I just gave Loopy a try, after seeing Gene Bellinger’s post about it.
It’s cool for diagramming, and fun. There are some clever features, like drawing a circle to create a node (though I was too dumb to figure that out right away). Its shareability and remixing are certainly useful.
However, I think one must be very cautious about simulating causal loop diagrams directly. A causal loop diagram is fundamentally underspecified, which is why no method of automated conversion of CLDs to models has been successful.
In this tool, behavior is animated by initially perturbing the system (e.g, increase the number of rabbits in a predator-prey system). Then you can follow the story around a loop via animated arrow polarity changes – more rabbits causes more foxes, more foxes causes less rabbits. This is essentially the storytelling method of determining loop polarity, which I’ve used many times to good effect.
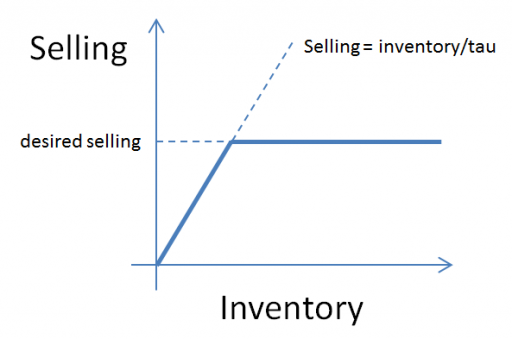
However, as soon as the system has multiple loops, you’re in trouble. Link polarity tells you the direction of change, but not the gain or nonlinearity. So, when multiple loops interact, there’s no way to determine which is dominant. Also, in a real system it matters which nodes are stocks; it’s not sufficient to assume that there must be at least one integration somewhere around a loop.
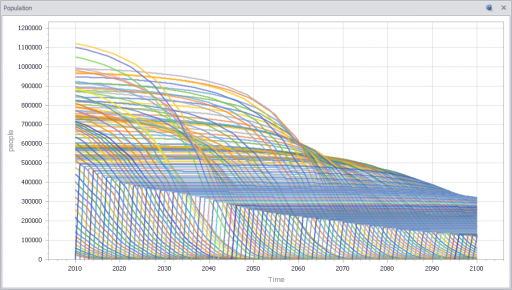
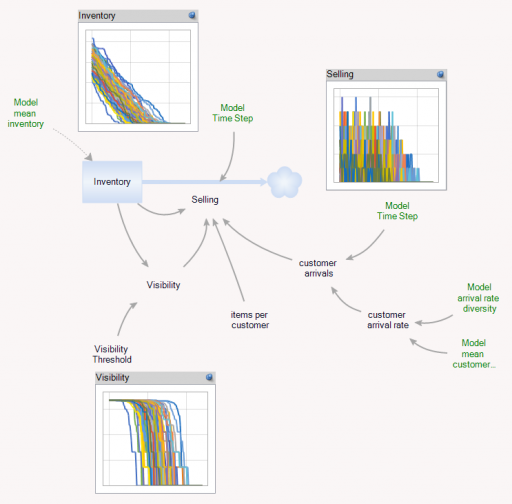
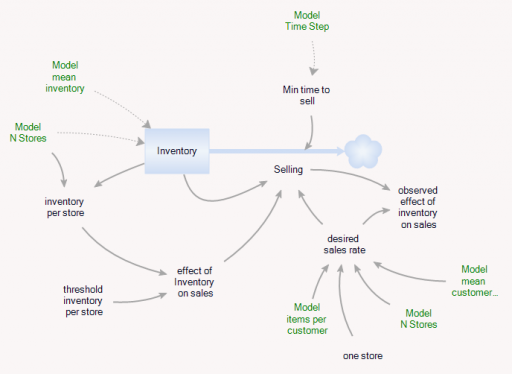
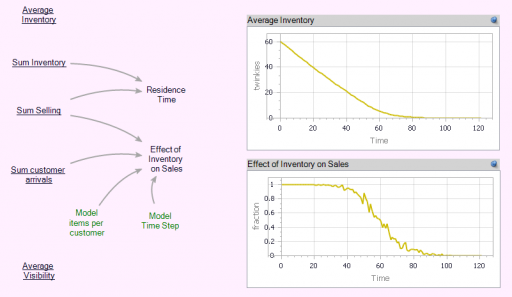
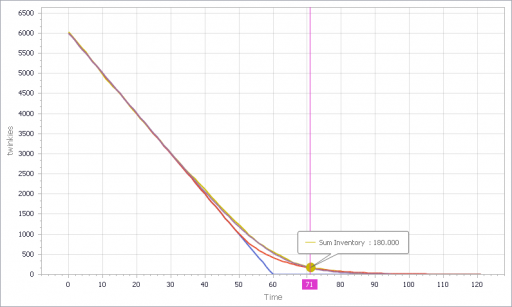
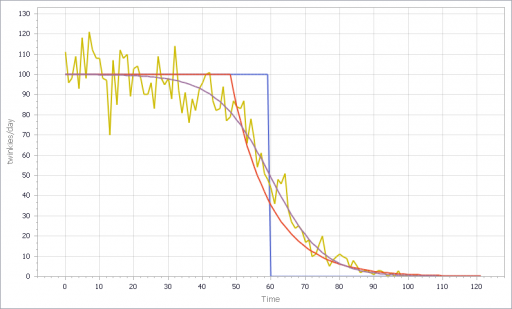
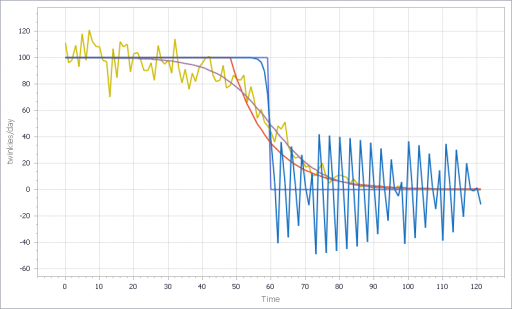
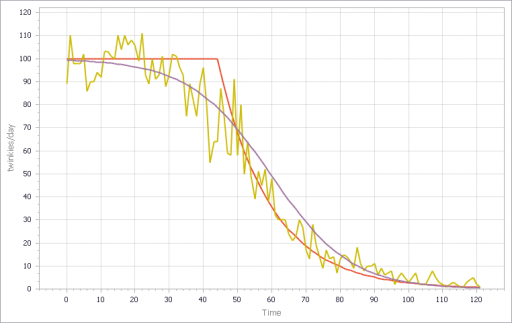
