Don't just do something, stand there! Reflections on the counterintuitive behavior of complex systems, seen through the eyes of System Dynamics, Systems Thinking and simulation.
I’ve long wanted to translate the Sterman-Wittenberg model of Kuhnian paradigm revolutions to Ventity. The original was in Dynamo, and I translated that to Vensim, but neither is really satisfactory, because both require provisioning array space for new paradigms statically, before it’s needed. This means simulating lots of useless 0s, and even worse, looking at them in the output.
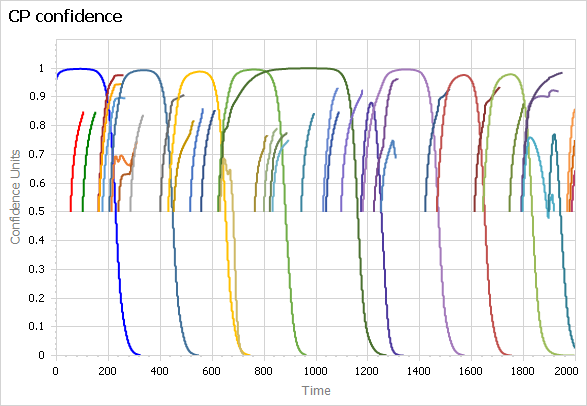
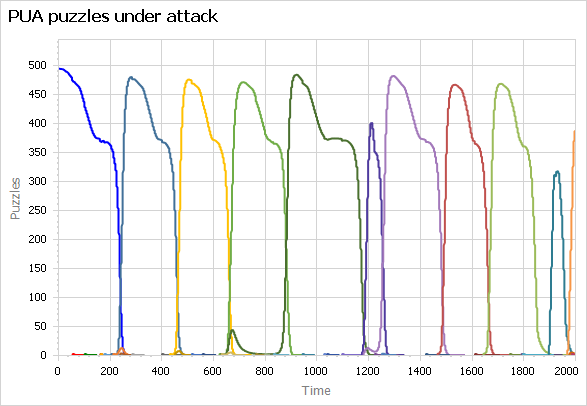
The model is about the lifecycle of scientific paradigms, so a central feature is the occasional introduction and evolution of new paradigms, which eventually accumulate enough anomalies to erode confidence, making them vulnerable to the next great idea. So ideally, you’d like to introduce new paradigms dynamically and delete them when they no longer have many adherents. Dynamic creation and deletion of entities is of course a core feature of Ventity – it’s the tool this model has been waiting for all those years.
I finally got around to translating my Vensim version to Ventity recently. It works beautifully:
Above, paradigm confidence, showing eight dominant paradigms as well as many smaller paradigms that never rise to dominance. They disappear when they run out of adherents. Below, puzzles under attack for the same paradigms.
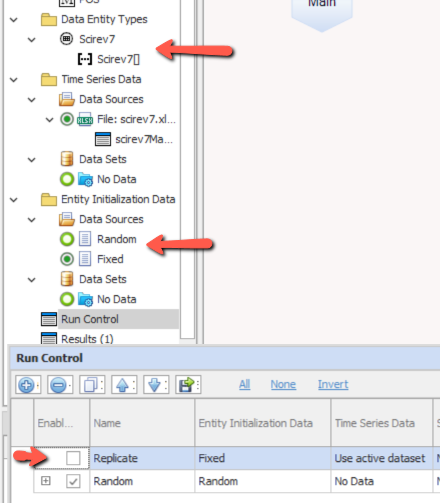
A minor note on use: the Run Config includes two setups: “replicate” and “random”. The “replicate” setup, which is inactive by default, launches paradigms at fixed times given by initialization data from a run of the Vensim version. This makes it possible to compare the simulations without divergence from randomness. However, the randomized run will normally be the more interesting way to work with this model.
