There’s a lot of art to modeling, and more generally to managing complex systems. But there’s also some craft to it: simple, mechanical steps that must be followed, almost without exception. Woodworkers know that when you’re using a chisel or plane, you cut with the grain, not across it. Knowing that isn’t sufficient to make a nice-looking chair, but at least your funny-looking chair won’t have ugly tearout.
So what are the rules for classic System Dynamics? Here are a few:
- Unbalanced or missing units. It’s possible to build a correct model without units, but most people (including me) are unlikely to manage it. Even if the model is right in some sense, without units it’s still unintelligible to others.
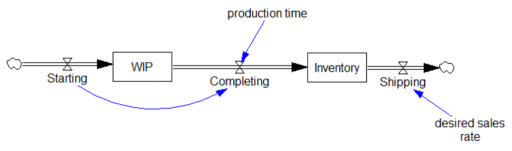
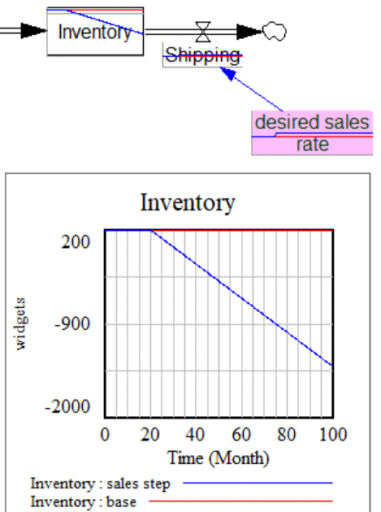
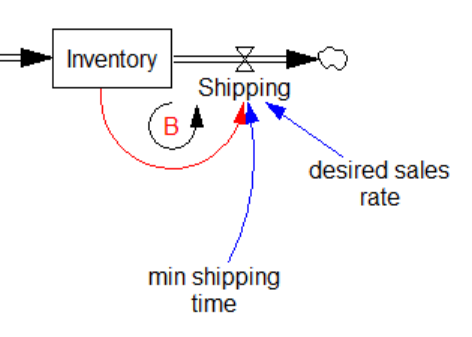
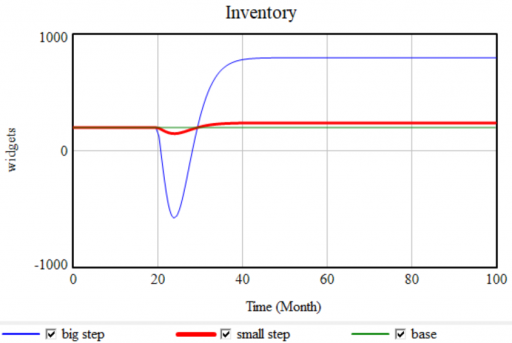
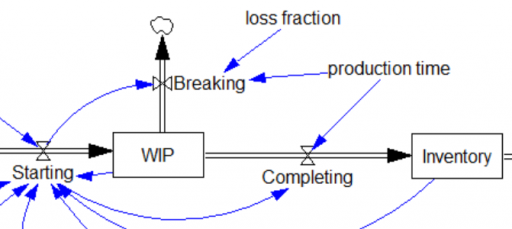
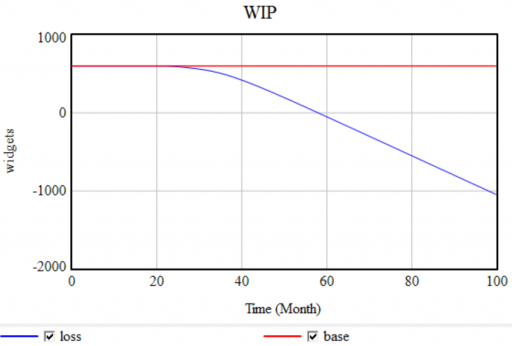
- No FONFOO. Every physical stock needs First-Order Negative Feedback On the Outflows. This means the equations ensure that the outflow goes to 0 as the stock goes to 0 – not after a while, but now and forever. This ensures conservation of stuff: no inventory -> no sales. Nonphysical stocks often require this treatment as well, unless negative values are permitted by definition.
