Don't just do something, stand there! Reflections on the counterintuitive behavior of complex systems, seen through the eyes of System Dynamics, Systems Thinking and simulation.
I’m not aware of a citation that’s on point to the question, but I suspect that digging into the economic roots of these alternatives would show that elasticity was (and is) typically employed in nondynamic situations, with proximate cause and effect, like the typical demand curve Q=P^e, where the first version is more convenient. In any case the economic notion of elasticity was introduced in 1890, long before econometrics, which is basically a child of the computational age. As a practical matter, in many situations the two interpretations will be functionally equivalent, but there are some important differences in edge cases.
If the relationship between x and y is black box, i.e. you don’t have or can’t solve the functional form, then the time-derivative (second) version may be the only possible approach. This seems rare. (It did come up from time to time in some early SD languages that lacked a function for extracting the slope from a lookup table.)
The time-derivative version however has a couple challenges. In a real simulation dt is a finite difference, so you will have an initialization problem: at the start of the simulation, observed dx/dt and dy/dt will be zero, with epsilon undefined. You may also have problems of small lags from finite dt, and sensitivity to noise.
The common constant-elasticity,
Y = Yr*(X/Xr)^elasticity
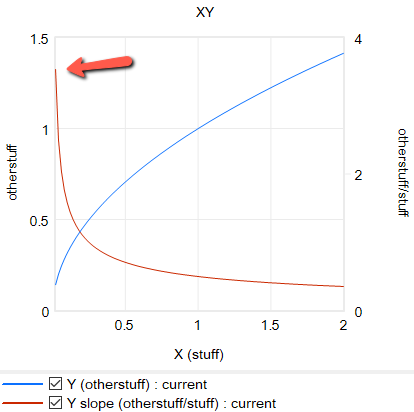
formulation itself is problematic in many cases, because it requires infinite price to extinguish demand, and produces infinite demand at 0 price. A more subtle problem is that the slope of this relationship is,
Y = elasticity*Yr/Xr*(X/Xr)^(elasticity-1)
for 0 < elasticity < 1, the slope of this relationship approaches infinity as X approaches 0 from the positive side. This gives feedback loops infinite gain around that point, and can lead to extreme behavior.
Constant elasticity with extreme slope near 0, e=.5
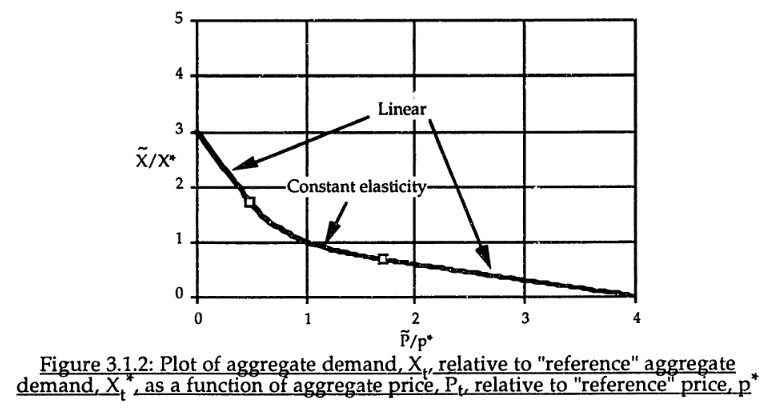
For robustness, an alternative functional form may be needed. For example, in market experiments Kampmann spliced linear segments onto a central constant-elasticity demand curve: https://dspace.mit.edu/handle/1721.1/13159?show=full (page 147):
Another option is to change functional forms. It’s sensible to abandon the constant-elasticity assumption. One good way to do this for an upward-sloping supply curve or similar is with the CES (constant elasticity of substitution) production function, which ironically doesn’t have constant elasticity when used with a fixed factor. The equation is:
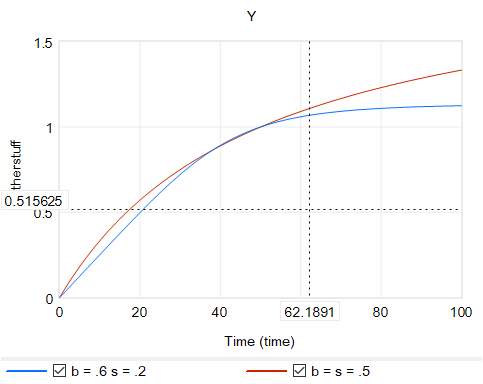
Y = Yr*(b + (1-b)*(X/Xr)^p)^(1/p)
with
p = (s-1)/s
where s is the elasticity of substitution. The production function interpretation of b is that it represents the share of a fixed factor in producing output Y. More generally, s and b control the shape of the curve, which conveniently passes through (0,0) and (Xr,Yr). There are two key differences between this shape and an elasticity formulation like Y=X^e:
The slope at 0,0 remains finite.
There’s an upper bound to Y for large X.
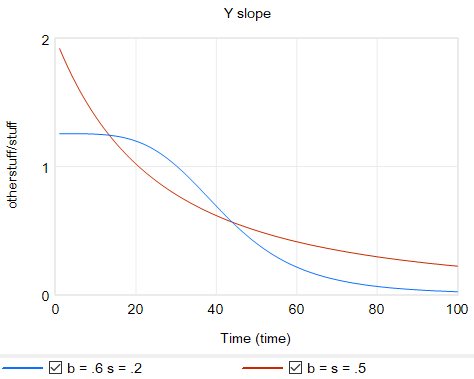
Output Y from CES with a fixed factor for two sets of b, s values.Slope for the same CES instances.
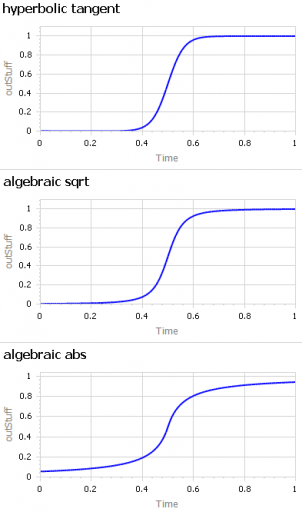
Another option that’s often useful is to use a sigmoid function.
