When Hostess went bankrupt in 2012, there was lots of speculation about the fate of the last Twinkie, perhaps languishing on the dusty shelves of a gas station convenience store somewhere in New Mexico. Would that take ten days, ten weeks, ten years?
So, what does this have to do with system dynamics? It calls to mind the problem of modeling the inventory stockout constraint on sales. This problem dates back to Industrial Dynamics (see the variable NIR driving SSR and the discussion around figs. 15-5 and 15-7).
If there’s just one product in one inventory (i.e. one store), and visibility doesn’t matter, the constraint is pretty simple. As long as there’s one item left, sales or shipments can proceed. The constraint then is:
(1) selling = MIN(desired selling, inventory/time step)
In other words, the most that can be sold in one time step is the amount of inventory that’s actually on hand. Generically, the constraint looks like this:
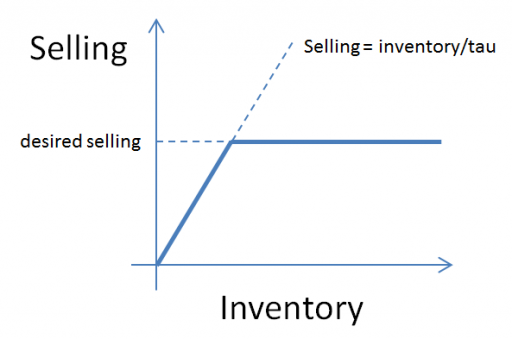
Here, tau is a time constant, that could be equal to time step (DT), as above, or could be generalized to some longer interval reflecting handling and other lags.
This can be further generalized to some kind of continuous function, like:
(2) selling = desired selling * f( inventory )
where f() is often a lookup table. This can be a bit tricky, because you have to ensure that f() goes to zero fast enough to obey the inventory/DT constraint above.
But what if you have lots of products and/or lots of inventory points, perhaps with different normal turnover rates? How does this aggregate? I built the following toy model to find out. You could easily do this in Vensim with arrays, but I found that it was ideally suited to Ventity.
Here’s the setup:
First, there’s a collection of Store entities, each with an inventory. Initial inventory is random, with a Poisson distribution, which ensures integer twinkies. Customer arrivals also have a Poisson distribution, and (optionally), the mean arrival rate varies by store. Selling is constrained to stock on hand via inventory/DT, and is also subject to a visibility effect – shelf stock influences the probability that a customer will buy a twinkie (realized with a Binomial distribution). The visibility effect saturates, so that there are diminishing returns to adding stock, as occurs when new stock goes to the back rows of the shelf, for example.
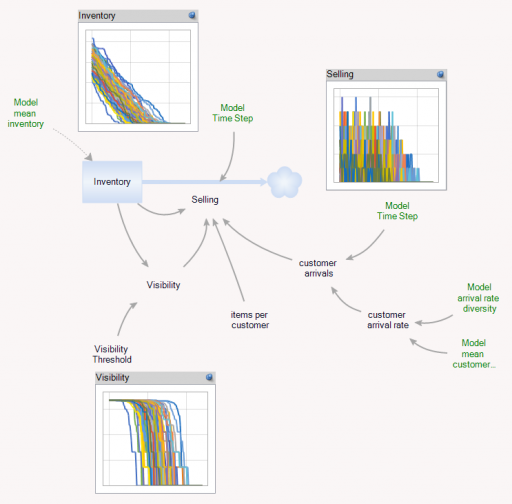
In addition, there’s an Aggregate entitytype, which is very similar to the Store, but deterministic and continuous.
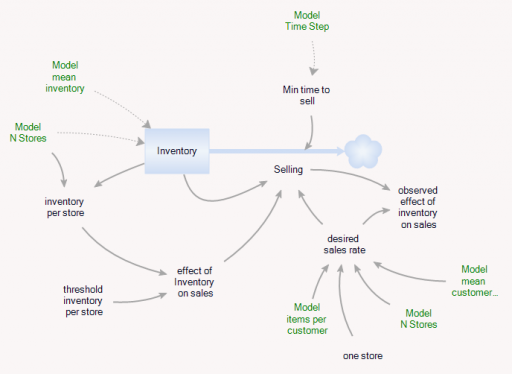
The Aggregate’s initial inventory and sales rates are set to the expected values for individual stores. Two different kinds of constraints on the inventory outflow are available: inventory/tau, and f(inventory). The sales rate simplifies to:
(3) selling = min(desired sales rate*f(inventory),Inventory/Min time to sell)
(4) min time to sell >= time step
In the Store and the Aggregate, the nonlinear effect of inventory on sales (called visibility in the store) is given by
(5) f(inventory) = 1-Exp(-Inventory/Threshold)
However, the aggregate threshold might be different from the individual store threshold (and there’s no compelling reason for the aggregate f() to match the individual f(); it was just a simple way to start).