- Embedded parameters. A colleague just found an equation in a spreadsheet model reading something like =A2*EXP(-C4/C1) + 4. The “4” was just an arbitrary fudge factor on the answer. This should never happen; anything more complex than the 1 in 1/x should always be exposed as a distinct, named variable with appropriate units.
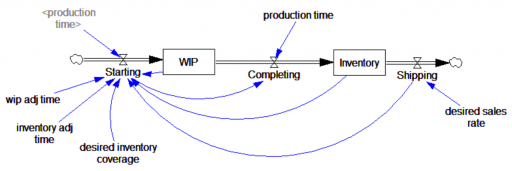
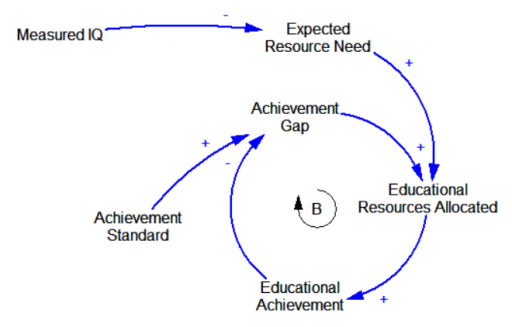
- Corollary: the embedded parameter often represents an implicit goal. For example, in inventory adjustment = (1000-inventory)/inventory adj time, the goal of 1000 units should be made explicit.
- Discrete time. Generally, your model should be independent of the TIME STEP and simulation method. Decision rules should integrate information smoothly, not at arbitrary point lags.
- Discrete logic. Sometimes I see equations that involve big cascades of logical statements: IF THEN ELSE( inventory < 100 :AND: price > 2, do x, IF THEN ELSE( inventory > 200 :AND: expected sales > inventory/desired coverage, do y, IF THEN ELSE( … Constructions like this are hard to read and hard to debug, and they often fail important reality checks. They might be appropriate in tactical cases where reality has discernible, discrete rules. But they’re seldom helpful in strategic models involving the aggregate behavior of many agents or objects.
- Overuse of delays. Every feedback loop must include a stock. This is a consequence of “time is what keeps everything from happening at once.” If there’s no integration in a loop, then feedback would run infinitely fast. Sometimes, confronted with an apparently simultaneous loop, modelers just insert a SMOOTHI or similar function that contains a stock. This may not be good enough; the stock in the loop can’t be arbitrary; it has to have real meaning.
- It’s also possible to commit the opposite sin: underuse of delays. Perceptions lag reality, and people often underestimate the extent to which this is true. Decision rules in your model should reflect this, but I think it’s more a matter of art than craft.
- Taking the cream out of the coffee. Suppose you have a stock of people, with a coflow of money used to keep track of the average wealth of people in the stock. It’s then tempting to handle a thought experiment like, “ok, what if all the rich people leave the country?” by siphoning off a greater-than-average share of the money alongside each departing person. This violates the assumption that a stock is the complete representation of system state. What if, for example, the rich people already left, so that the remainder are uniformly poor? If the distinction is important, you simply must disaggregate the people into classes.
Like all rules, these are made to be broken, but exceptions are rare, and require that you really know what you’re doing. They are important because they ensure compliance with Reality Checks that should remain inviolate for strong reasons. If your population model isn’t conserving people, you have a problem.
Incidentally, at least half of these are mentioned in Appendix O of Industrial Dynamics, “Beginners’ Difficulties.” However, these are not just tricks for beginners: everyone can benefit from keeping them in mind, just as professional pilots rely on checklists.
I’m eager to hear your thoughts in the comments. What rules did I miss?
See also:
How to critique a model (and build a model that withstands critique)
* Update: edited slightly for parallelism of the headers.