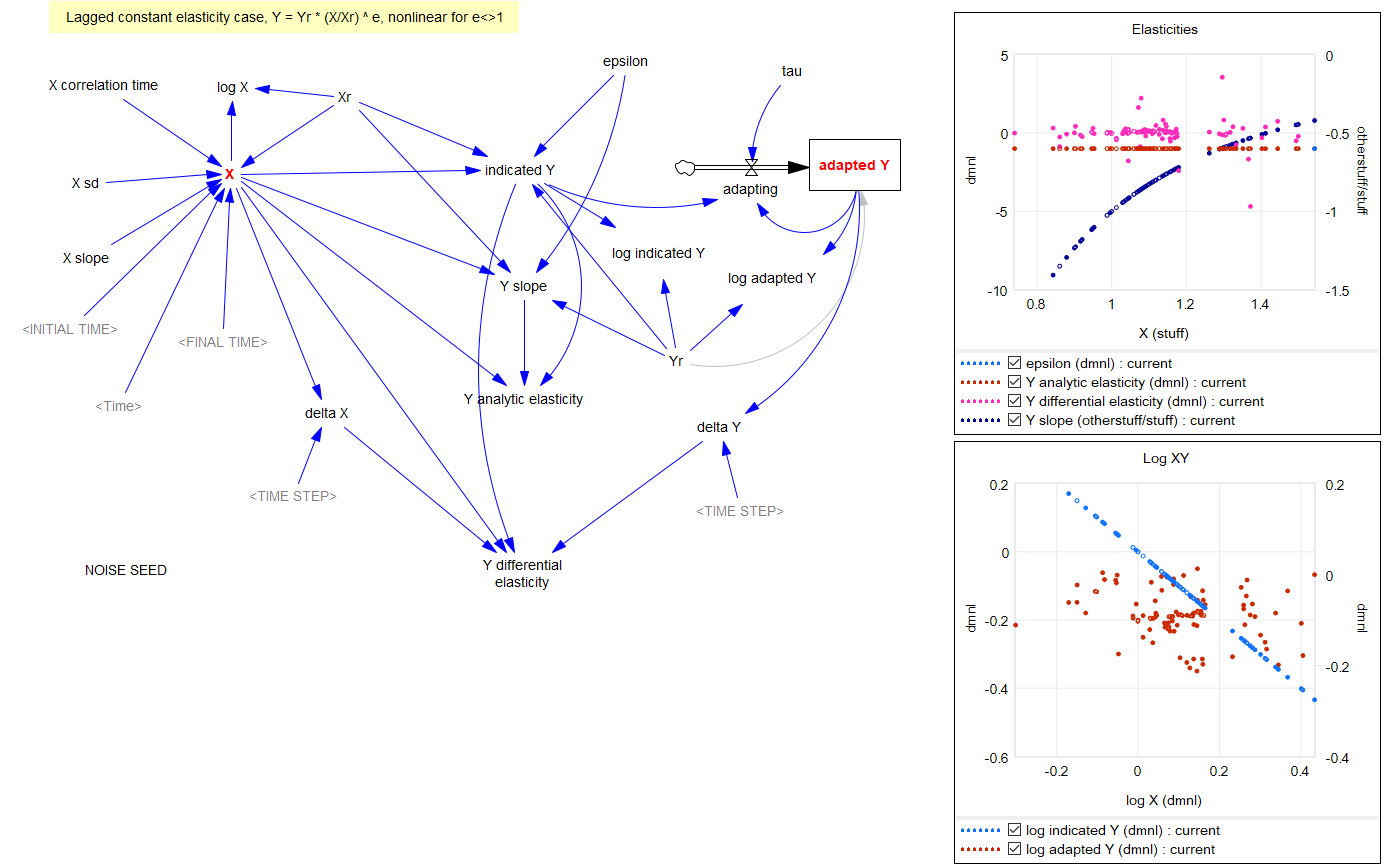
Returning to the original question, about the merits of (dy/y)/(dx/x) vs. the time-derivative form (dy/dt)/(dx/dt)*x/y, I think there’s one additional consideration: what if the causality isn’t exactly proximate, but rather involves an integration? For example, we might have something like:
Y* = Yr*(X/Xr)^elasticity ~ indicated Y
Y = SMOOTH( Y*, tau ) ~ actual Y with an adaptation lag tau
This is using quasi-Vensim notation of course. In this case, if we observe dY/dt, and compare it with dX/dt, we may be misled, because the effect of elasticity is confounded with the effect of the lag tau. This is especially true if tau is long relative to the horizon over which we observe the behavior.
Constant elasticity with noise and intervening stock.
This is a lot of words to potentially dodge Guido’s original question, but I hope it proves useful.
For completeness, here are some examples of some of the features discussed above. These should run in Vensim including free PLE (please comment if you find issues).
I’ve long wanted to translate the Sterman-Wittenberg model of Kuhnian paradigm revolutions to Ventity. The original was in Dynamo, and I translated that to Vensim, but neither is really satisfactory, because both require provisioning array space for new paradigms statically, before it’s needed. This means simulating lots of useless 0s, and even worse, looking at them in the output.
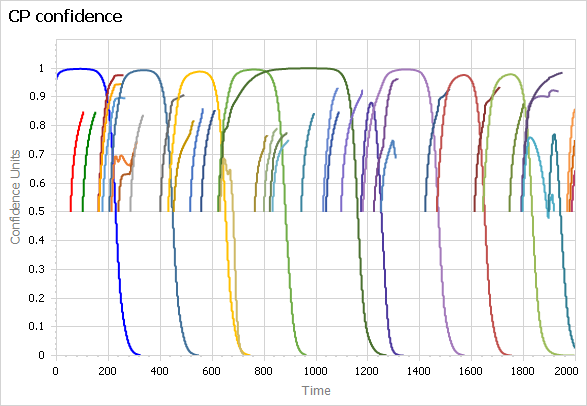
The model is about the lifecycle of scientific paradigms, so a central feature is the occasional introduction and evolution of new paradigms, which eventually accumulate enough anomalies to erode confidence, making them vulnerable to the next great idea. So ideally, you’d like to introduce new paradigms dynamically and delete them when they no longer have many adherents. Dynamic creation and deletion of entities is of course a core feature of Ventity – it’s the tool this model has been waiting for all those years.
I finally got around to translating my Vensim version to Ventity recently. It works beautifully:
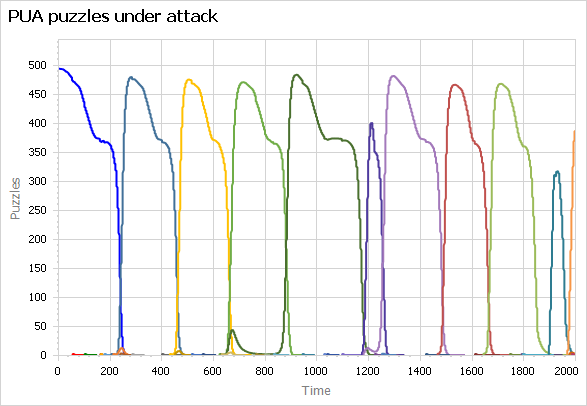
Above, paradigm confidence, showing eight dominant paradigms as well as many smaller paradigms that never rise to dominance. They disappear when they run out of adherents. Below, puzzles under attack for the same paradigms.
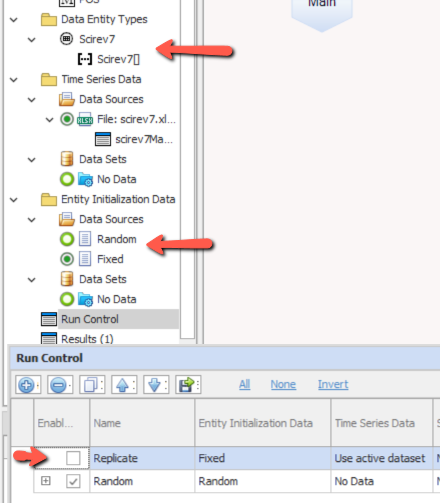
A minor note on use: the Run Config includes two setups: “replicate” and “random”. The “replicate” setup, which is inactive by default, launches paradigms at fixed times given by initialization data from a run of the Vensim version. This makes it possible to compare the simulations without divergence from randomness. However, the randomized run will normally be the more interesting way to work with this model.
The model (requires Ventity, which has a free trial license):
As promised, here’s my solution to the escalator problem … several, actually.
Before getting into the models, a point about simulation vs. analytic solutions. You can solve this problem on pencil and paper with simple algebra. This has some advantages. First, you can be completely data free, by using symbols exclusively. You don’t need to know the height of the stair or a person’s climbing speed, because you can call these Hs and Vc and solve the problem for all possible values. A simulation, by contrast, needs at least notional values for these things. Second, you may be able to draw general conclusions about the solution from its structure. For example, if it takes the form t = H/V, you know there’s some kind of singularity at V=0. With a simulation, if you don’t think to test V=0, you might miss an important special case. It’s easy to miss these special cases in a parameter space with many dimensions.
On the other hand, if there are many dimensions, this may imply that the problem will be difficult or impossible to solve analytically, so simulation may be the only fallback. A simulation also makes it easier to play with the model interactively (e.g., Vensim’s Synthesim mode) and to incorporate features like model-data comparisons and optimization. The ability to play invites experimentation with parameter values you might not otherwise think of. Also, drawing a stock-flow diagram may allow you to access other forms of visual thinking, or analogies with structurally similar systems in different domains.
