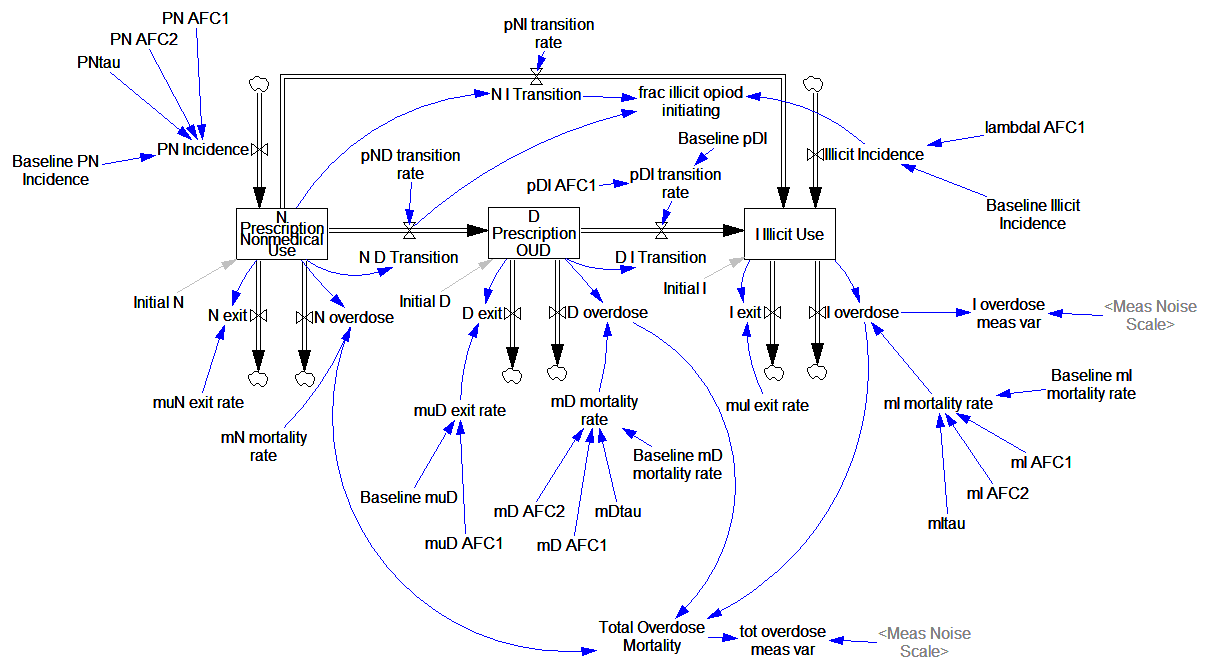
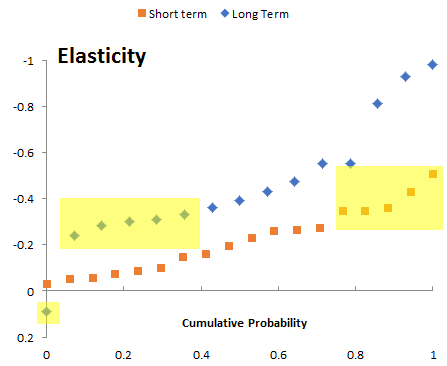
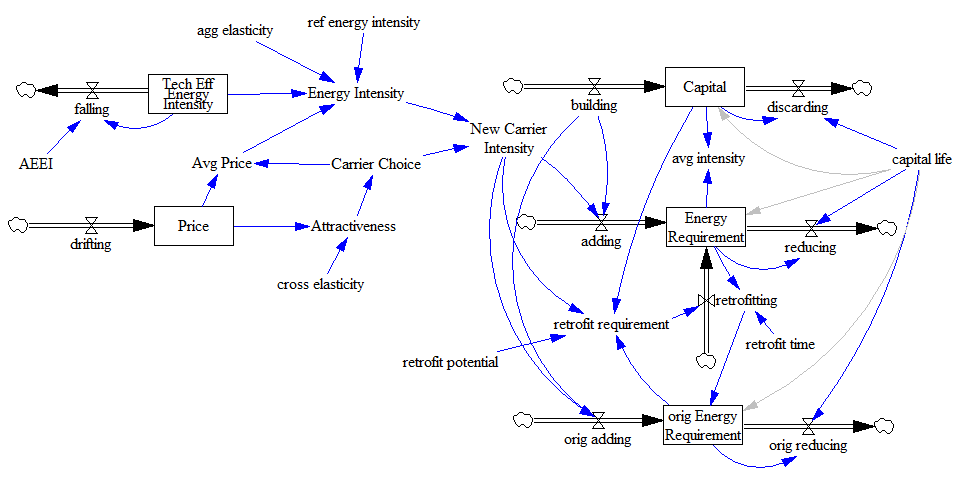
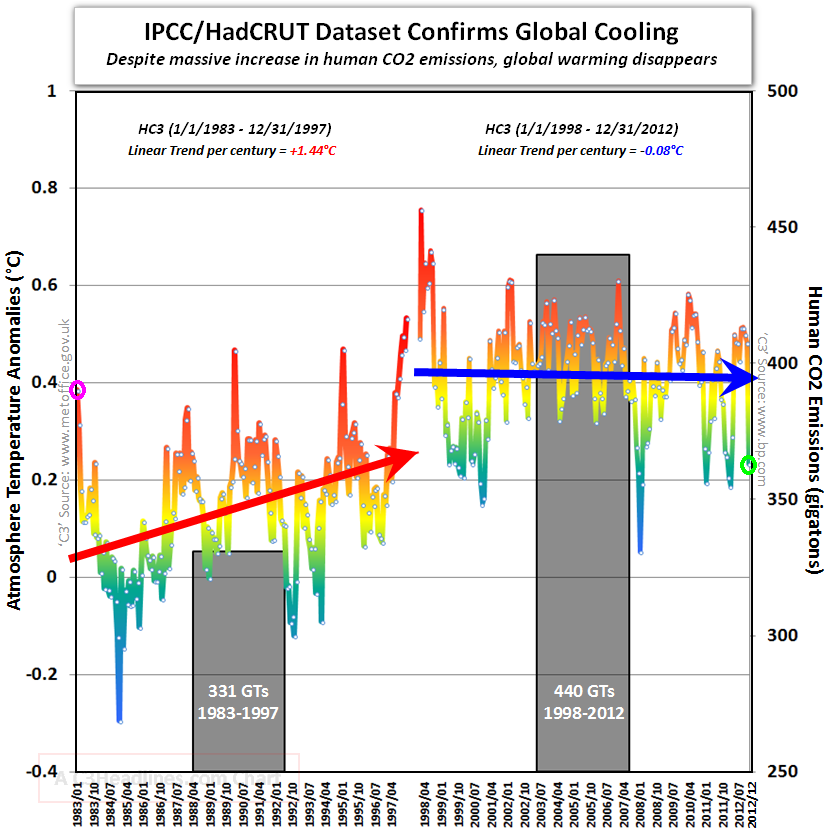
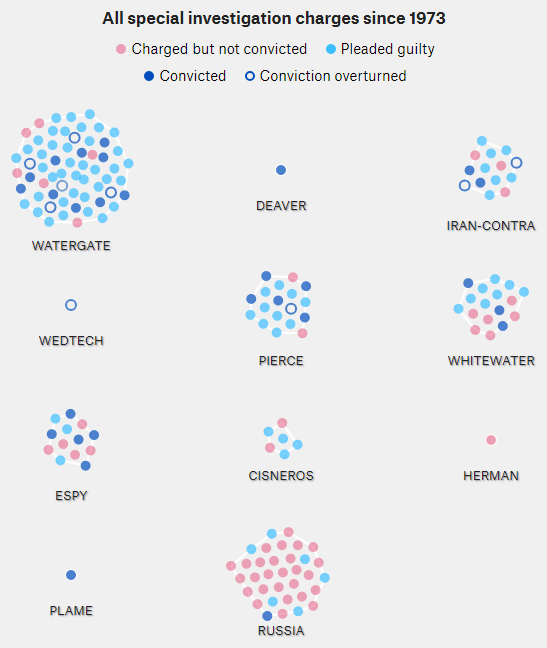
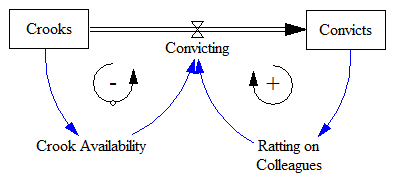
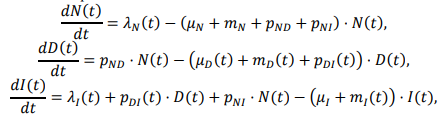If you’ve followed the work on the System Dynamics National Model, you know that it came to an end uncompleted. Yet, there is a vast amount of interesting structure in the model, and there have been many productive spinoffs from the work. How can this be?
I think there are several explanations. One is that the problem is intrinsically hard. Economies are big, and they operate at many scales. There are micro processes (firms investing in capacity and choosing technologies) but also evolutionary processes (firms getting it wrong die).
This means there’s no one to ask when you want to understand how things work. You can’t ask someone about their car fuel purchase habits and aggregate up to national energy intensity, because their understanding encompasses Ford vs. Chevy, not all the untried and future contingencies in the economic network beyond their limited sphere of influence.
You can’t ask the data. Data must always be interpreted through the lens of a model, and model structure is what we lack. If we had a lot more data, we might be able to infer more about the constraints on plausible structures, but economic data is pretty sparse compared to the number of constructs we need to understand.
In spite of this, dynamic general equilibrium models have managed to model whole economies anyway. Why have they succeeded? I think there are two answers. First, they cheat. They reduce all behavior to an optimization algorithm. That’s guaranteed to yield an answer, but whether that answer has any relevance to the real world is debatable. Second, they give answers that people who fund economic models like: the world is just fine as it is, externalities don’t exist, and all policy interventions are costly.
All this is not to say that we’ll never have useful national models; indeed we already have many models (including the DGEs) that are useful for some purposes. But we still have a long way to go before we have solid macrobehavior from microfoundations to inform policy broadly.