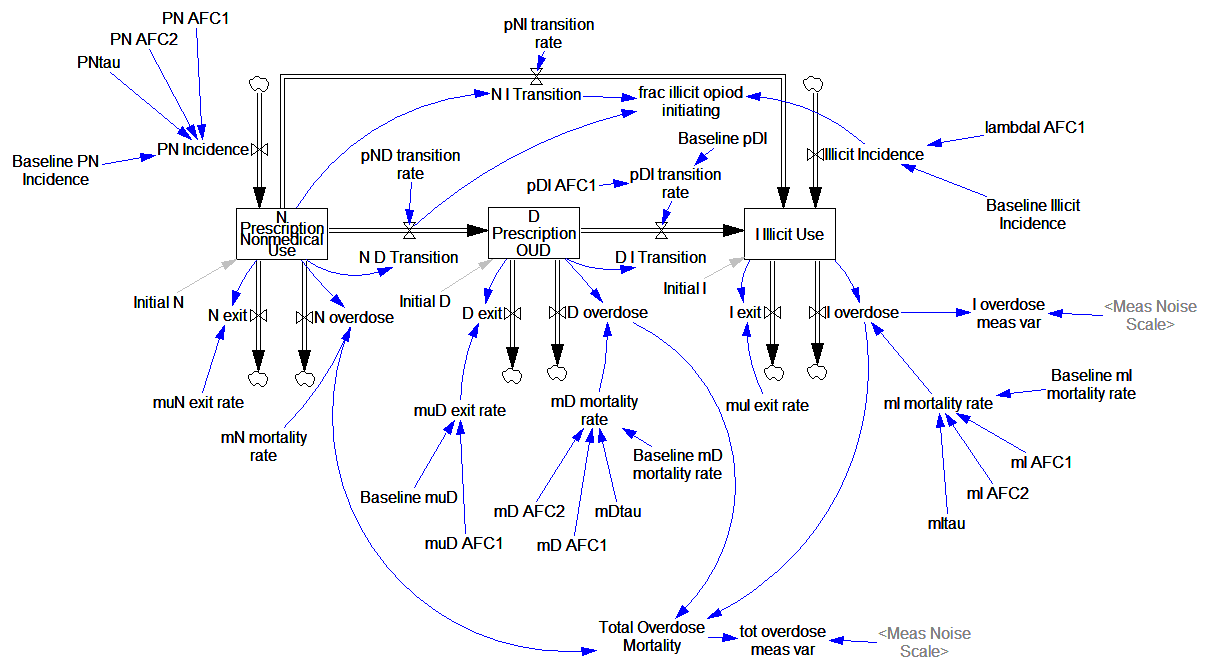
It looks complicated, but it’s not complex. It’s basically a cascade of first-order delay processes: the outflow from each stock is simply a fraction per time. There are no large-scale feedback loops. Continue reading “Opiod Epidemic Dynamics”