With that prelude, here’s how I conceived of the problem:
You’re in a building, at height=0 (feet in my model, but the particular unit doesn’t matter as long as you have and check units).
Stairs rise to height=100.
There’s an escalator from 100 to 200 ft.
Then stairs resume, to infinite height.
The escalator ascends at 1ft/sec and the climber at 1ft/sec whether on stairs or not.
At some point, the climber rests for 60sec, at which point their rate of climb is 0, but they continue to ascend if on the escalator.
Of course all the numbers can be changed on the fly, but these concepts at least have to exist.
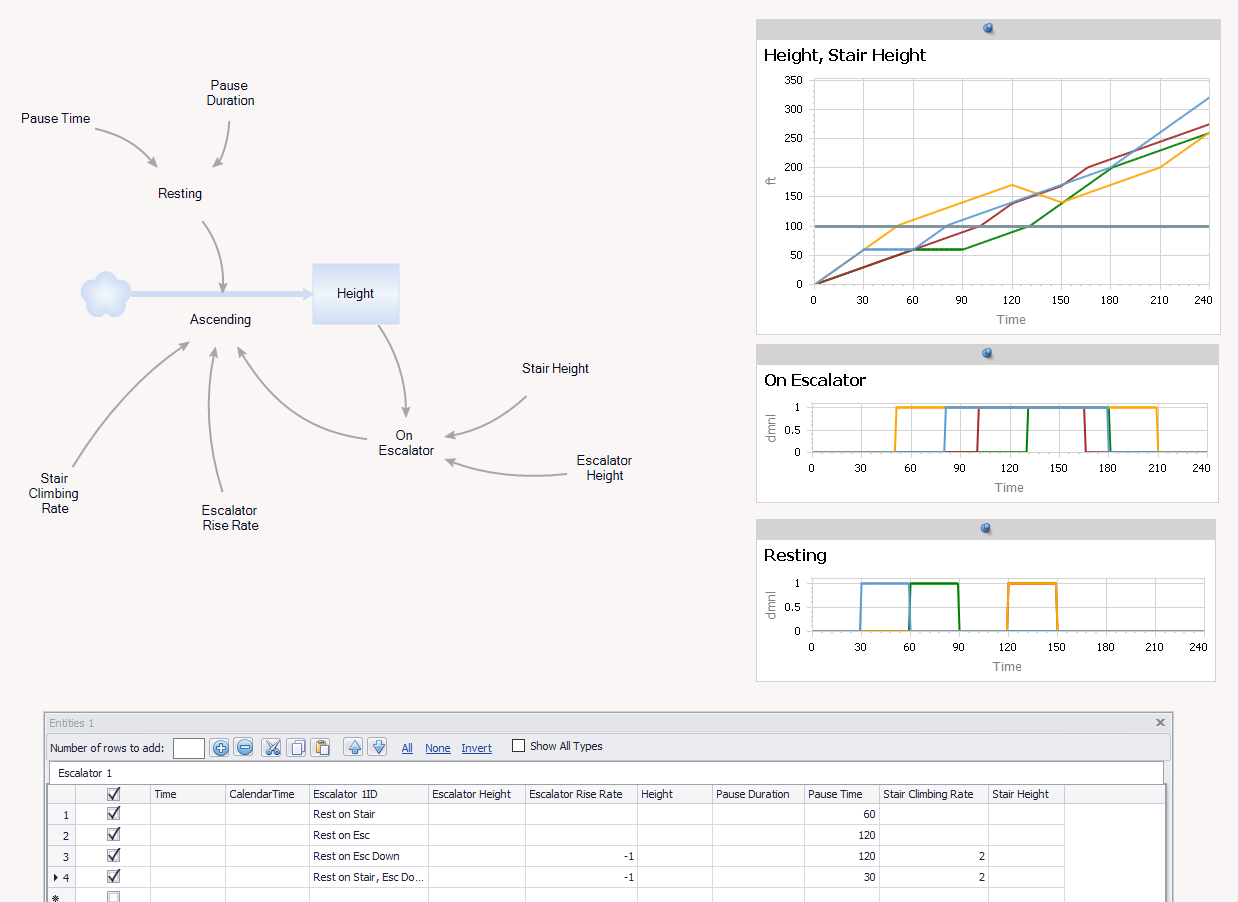
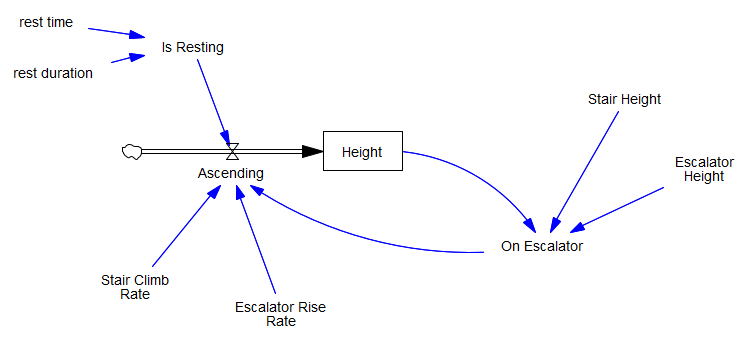
I think of this as a problem of pure accumulation, with height as a stock. But it turned out that I still needed some feedback to determine where the climber was – on the stairs, or on the escalator:
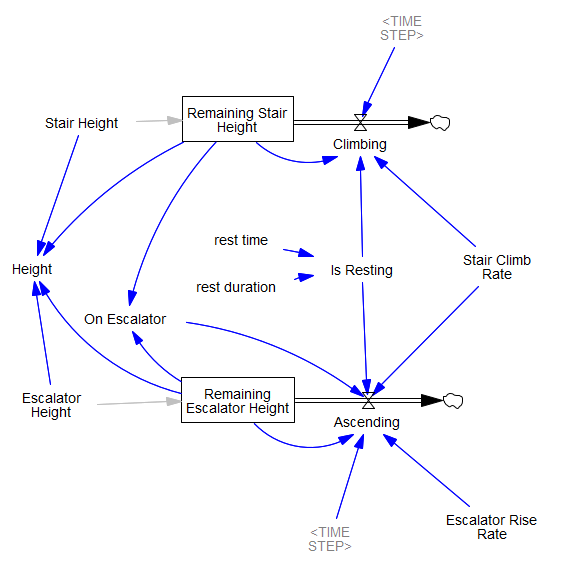
At first it struck me that this was “fake” feedback – an accounting artifact – and that it might go away with an alternate conception. Here’s my implementation of Pradeesh Kumar’s idea, from the SDS Discussion Group on Facebook, with the height to be climbed on the stairs and escalator as a stock, with an outflow as climbing is accomplished:The logical loop is still there, and the rest of the accounting is more complex, so I think it’s inevitable.
Finally, I built the same model in Ventity, so I could use multiple entities to quickly store and replicate several scenarios:
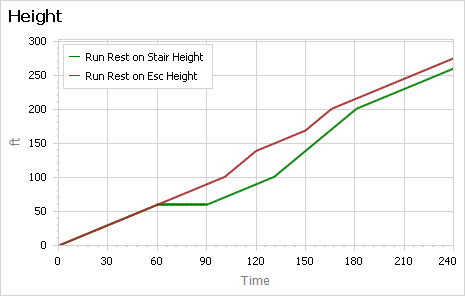
Looking at the Ventity output, resting on the escalator is preferable:
While resting on the stairs, nothing happens. While resting on the escalator, you continue to make gains.
