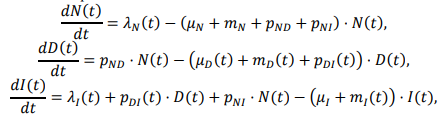I am a little encouraged to see that the very top item on Trump’s first 100 day todo list is term limits:
* FIRST, propose a Constitutional Amendment to impose term limits on all members of Congress;
Certainly the defects in our electoral and campaign finance system are among the most urgent issues we face.
Assuming other Republicans could be brought on board (which sounds unlikely), would term limits help? I didn’t have a good feel for the implications, so I built a model to clarify my thinking.
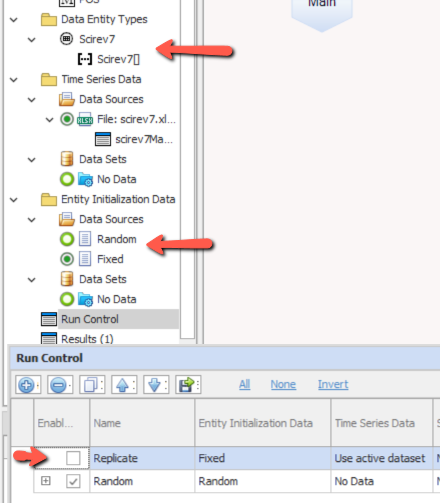
I used our new tool, Ventity, because I thought I might want to extend this to multiple voting districts, and because it makes it easy to run several scenarios with one click.
Here’s the setup:
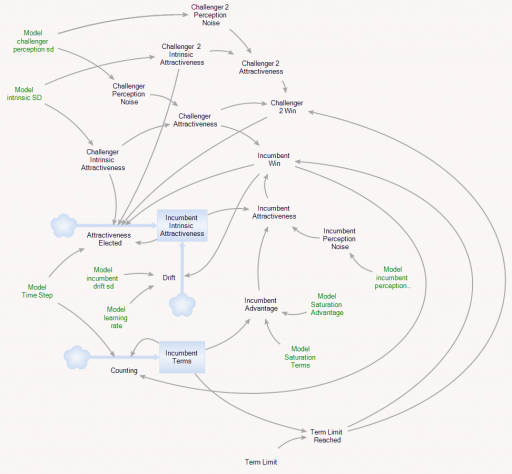
The model runs over a long series of 4000 election cycles. I could just as easily run 40 experiments of 100 cycles or some other combination that yielded a similar sample size, because the behavior is ergodic on any time scale that’s substantially longer than the maximum number of terms typically served.
Each election pits two politicians against one another. Normally, an incumbent faces a challenger. But if the incumbent is term-limited, two challengers face each other.
The electorate assesses the opponents and picks a winner. For challengers, there are two components to voters’ assessment of attractiveness:
- Intrinsic performance: how well the politician will actually represent voter interests. (This is a tricky concept, because voters may want things that aren’t really in their own best interest.) The model generates challengers with random intrinsic attractiveness, with a standard deviation of 10%.
- Noise: random disturbances that confuse voter perceptions of true performance, also with a standard deviation of 10% (i.e. it’s hard to tell who’s really good).
Once elected, incumbents have some additional features:
- The assessment of attractiveness is influenced by an additional term, representing incumbents’ advantages in electability that arise from things that have no intrinsic benefit to voters. For example, incumbents can more easily attract funding and press.
- Incumbent intrinsic attractiveness can drift. The drift has a random component (i.e. a random walk), with a standard deviation of 5% per term, reflecting changing demographics, technology, etc. There’s also a deterministic drift, which can either be positive (politicians learn to perform better with experience) or negative (power corrupts, or politicians lose touch with voters), defaulting to zero.
- The random variation influencing voter perceptions is smaller (5%) because it’s easier to observe what incumbents actually do.
There’s always a term limit of some duration active, reflecting life expectancy, but the term limit can be made much shorter.