You can test this for yourself by starting with the predator-prey example on the home page. The initial model is a discrete oscillator (more rabbits -> more foxes -> fewer rabbits). But the real system is nonlinear, with oscillation and other possible behaviors, depending on parameters. In Loopy, if you start adding explicit births and deaths, which should get you closer to the real system, simulations quickly result in a sea of arrows in conflicting directions, with no way to know which tendency wins. So, the loop polarity simulation could be somewhere between incomprehensible and dead wrong.
Similarly, if you consider an SIR infection model, there are three loops of interest: spread of infection by contact, saturation from running out of susceptibles, and recovery of infected people. Depending on the loop gains, it can exhibit different behaviors. If recovery is stronger than spread, the infection dies out. If spread is initially stronger than recovery, the infection shifts from exponential growth to goal seeking behavior as dominance shifts nonlinearly from the spread loop to the saturation loop.
I think it would be better if the tool restricted itself to telling the story of one loop at a time, without making the leap to system simulations that are bound to be incorrect in many multiloop cases. With that simplification, I’d consider this a useful item in the toolkit. As is, I think it could be used judiciously for explanations, but for conceptualization it seems likely to prove dangerous.
My mind goes back to Barry Richmond’s approach to systems here. Causal loop diagrams promote thinking about feedback, but they aren’t very good at providing an operational description of how things work. When you’re trying to figure out something that you don’t understand a priori, you need the bottom-up approach to synthesize the parts you understand into the whole you’re grasping for, so you can test whether your understanding of processes explains observed behavior. That requires stocks and flows, explicit goals and actual states, and all the other things system dynamics is about. If we could get to that as elegantly as Loopy gets to CLDs, that would be something.