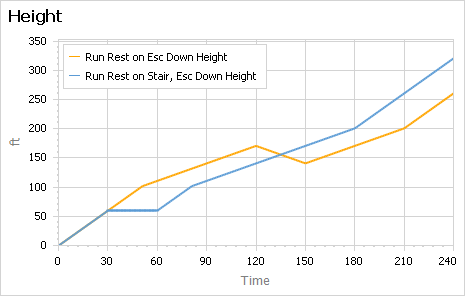
There’s an unstated assumption present in all the twitter answers I’ve seen: the escalator is the up escalator. I actually prefer to go up the down escalator, though it attracts weird looks. If you do that, resting on the escalator is catastrophic, because you lose ground that you previously gained:
I suspect there are other interesting edge cases to explore.
JJ Lauble has also created a version, posted at the Vensim forum. I haven’t had a chance to explore it yet, but it looks like he may have used Vensim to explore the algebraic solution, with the time axis as a way to scan the solution space with Synthesim overrides.
Most System Dynamics software includes a pair of TREND and FORECAST functions. For historic reasons, these are typically the simplest possible first-order structure, which is fine for continuous, deterministic models, but not the best for applications with noise or real data. The waters are further muddied by the fact that Excel has a TREND function that’s really FORECASTing, plus newer FORECAST functions with methods that may differ from typical SD practice. Business Dynamics describes a third-order TREND function that’s considerably better for real-world applications.
As a result of all this variety, I think trend measurement and forecasting remain unnecessarily mysterious, so I built the model below to compare several approaches.
Goal
The point of TREND and FORECAST functions is to model the formation of expectations in a way that closely matches what people in the model are really doing.
This could mean a wide variety of things. In many cases, people aren’t devoting formal thought to observing and predicting the phenomenon of interest. In that case, adaptive expectations may be a good model. The implementation in SD is the SMOOTH function. Using a SMOOTH to set expectations says that people expect the future to be like the past, and they perceive changes in conditions only gradually. This is great if the forecasted variable is in fact stationary, or at least if changes are slow compared to the perception time. On the other hand, for a fast-evolving situation like COVID19, delay can be fatal – literally.
For anything that is in fact changing (or that people perceive to be changing), it makes sense to project changes into the future with some kind of model. For a tiny fraction of reality, that might mean a sophisticated model: multiple regression, machine learning, or some kind of calibrated causal model, for example. However, most things are not subject to that kind of sophisticated scrutiny. Instead, expectations are likely to be formed by some kind of simple extrapolation of past trends into the future.
In some cases, things that are seemingly modeled in a sophisticated way may wind up looking a lot like extrapolation, due to human nature. The forecasters form a priori expectations of what “good” model projections look like, based on fairly naive adaptive-extrapolative expectations and social processes, and use those expectations to filter the results that are deemed acceptable. This makes the sophisticated results look a lot like extrapolation. However, the better the model, the harder it is for this to happen.
The goal, by the way, is generally not to use trend-like functions to make a forecast. Extrapolation may be perfectly reasonable in some cases, particularly where you don’t care too much about the outcome. But generally, you’re better off with a more sophisticated model – the whole point of SD and other methods is to address the feedback and nonlinearities that make extrapolation and other simpleminded methods go wrong. On the other hand, simple extrapolation may be great for creating a naive or null forecast to use as a benchmark for comparison with better approaches.
Basics
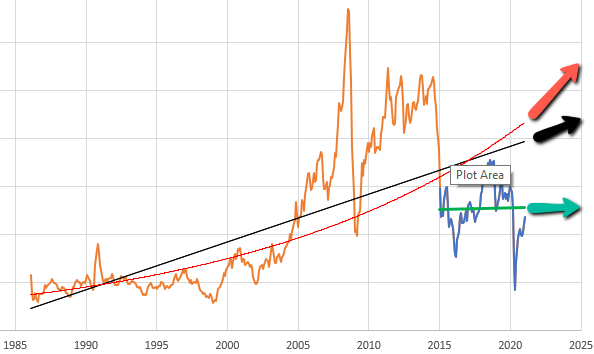
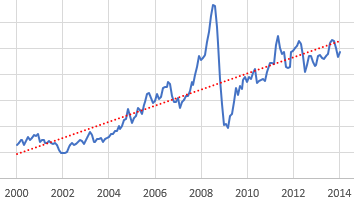
So, let’s suppose you want to model the expectations for something that people perceive to be (potentially) steadily increasing or decreasing. You can visit St. Louis FRED and find lots of economic series like this – GDP, prices, etc. Here’s the spot price of West Texas Intermediate crude oil:
Given this data, there are immediately lots of choices. Thinking about someone today making an investment conditional on future oil prices, should they extrapolate linearly (black and green lines) or exponentially (red line)? Should they use the whole series (black and red) or just the last few years (green)? Each of these implies a different forecast for the future.
Suppose we have some ideas about the forecast horizon, desired sensitivity to noise, etc. How do we actually establish a trend? One option is linear regression, which is just a formal way of eyeballing a straight line that fits some data. It works well, but has some drawbacks. First, it assigns equal weight to all the data throughout the interval, and zero weight to anything outside the interval. That may be a poor model for perceptual processes, where the most recent data has the greatest salience to the decision maker. Second, it’s computation- and storage-intensive: you have to do a lot of math, and keep track of every data point within the window of interest. That’s fine if it resides in a spreadsheet, but not if it resides in someone’s head.
Linear fit to a subset of the WTI spot price data.
The trend-like functions make an elegant simplification that addresses the drawbacks of regression. It’s based on the following observation:*
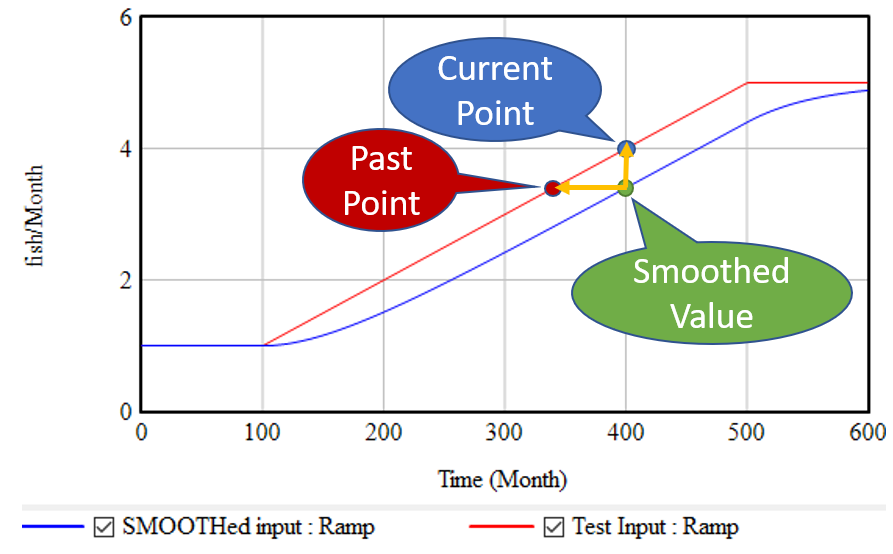
If, as above, you take a growing input (red line) and smooth it exponentially (using the SMOOTH function, or an equivalent first order goal-gap structure), you get the blue line: another ramp, that lags the input with a delay equal to the smoothing time. This means that, at month 400, we know two points: the current value of the input, and the current value of the smoothed input. But the smoothed value represents the past value of the input, in this case 60 months previous. So, we can use these two points to determine the slope of the red line:
(1) slope = (current - smoothed) / smoothing time
This is the slope in terms of input units per time. It’s often convenient to compute the fractional slope instead, expressing the growth as a fractional increase in the input per unit time:
This is what the simple TREND functions in SD software typically report. Note that it blows up if the smoothed quantity reaches 0, while the linear method (1) does not.