The model (requires Ventity, which has a free trial license):
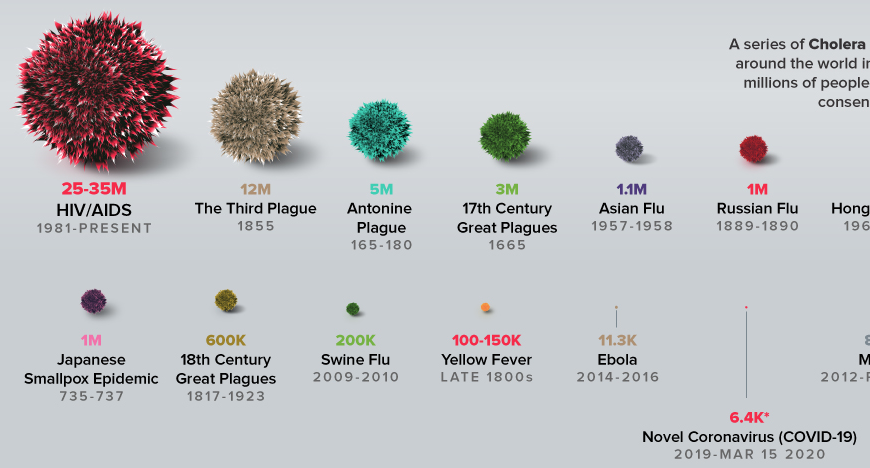
The ‘net is awash with questionable coronavirus memes. The most egregiously flawed offender I’ve seen is this one from visualcapitalist:
It’s interesting data, but the visualization really fails to put COVID19 in a proper perspective.
Exponential Growth
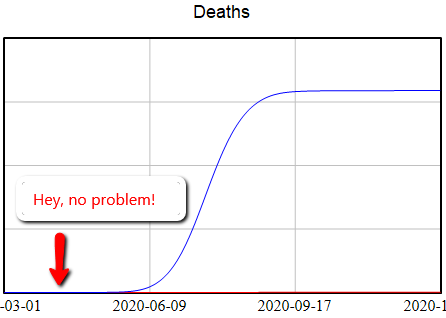
The biggest problem is obvious: the bottom of the curve is nothing like the peak for a quantity that grows exponentially.
Comparing the current death toll from COVID19, a few months old, to the final values from other epidemics over years to decades, is just spectacularly misleading. It beggars belief that anyone could produce such a comparison.
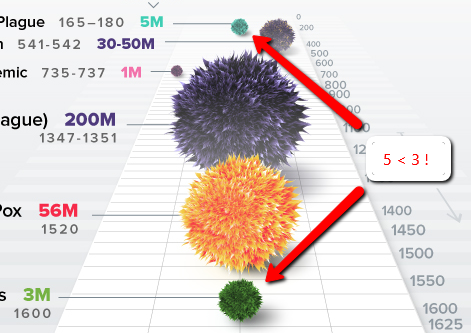
Perspective
Speaking of perspective, charts like this are rarely a good idea. This one gives the impression that 5M < 3M:
Reliance on our brains to map 2D to 3D is even more problematic when you consider the next problem.
2D or 3D?
Measuring the fur-blob sizes shows that the mapping of the data to the blobs is two-dimensional: the area of the blob on the page represents the magnitude. But the blobs are clearly rendered in 3D. That means the visual impression of the relationship between the Black Death (200M) and Japanese Smallpox (1M) is off by a factor of 15. The distortion is even more spectacular for COVID19.
You either have to go all the way with 3D, in which case COVID19 looks bigger, even with the other distortions unaddressed, or you need to make a less-sexy but more-informative flat 2D chart.
Stocks vs. Flows
The fourth problem here is that the chart neglects time. The disruption from an epidemic is not simply a matter of its cumulative death toll. The time distribution also matters: a large impact concentrated in a brief time frame has much greater ripple effects, as we are now experiencing.
This video explores a simple epidemic model for a community confronting coronavirus.
I built this to reflect my hometown, Bozeman MT and surrounding Gallatin County, with a population of 100,000 and no reported cases – yet. It shows the importance of an early, robust, multi-pronged approach to reducing infections. Because it’s simple, it can easily be adapted for other locations.
A question about sigmoid functions prompted me to collect a lot of small models that I’ve used over the years.