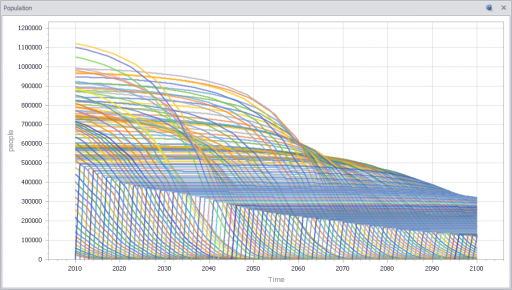
In the Store[] collection, I calculate aggregates of the individual stores, which look quite continuous, even though the population is only 100. (There are over 100,000 gas stations in the US.)
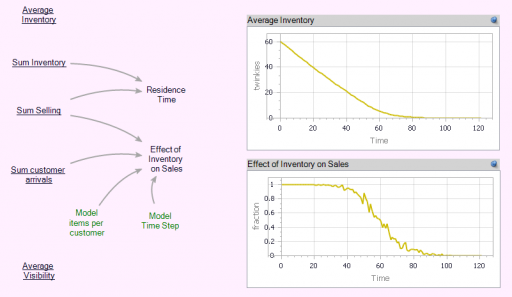
Notice that the time series behavior of the effect of inventory on sales is sigmoid.
Now we can compare individual and aggregate behavior:
Inventory
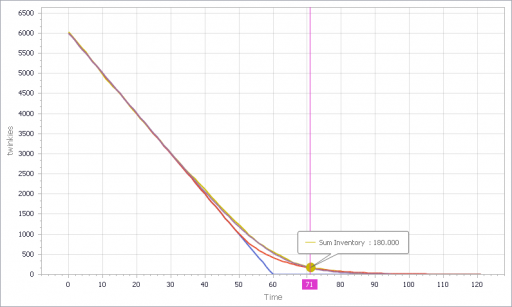
Selling
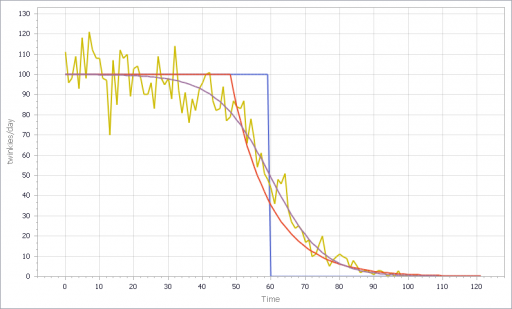
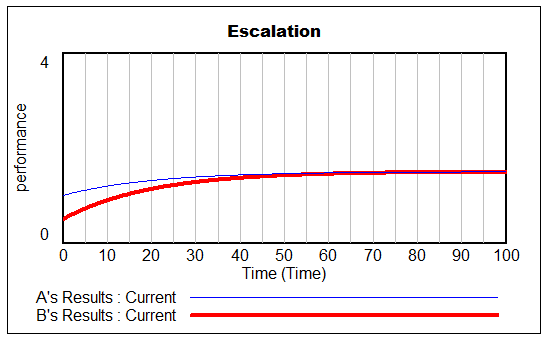
The noisy yellow line is the sum of the individual Stores. The blue line arises from imposing a hard cutoff, equation (1) above. This is like assuming that all stores are equal, and inventory doesn’t affect sales, until it’s gone. Clearly it’s not a great fit, though it might be an adequate shortcut where inventory dynamics are not really the focus of a model.
The red line also imposes an inventory/tau constraint, but the time constant (tau) is much longer than the time step, at 8 days (time step = 1 day). Finally, the purple sigmoid line arises from imposing the nonlinear f(inventory) constraint. It’s quite a good fit, but the threshold for the aggregate must be about twice as big as for the individual Stores.