If we think the growth is exponential, rather than a linear ramp, we can compute the growth rate in continuous time:
(3) fractional growth rate = LN( current / smoothed ) / smoothing time
This has pros and cons. Obviously, if a quantity is really growing exponentially, it should be measured that way. But if we’re modeling how people actually think, they may extrapolate linearly when the underlying behavior is exponential, thereby greatly underestimating future growth. Note that the very idea of forecasting exponentially assumes that the values involved are positive.
Once you know the slope of the (estimated) line, you can extrapolate it into the future via a method that corresponds with the measurement:
(1b) future value = current + slope * forecast horizon
(2b) future value = current * (1 + fractional slope * forecast horizon)
(3b) future value = current * EXP( fractional growth rate * forecast horizon )
Typical FORECAST functions use (2b).
*There’s a nice discussion of this in Appendix L of Industrial Dynamics, around figure L-3.
Refinements
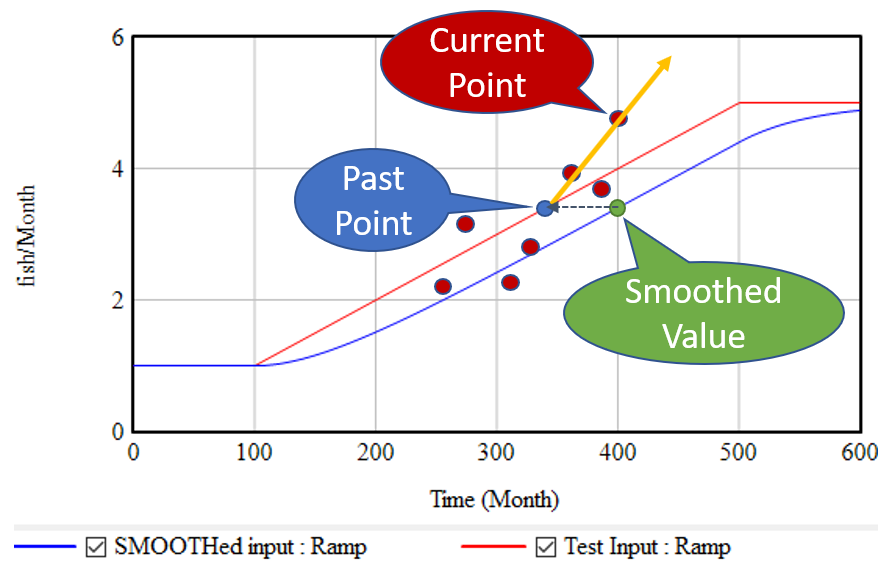
The strategy above has the virtue of great simplicity: you only need to keep track of one extra stock, and the computation needed to extrapolate is minimal. It works great for continuous models. Unfortunately, it’s not very resistant to noise and discontinuities. Consider what happens if the input is not a smooth line, but a set of noisy points scattered around the line:
The SMOOTH function filters the data, so the past point (blue) may still be pretty close to the underlying input trend (red line). However, the extrapolation (orange line) relies only on the past point and the single current point. Any noise or discontinuity in the current point therefore can dramatically influence the slope estimate and future projections. This is not good.
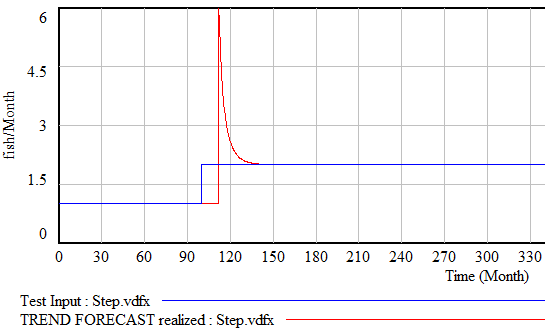
Similar perverse behaviors happen if the input is a pulse or step function. For example:
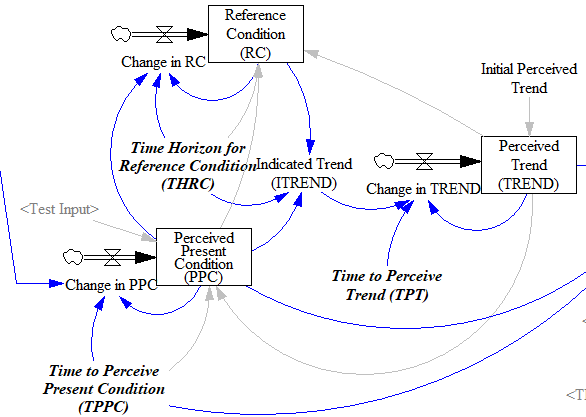
Fortunately, simple functions can be saved. In Expectation Formation in Behavioral Simulation Models, John Sterman describes an alternative third-order TREND function that improves robustness and realism. The same structure can be found in the excellent discussion of expectations in Business Dynamics, Chapter 16.
I’ll leave the details to the article, but the basic procedure is:
Recognize that the input is not perceived instantaneously, but only after some delay (represented by smoothing). This might capture the fact that formal accounting procedures only report results with a lag, or that you only see the price of cheese at the supermarket intermittently.
Track a historic point (the Reference Condition), by smoothing, as in the simpler methods.
Measure the Indicated Trend as the fractional slope between the Perceived Present Condition and the Reference Condition.
Smooth the Indicated Trend again to form the final Perceived Trend. The smoothing prevents abrupt changes in the indicated trend from causing dramatic overshoots or undershoots in the trend estimate and extrapolations that use it.
There’s an intermediate case that’s actually what I’m most likely to reach for when I need something like this: second-order smoothing. There are actually several very similar approaches (see double exponential smoothing for example) in the statistical literature. You have to be a little cautious, because these are often expressed in discrete time and therefore require a little thought to adapt to continuous time and/or unequal data intervals.
The version I use does the following:
(4) smoothed input = SMOOTH( input, smoothing time )
(5) linear trend = (input-smoothed input) / smoothing time
(6) smoothed trend = SMOOTH( linear trend, trend smoothing time )
(7) forecast = smoothed input + smoothed trend*(smoothing time + forecast horizon)
This provides most of what you want in a simple extrapolation method. It largely ignores a PULSE disturbance. Overshoot is mild when presented with a STEP input (as long as the smoothing times are long enough). It largely rejects noise, but still tracks a real RAMP accurately.
Back to regression
SD models typically avoid linear regression, for a reasons that are partly legitimate (as mentioned above). But it’s also partly cultural, as a reaction to incredibly stupid regressions that passed for models in other fields around the time of SD’s inception. We shouldn’t throw the baby out with that bathwater.
Fortunately, while most software doesn’t make linear regression particularly accessible, it turns out to be easy to implement an online regression algorithm with stocks and flows with no storage of data vectors required. The basic insight is that the regression slope (typically denoted beta) is given by:
(8) slope = covar(x,y) / var(x)
where x is time and y is the input to be forecasted. But var() and covar() are just sums of squares and cross products. If we’re OK with having exponential weighting of the regression, favoring more recent data, we can track these as moving sums (analogous to SMOOTHs). As a further simplification, as long as the smoothing window is not changing, we can compute var(x) directly from the smoothing window, so we only need to track the mean and covariance, yielding another second-order smoothing approach.
If the real decision makers inspiring your model are actually using linear regression, this may be a useful way to implement it. The implementation can be extended to equal weighting over a finite interval if needed. I find the second-order smoothing approach more intuitive, and it performs just as well, so I tend to prefer that in most cases.
Extensions
Most of what I’ve described above is linear, i.e. it assumes linear growth or decline of the quantity of interest. For a lot of things, exponential growth will be a better representation. Equations (3) and (3b) assume that, but any of the other methods can be adapted to assume exponential behavior by operating on the logarithm of the input, and then inverting that with exp(…) to form the final output.