A sigmoid function is just a function with a characteristic S shape. (OK, you have to use your imagination a bit to get the S.) These tend to arise in two different ways:
As a nonlinear response, where increasing the input initially has little effect, then considerable effect, then saturates with little effect. Neurons, and transfer functions in neural networks, behave this way. Advertising is also thought to work like this: too little, and people don’t notice. Too much, and they become immune. Somewhere in the middle, they’re responsive.
Dynamically, as the behavior over time of a system with shifting dominance from growth to saturation. Examples include populations approaching carrying capacity and the Bass diffusion model.
Correspondingly, there are (at least) two modeling situations that commonly require the use of some kind of sigmoid function:
You want to represent the kind of saturating nonlinear effect described above, with some parameters to control the minimum and maximum values, the slope around the central point, and maybe symmetry features.
You want to create a simple scenario generator for some driver of your model that has logistic behavior, but you don’t want to bother with an explicit dynamic structure.
The examples in this model address both needs. They include:
I’m sure there are still a lot of alternatives I omitted. Cubic splines and Bezier curves come to mind. I’d be interested to hear of any others of interest, or just alternative parameterizations of things already here.
I’ve been working on a vehicle fleet model, re-implementing a spreadsheet in Ventity, using dynamic cohorts.
The vehicle lifetime in the spreadsheet is 11 years, and it’s discrete. This means that every vehicle retires precisely 11 years after it’s put into service. This raised a red flag for me, because it represents a rather short vehicle lifetime. I know from work in other jurisdictions that the average life of a vehicle is more like 16-18 years typically (and getting longer as quality improves).
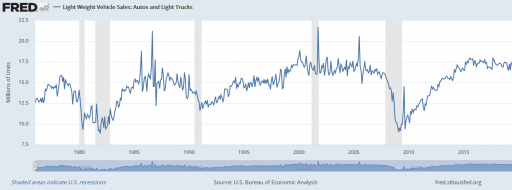
So, where does the 11 year figure come from? We’re not sure. Other published data for the region indicates an average vehicle age of 8.5 years, so it’s not that. A Ventana colleague pointed out that it might be a steady-state estimate from combining vehicle fleet data with new vehicle sales data:
Given the data (red), assume that the vehicle stock is in equilibrium (inflow=outflow). Then it follows from Little’s Law that the average lifetime of vehicles must be 11 years. Little’s Law works regardless of the delay distribution, i.e. regardless of the delay order, but if you were formulating the fleet as a first-order system, that’s precisely how you’d write the outflow equation: outflow = fleet/lifetime, with lifetime=11 years.
… the long-term average number L of customers in a stationary system is equal to the long-term average effective arrival rate λ multiplied by the average time W that a customer spends in the system. – Wikipedia
However, there’s a danger here. The system might not be in equilibrium. Then both the assumption of inflow=0utflow and the stationarity required in Little’s Law. Vehicle sales are, unfortunately, rather volatile, particularly around events like the 2008 recession:
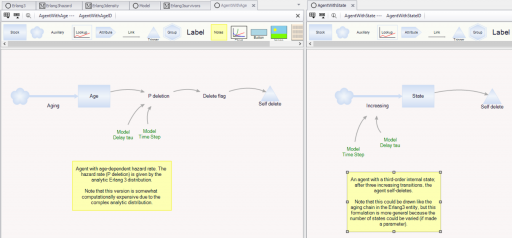
It’s tempting to use the average age of vehicles as another data point, but that turns out to be a bad idea. The average age of vehicles is sensitive to both variations in the inflow and the assumed distribution of the discard process. The following Ventity model illustrates this problem, using some of the same machinery as last week’s Erlang model.