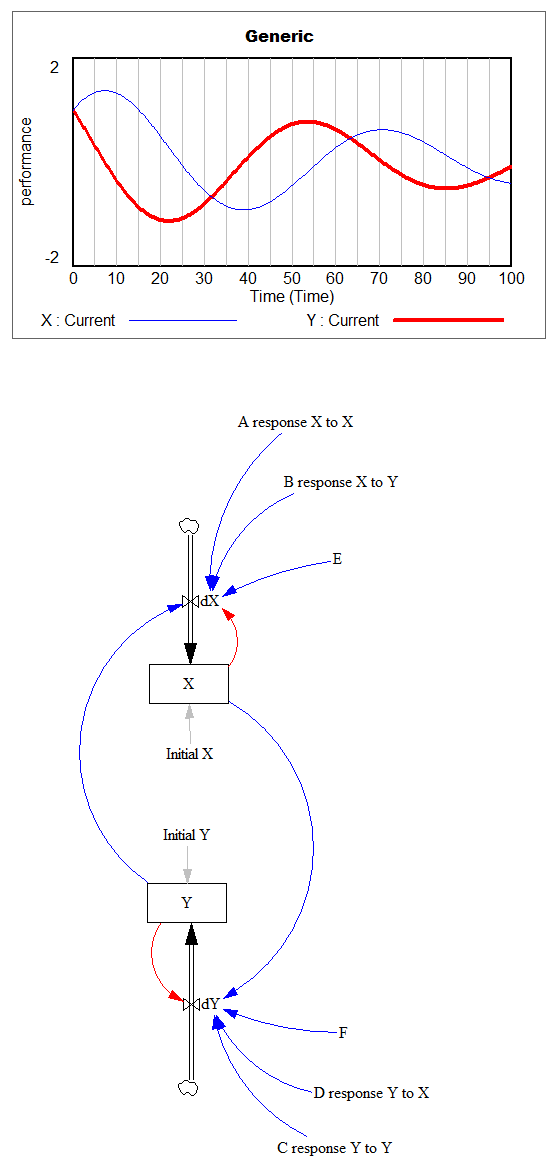
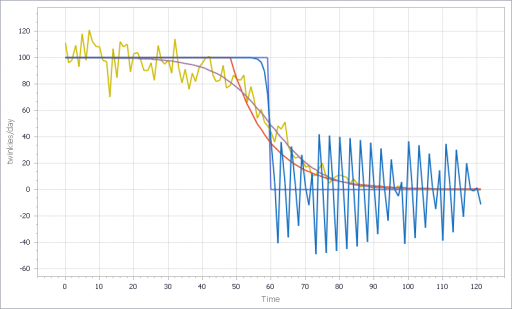
However, if you parameterize f() poorly, and omit the inventory/tau constraint, you get what appear to be chaotic oscillations – cool, but obviously unphysical:
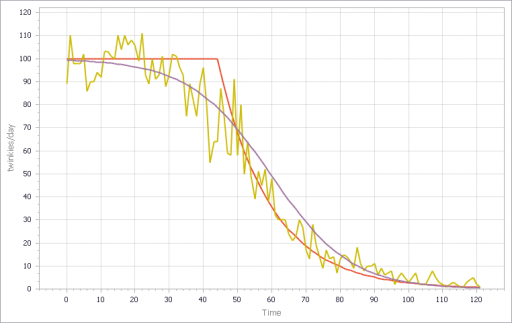
If, in addition, you add diversity in Store’s customer arrival rates, you get a longer tail on inventory. That last Twinkie is likely to be in a low-traffic outlet. This makes it a little tougher to fit all parts of the curve:
I think there are some interesting questions here, that would make a great paper for the SD conference:
- (Under what conditions) can you derive the functional form of the aggregate constraint from the properties of the individual Stores?
- When do the deficiencies of shortcut approaches, that may lack smooth derivatives, matter in aggregate models like Industrial dynamics?
- What are the practical implications for marketing models?
- What can you infer about inventory levels from aggregate data alone?
- Is that really chaos?
Have at it!
The Ventity model: LastTwinkie1.zip