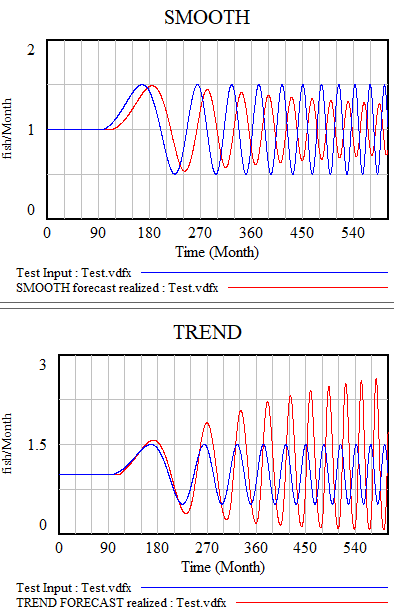
All the models described here share one weakness: cyclical inputs.
When presented with a sin wave, the simplest approach – smoothing – just bulldozes through. The higher the frequency, the less of the signal passes into the forecast. The TREND function can follow a wave if the period is longer than the smoothing time. If the dynamics are faster, it starts to miss the turning points and overshoot dramatically. The higher-order methods are better, but still not really satisfactory. The bottom line is that your projection method must use a model capable of representing the signal, and none of the methods above embodies anything about cyclical behavior.
There are lots of statistical approaches to detection of seasonality, which you can google. Many involve binning techniques, similar to those described in Appendix N of Industrial Dynamics, Self Generated Seasonal Cycles.
The model
The Vensim model, with changes (.cin) files implementing some different experiments:
Beware of the interpretation of R0, and models that plug an R0 estimated in one context into a delay structure from another.
This started out as a techy post about infection models for SD practitioners interested in epidemiology. However, it has turned into something more important for coronavirus policy.
It began with a puzzle: I re-implemented my conceptual coronavirus model for multiple regions, tuning it for Italy and Switzerland. The goal was to use it to explore border closure policies. But calibration revealed a problem: using mainstream parameters for the incubation time, recovery time, and R0 yielded lukewarm growth in infections. Retuning to fit the data yields R0=5, which is outside the range of most estimates. It also makes control extremely difficult, because you have to reduce transmission by 1-1/R0 = 80% to stop the spread.
To understand why, I decided to solve the model analytically for the steady-state growth rate in the early infection period, when there are plenty of susceptible people, so the infection rate is unconstrained by availability of victims. That analysis is reproduced in the subsequent sections. It’s of general interest as a way of thinking about growth in SD models, not only for epidemics, but also in marketing (the Bass Diffusion model is essentially an epidemic model) and in growing economies and supply chains.
First, though, I’ll skip to the punch line.
The puzzle exists because R0 is not a complete description of the structure of an epidemic. It tells you some important things about how it will unfold, like how much you have to reduce transmission to stop it, but critically, not how fast it will go. That’s because the growth rate is entangled with the incubation and recovery times, or more generally the distribution of the generation time (the time between primary and secondary infections).
This means that an R0 value estimated with one set of assumptions about generation times (e.g., using the R package R0) can’t be plugged into an SEIR model with different delay structure assumptions, without changing the trajectory of the epidemic. Specifically, the growth rate is likely to be different. The growth rate is, unfortunately, pretty important, because it influences the time at which critical thresholds like ventilator capacity will be breached.
The mathematics of this are laid out clearly by Wallinga & Lipsitch. They approach the problem from generating functions, which give up simple closed-form solutions a little more readily than my steady-state growth calculations below. For example, for the SEIR model,
R0 = (1 + r/b1)(1 + r/b2) (Eqn. 3.2)
Where r is the growth rate, b1 is the inverse of the incubation time, and b2 is the inverse of the recovery time. If you plug in r = 0.3/day, b1 = 1/(5 days), b2 = 1/(10 days), R0 = 10, which is not plausible for COVID-19. Similarly, if you plug in the frequently-seen R0=2.4 with the time constants above, you get growth at 8%/day, not the observed 30%/day.
However, in almost every aspect that matters, R 0 is flawed. Diseases can persist with R 0 < 1, while diseases with R 0 > 1 can die out. We show that the same model of malaria gives many different values of R 0, depending on the method used, with the sole common property that they have a threshold at 1. We also survey estimated values of R 0 for a variety of diseases, and examine some of the alternatives that have been proposed. If R 0 is to be used, it must be accompanied by caveats about the method of calculation, underlying model assumptions and evidence that it is actually a threshold. Otherwise, the concept is meaningless.
Is this merely a theoretical problem? I don’t think so. Here’s how things stand in some online SEIR-type simulators:
*Observed in simulator; doesn’t match steady state calculation, so some feature is unknown.
**Est. from 6.5 day mean generation time, distributed around incubation time.
***Not reported; doubling time appears to be about 6 days.
I think this is certainly a Tower of Babel situation. It seems likely that the low-order age structure in the SEIR model is problematic for accurate representation of the dynamics. But it also seems like piecemeal parameter selection understates the true uncertainty in these values. We need to know the joint distribution of R0 and the generation time distribution in order to properly represent what is going on.
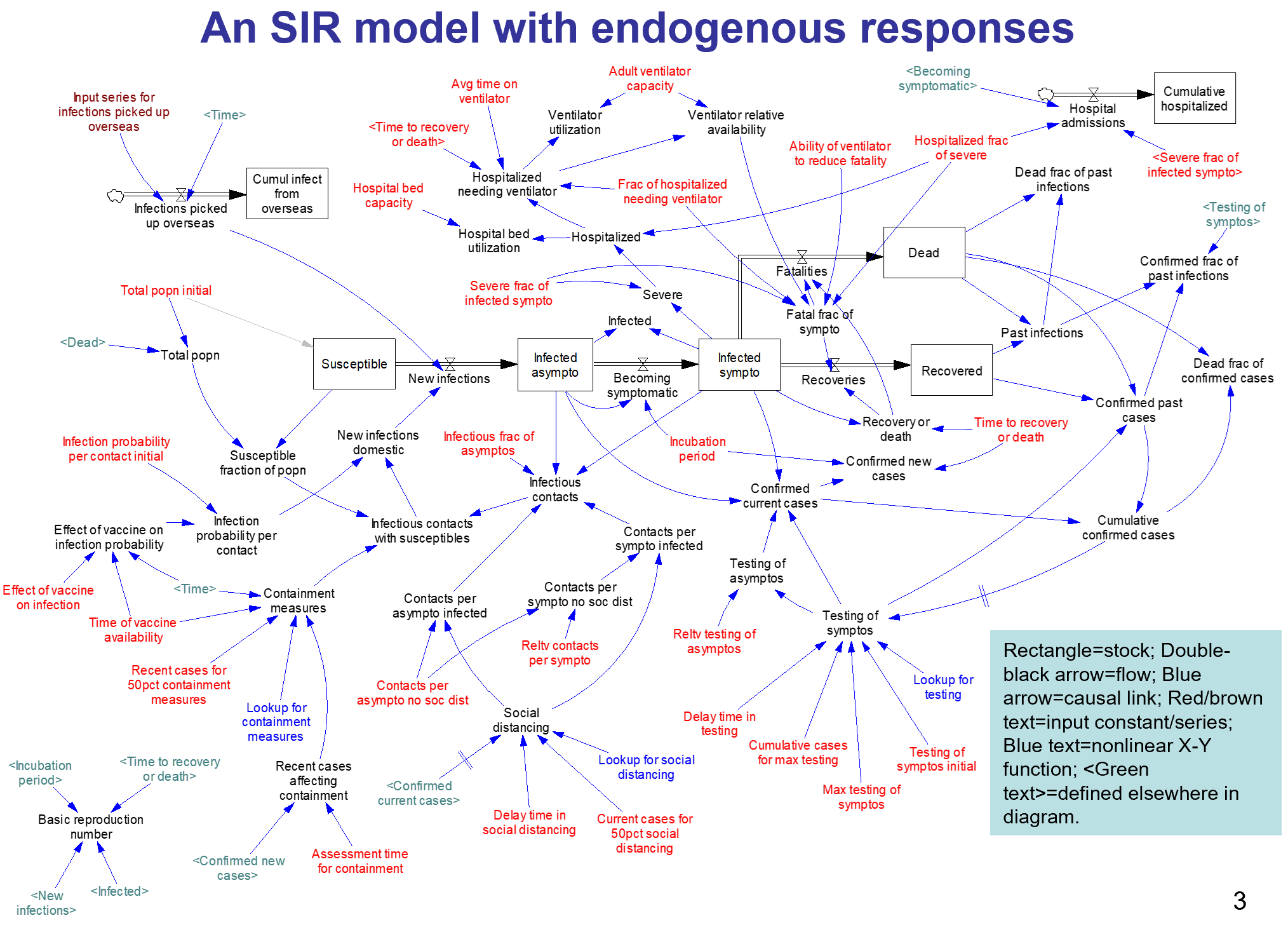
The core of the model is an SEIR chain, similar to my model. This adds some nice features, including endogenous testing and a feedback decision rule for control measures. It’s parameterized for the US.