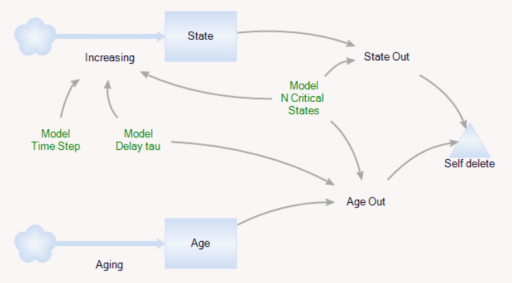
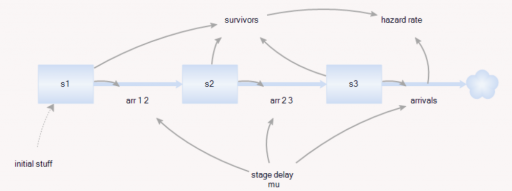
As before, there’s a population of entities (agents). Each has a cascade of N internal states, represented by a stock counter, and an age that increases continuously. An entity deletes itself when it’s too old, or its state count is too high.
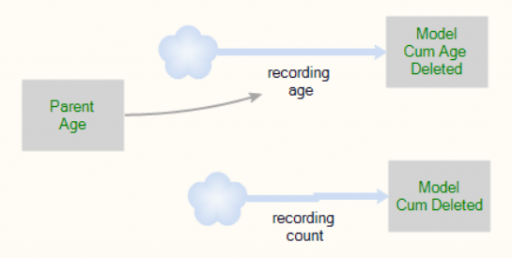
For accounting purposes, when an entity “dies” it records the event by incrementing counter stocks in the Model entity:
In this way, we can keep track of how old the average entity was at the time it deleted itself. This should be the average residence time in Little’s Law. We can also track the average age of existing entities, to see whether it’s the same.
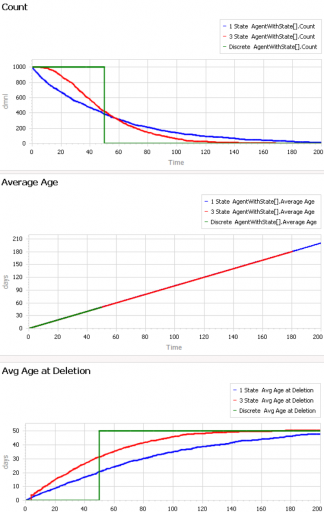
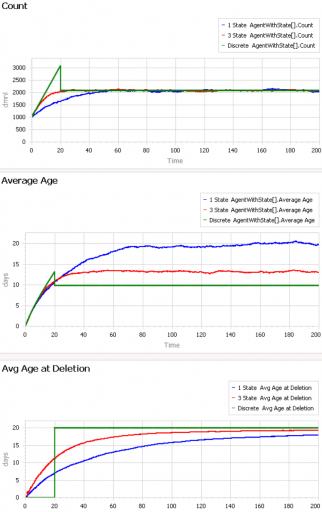
First, consider a very simple, very nonstationary special case, in which there’s no flow of entity turnover. There’s only an initial population of entities of age 0, who gradually leave the system. Here are three variants of that experiment:
Set Model.Delay tau = 50 and Model.Flow Start Time = 1000 to replicate this experiment.
The blue line is the stochastic population analog of the classic first-order delay. The probability of a given entity departing is constant over time, as for radioactive decay. Therefore we get exponential decay, with count = N0*exp(-time/Delay tau). The red line is the third-order equivalent, yielding an Erlang 3 distribution. The green line is the pipeline delay equivalent, in which all entities self-delete at a specified age, rather than with a random distribution. Therefore the population steps from 1000 to 0 at time 50.
The two lower panels compare the average age of surviving entities (middle) to the average age at which entities self-delete (bottom). At bottom, you can see that all variants eventually converge to (roughly) the expected 50-year entity lifespan. However, each trajectory initially indicates a shorter lifespan. This is due to a form of censoring bias – at a given point in time, the longest-lived entities have not yet been observed.
The middle panel indicates how average age can mislead. In this case, age=time for all entities, and therefore the average age increases linearly, even though the expected residence time is constant.
At the opposite extreme, here’s an experiment with a constant flow of new agents, so that the system is in equilibrium after a few time constants:
Set Model.Delay tau = 20 and Model.Flow Start Time = 0 to replicate this experiment.