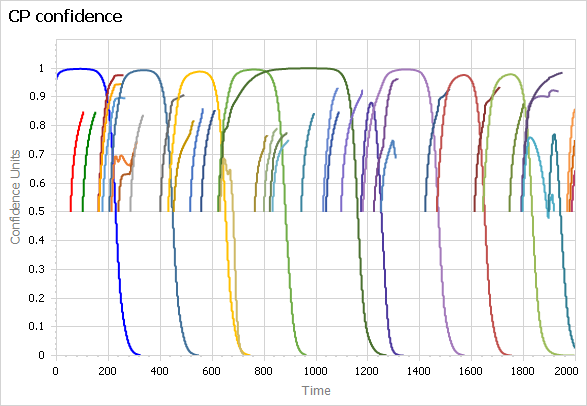
Here’s how it behaves with a 5-term limit:
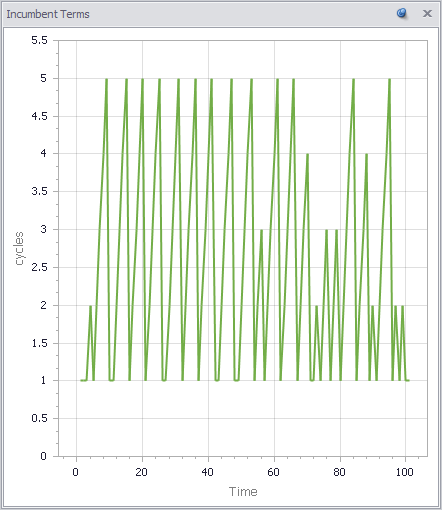
Politicians frequently serve out their 5-term limit, but occasionally are ousted early. Over that period, their intrinsic performance varies a lot:
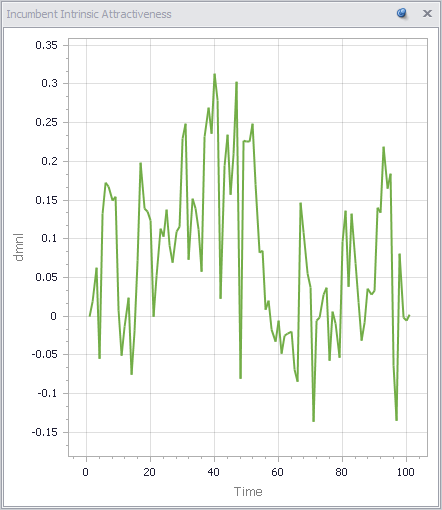
Since the mean challenger has 0 intrinsic attractiveness, politicians outperform the average frequently, but far from universally. Underperforming politicians are often reelected.
Over a long time horizon (or similarly, many districts), you can see how average performance varies with term limits:
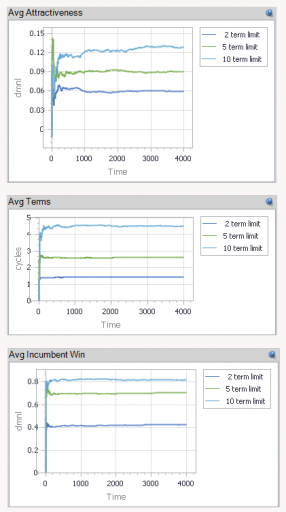
With no learning, as above, term limits degrade performance a lot (top panel). With a 2-term limit, the margin above random selection is about 6%, whereas it’s twice as great (>12%) with a 10-term limit. This is interesting, because it means that the retention of high-performing politicians improves performance a lot, even if politicians learn nothing from experience.
This advantage holds (but shrinks) even if you double the perception noise in the selection process. So, what does it take to justify term limits? In my experiments so far, politician performance has to degrade with experience (negative learning, corruption or losing touch). Breakeven (2-term limits perform the same as 10-term limits) occurs at -3% to -4% performance change per term.
But in such cases, it’s not really the term limits that are doing the work. When politician performance degrades rapidly with time, voters throw them out. Noise may delay the inevitable, but in my scenario, the average politician serves only 3 terms out of a limit of 10. Reducing the term limit to 1 or 2 does relatively little to change performance.
Upon reflection, I think the model is missing a key feature: winner-takes-all, redistricting and party rules that create safe havens for incompetent incumbents. In a district that’s split 50-50 between brown and yellow, an incompetent brown is easily displaced by a yellow challenger (or vice versa). But if the split is lopsided, it would be rare for a competent yellow challenger to emerge to replace the incompetent yellow incumbent. In such cases, term limits would help somewhat.
I can simulate this by making the advantage of incumbency bigger (raising the saturation advantage parameter):
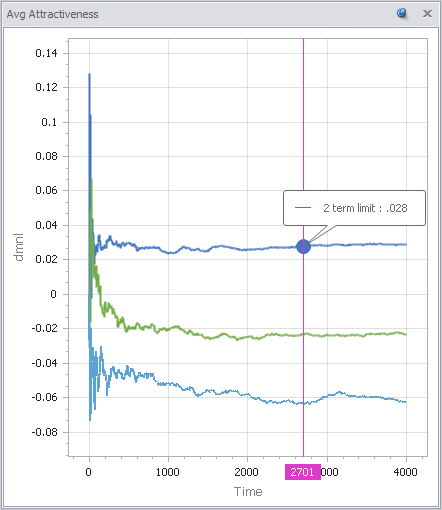
However, long terms are a symptom of the problem, not the root cause. Therefore it probably necessary in addition to address redistricting, campaign finance, voter participation and education, and other aspects of the electoral process that give rise to the problem in the first place. I’d argue that this is the single greatest contribution Trump could make.
You can play with the model yourself using the Ventity beta/trial and this model archive:
termlimits4.zip