I haven’t spent significant time with the model yet, so I can’t really comment. An alarming feature of this disease is that doublings occur on the same time scale as thinking through an iteration of a model, especially if coronavirus is not your day job. I hope to add some further thoughts when I’ve thinned my backlog a bit.
From the slide deck:
Conclusions
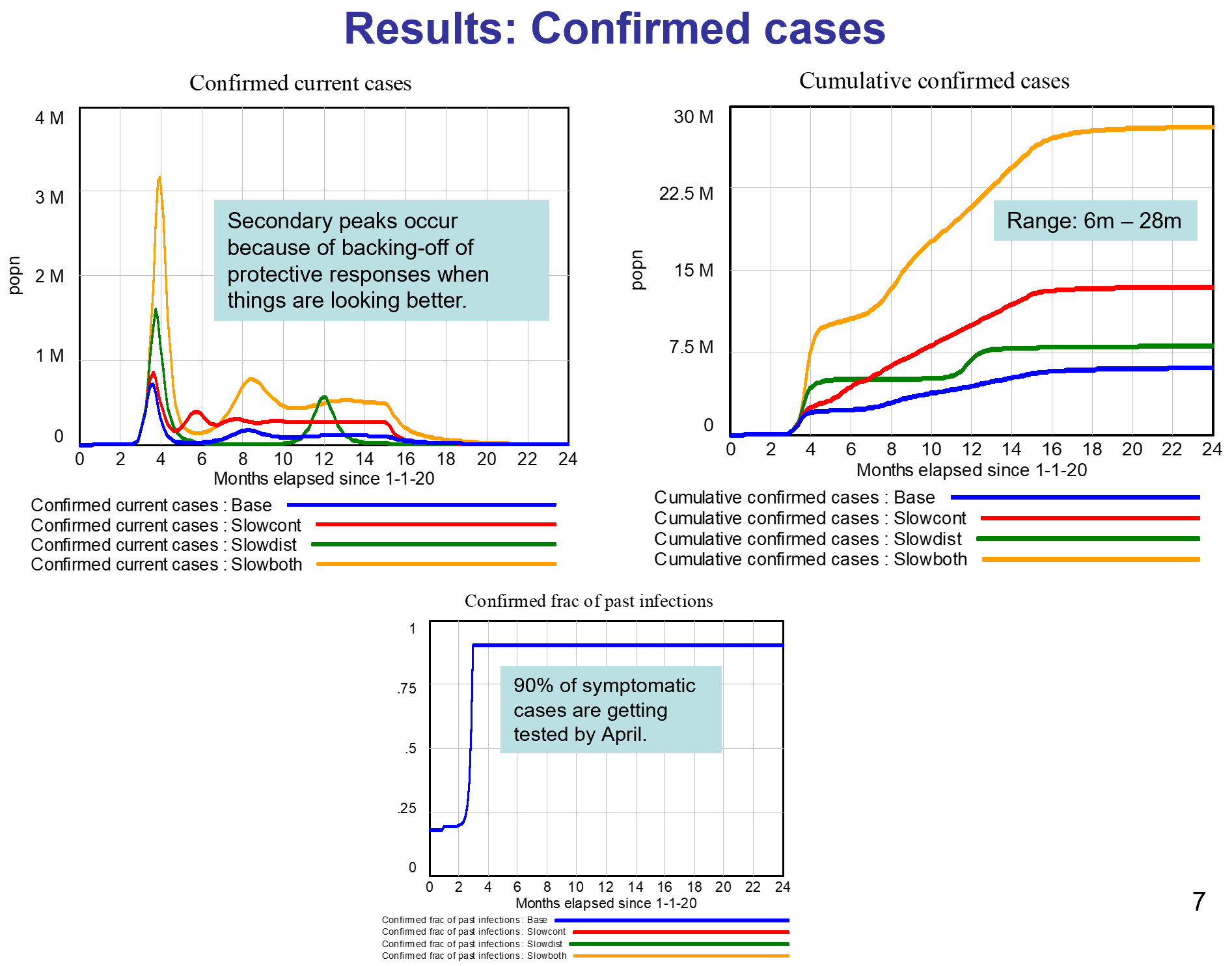
The results here come from a model with several key numerical assumptions, especially around behavioral responses. As the 4 runs illustrate, if the assumptions are modified, the overall results change over some range of possibility.
My assumptions about the behavioral responses were informed by what we been seeing recently in the US: a good response, even in regions not yet hard-hit. The message is out, and it is having an effect.
Because of the responses, and despite the absence of a vaccine, I conclude this epidemic will not infect a third or half of the population as some have predicted. Rather, we are likely to see 6m-28m cases in the US in total, resulting in 100k-500k deaths. This projection assumes a vaccine available by next April.
I also conclude that our hospital system overall has enough bed capacity to handle the peak load late April/early May; and enough ventilator capacity except during those 3 weeks in the more pessimistic Slowboth scenario. We would need 180k ventilators (rather than the assumed 120k) to avoid this shortage in the pessimistic scenario.
I have not addressed here the impact of containment measures and social distancing on the economy, including the supply of food and other necessities. This supply is important, affecting our ability to maintain strong containment and distancing.
This archive contains the Vensim model in mdl and vpmx format, a custom graph set (already loaded in the model), and some runs:
I’ve added an SIR modeling primer video to the Vensim coronavirus page, where you can download the models and the software.
This illustrates most of the foundations of the community coronavirus model. Feel free to adapt any of these tools for education or other purposes (but please respect the free Vensim PLE educational license and buy a paid copy if you’re doing commercial work).
This video explores a simple epidemic model for a community confronting coronavirus.
I built this to reflect my hometown, Bozeman MT and surrounding Gallatin County, with a population of 100,000 and no reported cases – yet. It shows the importance of an early, robust, multi-pronged approach to reducing infections. Because it’s simple, it can easily be adapted for other locations.