After the initial transient has died out (by time 20 to 60), all 3 residence times (age at deletion) converge to the expected value of 20. But notice the ages. They converge, too, but the value is dependent on the distribution. For the 1st-order system (blue), the average age does equal the average residence time of 20 years. But the pipeline system (green) has an average age that’s half that, at 10 years. This makes sense, if you think about an equilibrium population composed of a uniform mix of ages between 0 and 20 years. The 3rd-order system is in between.
This uncertain relationship between age and residence time means that we can’t use the average age of the vehicle fleet to determine the rate of vehicle turnover. That’s too bad, because age is the one statistic that’s easy to compute from a database of vehicle registrations. To know more, we have to start making inferences about the inflows and outflows – but that’s tricky if data coverage varies with time. Unfortunately, this is a number that we care about, because the residence time of vehicles in the system is an important driver of future penetration of low-carbon technologies.
This model provides some similar insights – this time in Ventity. It’s a hybrid of classic continuous SD and agent equivalents.
First, the Erlang3 entitytype compares the classic 3rd-order aging chain’s behavior to analytical equivalents, as in the Delay Sandbox. The analytic values are computed in a set of Ventity’s new macros:
Notice that the variances, which arise from Euler integration with a finite time step, are small enough to be uninteresting.
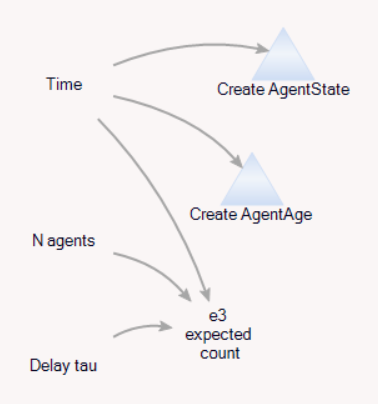
Second, the model compares the dynamics of discrete agent populations to the analytic Erlang results. To do this, the Model entity creates populations of agents at time 0, and (for comparison) computes the expected surviving population according to the Erlang distribution:
The agents live for a time, then self-delete according to two different strategies:
On the left, an agent tracks its own age, and has an age-specific probability of mortality (again, thanks to the hazard rate of the Erlang distribution). On the right, an agent has a state counter, and mortality occurs when the number of state transitions reaches 3.
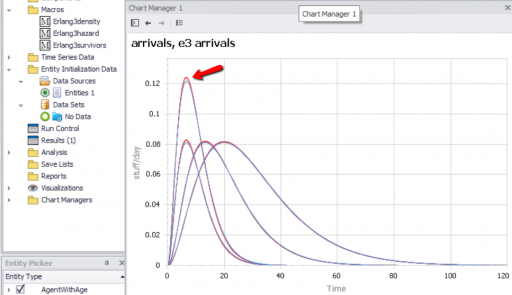
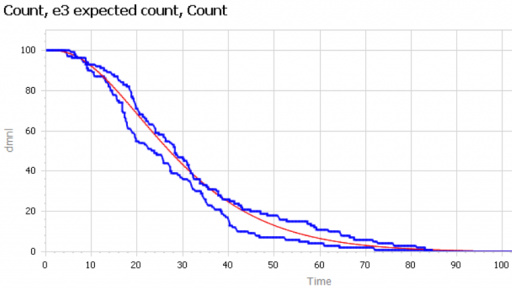
We can then compare the surviving agent populations (blue) to the Erlang expectation (red):
When the population is small (above, 100), there’s some stochastic variation around the expected result. But for larger populations, the difference is negligible.
This one little trick might prevent you from blowing up your organization.
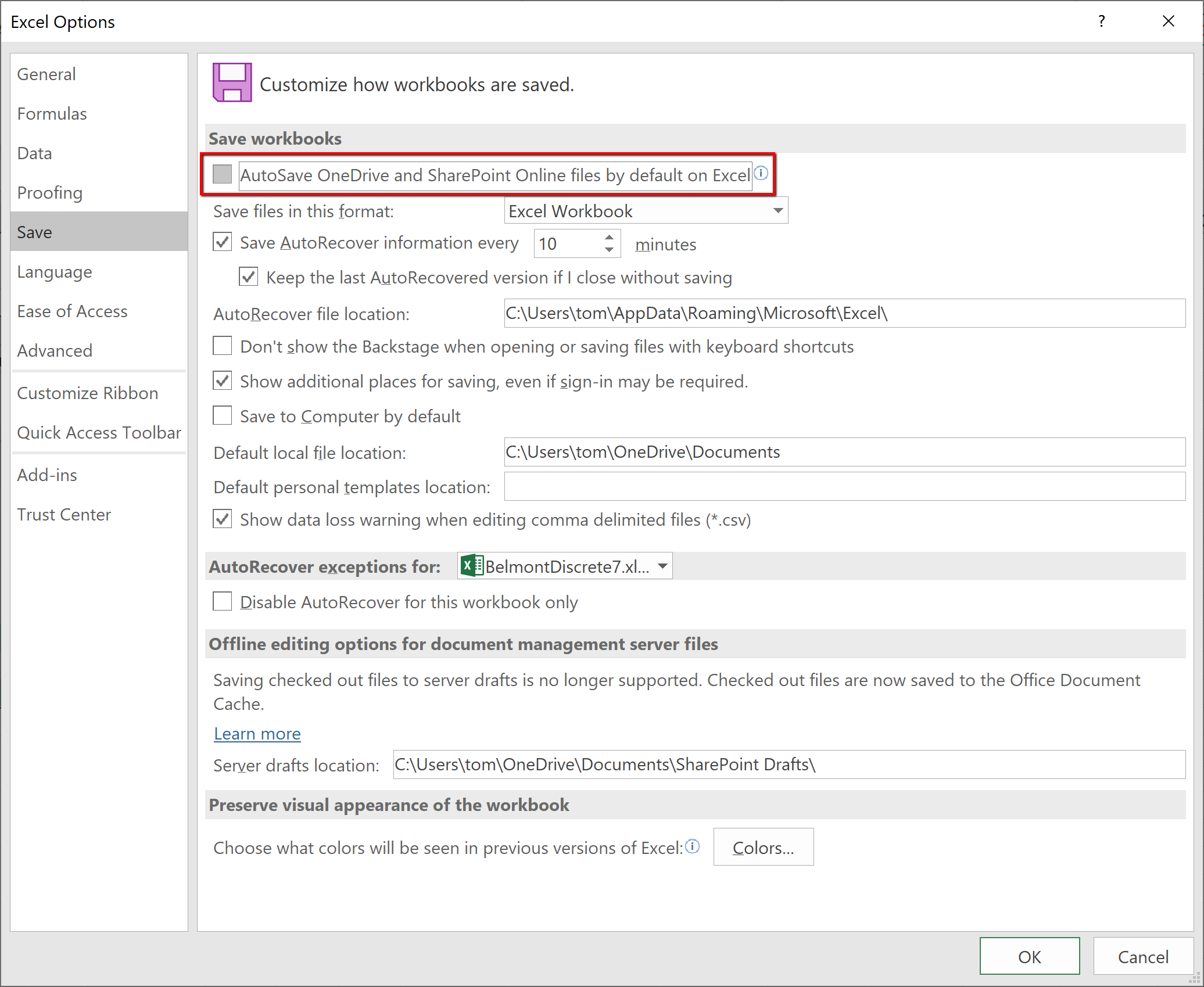
I’m setting up a new computer, and Excel’s default autosaving nuked one of my Ventity input spreadsheets. I did a little quick analysis on the data, meant to be volatile, but Excel cheerfully made it permanent and diffused it to my other computers. Luckily Ventity noticed when I ran the model.
In theory, it’s no big deal, because you can undo autosaved changes. Except that it’s a very big deal, because you can’t easily see that changes have been autosaved. Change a few numbers here and there, and pretty soon you’re on your way to the next London Whale trading disaster. Model integrity is nonexistent.