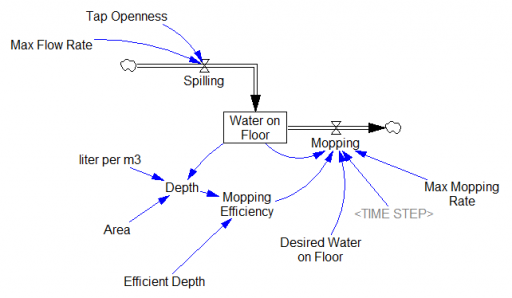
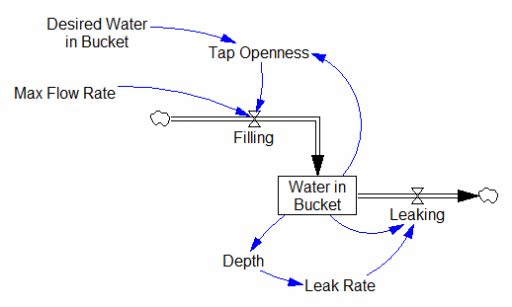
I just learned a beautiful Dutch idiom, dweilen met de kraan open. It means “mopping [the floor] with the the faucet running.” I’m not sure there’s a common English equivalent that’s so poetic, but perhaps “treating the symptoms, not the cause” is closest.
This makes a nice little model:
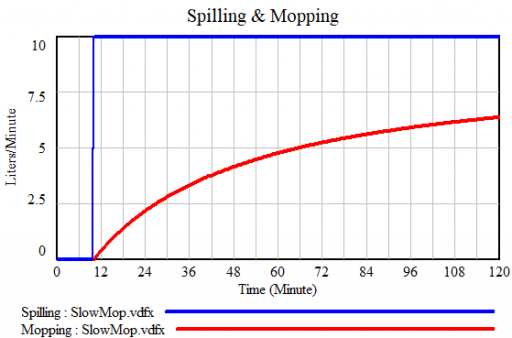
If you’re a slow mopper, you can never catch up with the tap:
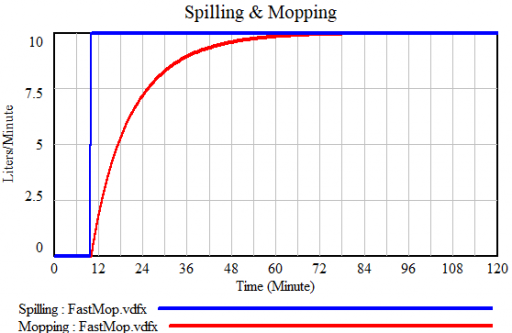
If you’re fast, you can catch up, but not reverse the process:
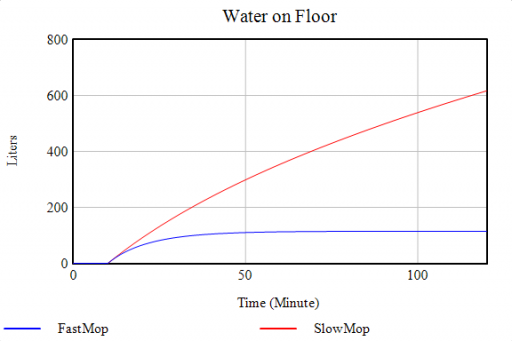
Either way, as long as you don’t turn off the tap, there will always be water on the floor:
The structure of the system above is nearly the same as filling a leaky bucket, except that the user is concerned with the inflow rather than the outflow.
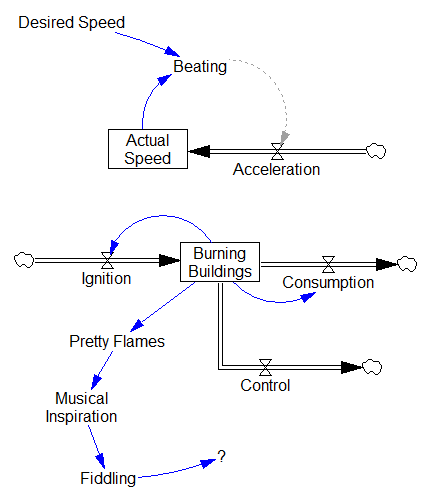
Beating a dead horse and fiddling while Rome burns
These control systems are definitely going nowhere:
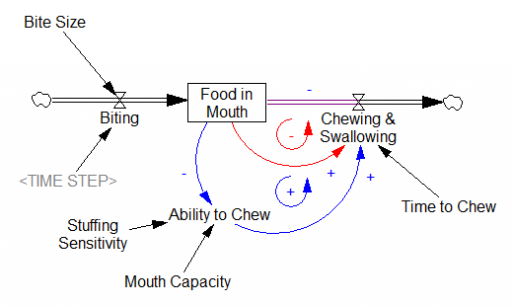
Biting off more than you can chew
This one’s fun because it only becomes an exercise in futility when you cross a nonlinear threshold.
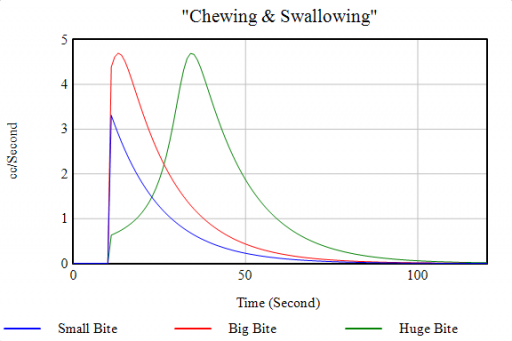
As long as you take small bites, the red loop of “normal” chewing clears the backlog of food in mouth in a reasonable time. But when you take a huge bite, you exceed the mouth’s capacity. This activates the blue positive loop, which slows chewing until the burden has been reduced somewhat. When the blue loop kicks in, the behavior mode changes (green), greatly delaying the process:
I think the futility of this endeavor is normally thought of as a question of scale. The volume of the ocean is about 1.35 trillion trillion cubic centimeters, and a thimble contains about 1 cc. But suppose you could cycle that thimble really fast? I think you still have feedback problems:
First, you have the mopping problem: as the ocean empties, the job gets harder, because you’ll be carrying water uphill … a lot (the average depth of the ocean is about 4000 meters). Second, you have the leaky bucket problem. Where are you going to put all that water? Evaporation and surface flow are inevitably going to take some back to the ocean.
A question about sigmoid functions prompted me to collect a lot of small models that I’ve used over the years.
A sigmoid function is just a function with a characteristic S shape. (OK, you have to use your imagination a bit to get the S.) These tend to arise in two different ways:
As a nonlinear response, where increasing the input initially has little effect, then considerable effect, then saturates with little effect. Neurons, and transfer functions in neural networks, behave this way. Advertising is also thought to work like this: too little, and people don’t notice. Too much, and they become immune. Somewhere in the middle, they’re responsive.
Dynamically, as the behavior over time of a system with shifting dominance from growth to saturation. Examples include populations approaching carrying capacity and the Bass diffusion model.
Correspondingly, there are (at least) two modeling situations that commonly require the use of some kind of sigmoid function:
You want to represent the kind of saturating nonlinear effect described above, with some parameters to control the minimum and maximum values, the slope around the central point, and maybe symmetry features.
You want to create a simple scenario generator for some driver of your model that has logistic behavior, but you don’t want to bother with an explicit dynamic structure.
The examples in this model address both needs. They include:
I’m sure there are still a lot of alternatives I omitted. Cubic splines and Bezier curves come to mind. I’d be interested to hear of any others of interest, or just alternative parameterizations of things already here.


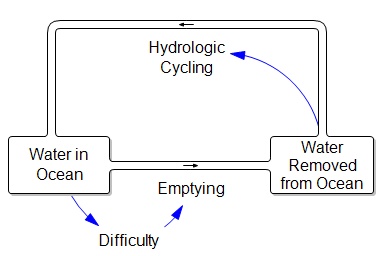
 The logical loop is still there, and the rest of the accounting is more complex, so I think it’s inevitable.
The logical loop is still there, and the rest of the accounting is more complex, so I think it’s inevitable.