Fortunately, you can change the backwards default behavior easily. All you need to do is uncheck this box:
Charles D. Brummitt, George Barnett and Raissa M. D’Souza
Abstract
An important challenge in several disciplines is to understand how sudden changes can propagate among coupled systems. Examples include the synchronization of business cycles, population collapse in patchy ecosystems, markets shifting to a new technology platform, collapses in prices and in confidence in financial markets, and protests erupting in multiple countries. A number of mathematical models of these phenomena have multiple equilibria separated by saddle-node bifurcations. We study this behaviour in its normal form as fast–slow ordinary differential equations. In our model, a system consists of multiple subsystems, such as countries in the global economy or patches of an ecosystem. Each subsystem is described by a scalar quantity, such as economic output or population, that undergoes sudden changes via saddle-node bifurcations. The subsystems are coupled via their scalar quantity (e.g. trade couples economic output; diffusion couples populations); that coupling moves the locations of their bifurcations. The model demonstrates two ways in which sudden changes can propagate: they can cascade (one causing the next), or they can hop over subsystems. The latter is absent from classic models of cascades. For an application, we study the Arab Spring protests. After connecting the model to sociological theories that have bistability, we use socioeconomic data to estimate relative proximities to tipping points and Facebook data to estimate couplings among countries. We find that although protests tend to spread locally, they also seem to ‘hop’ over countries, like in the stylized model; this result highlights a new class of temporal motifs in longitudinal network datasets.
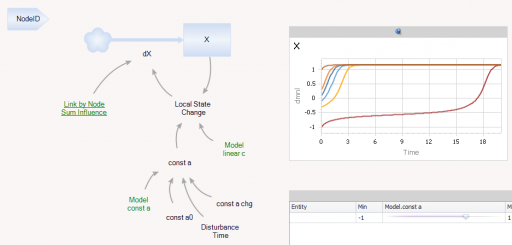
Ventity makes sense here because the system consists of a network of coupled states. Ventity makes it easy to represent a wide variety of network architectures. This means there are two types of entities in the system: “Nodes” and “Couplings.”
The Node entitytype contains a single state (X), with local feedback, as well as a remote influence from Coupling and a few global parameters referenced from the Model entity:
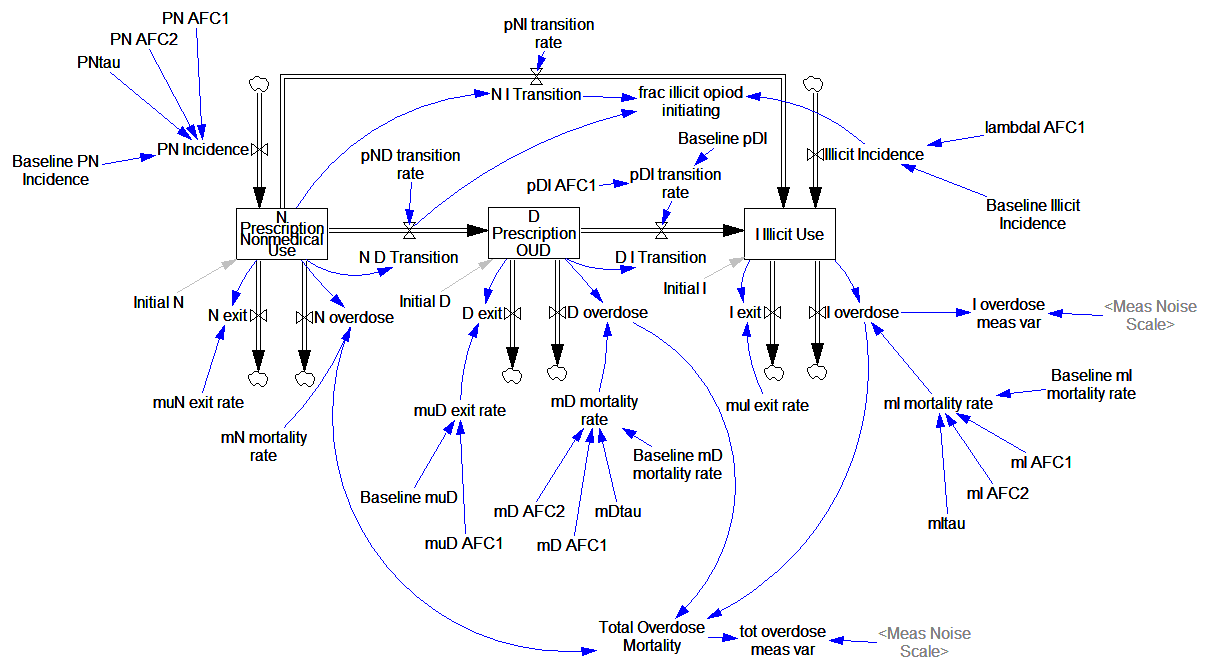
Prevention of Prescription Opioid Misuse and Projected Overdose Deaths in the United States
Qiushi Chen; Marc R. Larochelle; Davis T. Weaver; et al.
Importance Deaths due to opioid overdose have tripled in the last decade. Efforts to curb this trend have focused on restricting the prescription opioid supply; however, the near-term effects of such efforts are unknown.
Objective To project effects of interventions to lower prescription opioid misuse on opioid overdose deaths from 2016 to 2025.
Design, Setting, and Participants This system dynamics (mathematical) model of the US opioid epidemic projected outcomes of simulated individuals who engage in nonmedical prescription or illicit opioid use from 2016 to 2025. The analysis was performed in 2018 by retrospectively calibrating the model from 2002 to 2015 data from the National Survey on Drug Use and Health and the Centers for Disease Control and Prevention.
…
Conclusions and Relevance This study’s findings suggest that interventions targeting prescription opioid misuse such as prescription monitoring programs may have a modest effect, at best, on the number of opioid overdose deaths in the near future. Additional policy interventions are urgently needed to change the course of the epidemic.
The model is fully described in supplementary content, but unfortunately it’s implemented in R and described in Greek letters, so it can’t be run directly:
That’s actually OK with me, because I think I learn more from implementing the equations myself than I do if someone hands me a working model.
While R gives you access to tremendous tools, I think it’s not a good environment for designing and testing dynamic models of significant size. You can’t easily inspect everything that’s going on, and there’s no easy facility for interactive testing. So, I was curious whether that would prove problematic in this case, because the model is small.
Here’s what it looks like, replicated in Vensim:
It looks complicated, but it’s not complex. It’s basically a cascade of first-order delay processes: the outflow from each stock is simply a fraction per time. There are no large-scale feedback loops. Continue reading “Opiod Epidemic Dynamics”
For many aspects of models, we have well-accepted rules that define good practice. All physical stocks must have first-order negative feedback on the outflow. Normalize your lookup tables. Thou shalt balance units.
In some areas, the rules haven’t been written down. Subscripts (arrays) are the poor stepchild of dynamic models. They simply didn’t exist when simulation languages emerged, and no one really thinks about them much. They’re treated as a utility, like memory allocation in C, rather than as a key part of the model architecture. I think that needs to change, so this post is attempt to write down some guidance. Consider it a work in progress; I’d be interested in your thoughts.
What’s the Question?
There are really two kinds of questions:
How much detail do you want in your model? This is just the age-old problem of aggregation, which I won’t rehash in this post.
How do the subscripts you’re using contribute to a transparent, operational description of the system?

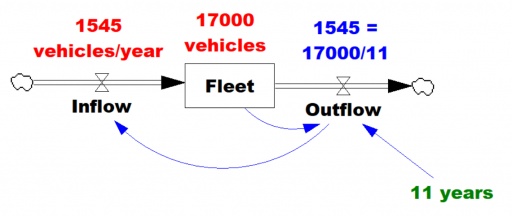 Given the data (red), assume that the vehicle stock is in equilibrium (inflow=outflow). Then it follows from
Given the data (red), assume that the vehicle stock is in equilibrium (inflow=outflow). Then it follows from