
I’ve been working on a vehicle fleet model, re-implementing a spreadsheet in Ventity, using dynamic cohorts.
The vehicle lifetime in the spreadsheet is 11 years, and it’s discrete. This means that every vehicle retires precisely 11 years after it’s put into service. This raised a red flag for me, because it represents a rather short vehicle lifetime. I know from work in other jurisdictions that the average life of a vehicle is more like 16-18 years typically (and getting longer as quality improves).
So, where does the 11 year figure come from? We’re not sure. Other published data for the region indicates an average vehicle age of 8.5 years, so it’s not that. A Ventana colleague pointed out that it might be a steady-state estimate from combining vehicle fleet data with new vehicle sales data:
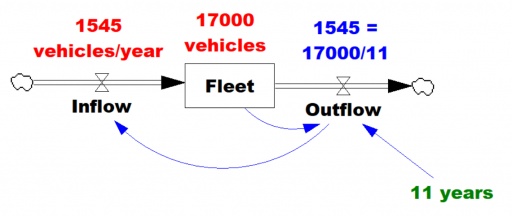 Given the data (red), assume that the vehicle stock is in equilibrium (inflow=outflow). Then it follows from Little’s Law that the average lifetime of vehicles must be 11 years. Little’s Law works regardless of the delay distribution, i.e. regardless of the delay order, but if you were formulating the fleet as a first-order system, that’s precisely how you’d write the outflow equation: outflow = fleet/lifetime, with lifetime=11 years.
Given the data (red), assume that the vehicle stock is in equilibrium (inflow=outflow). Then it follows from Little’s Law that the average lifetime of vehicles must be 11 years. Little’s Law works regardless of the delay distribution, i.e. regardless of the delay order, but if you were formulating the fleet as a first-order system, that’s precisely how you’d write the outflow equation: outflow = fleet/lifetime, with lifetime=11 years.
… the long-term average number L of customers in a stationary system is equal to the long-term average effective arrival rate λ multiplied by the average time W that a customer spends in the system. – Wikipedia
However, there’s a danger here. The system might not be in equilibrium. Then both the assumption of inflow=0utflow and the stationarity required in Little’s Law. Vehicle sales are, unfortunately, rather volatile, particularly around events like the 2008 recession:
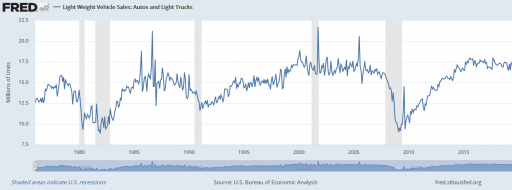
It’s tempting to use the average age of vehicles as another data point, but that turns out to be a bad idea. The average age of vehicles is sensitive to both variations in the inflow and the assumed distribution of the discard process. The following Ventity model illustrates this problem, using some of the same machinery as last week’s Erlang model.
As before, there’s a population of entities (agents). Each has a cascade of N internal states, represented by a stock counter, and an age that increases continuously. An entity deletes itself when it’s too old, or its state count is too high.
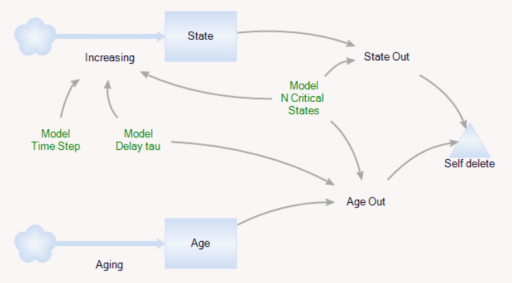
For accounting purposes, when an entity “dies” it records the event by incrementing counter stocks in the Model entity:
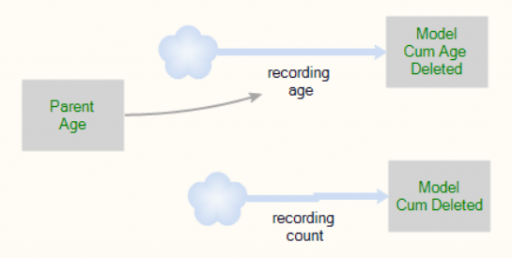
In this way, we can keep track of how old the average entity was at the time it deleted itself. This should be the average residence time in Little’s Law. We can also track the average age of existing entities, to see whether it’s the same.
First, consider a very simple, very nonstationary special case, in which there’s no flow of entity turnover. There’s only an initial population of entities of age 0, who gradually leave the system. Here are three variants of that experiment:
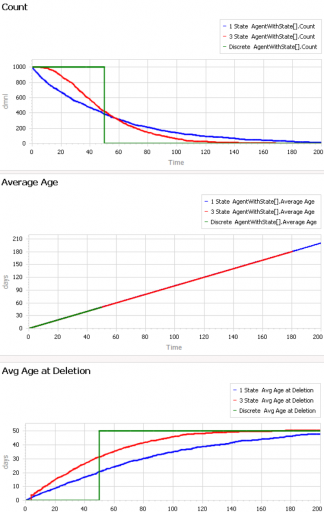
The blue line is the stochastic population analog of the classic first-order delay. The probability of a given entity departing is constant over time, as for radioactive decay. Therefore we get exponential decay, with count = N0*exp(-time/Delay tau). The red line is the third-order equivalent, yielding an Erlang 3 distribution. The green line is the pipeline delay equivalent, in which all entities self-delete at a specified age, rather than with a random distribution. Therefore the population steps from 1000 to 0 at time 50.
The two lower panels compare the average age of surviving entities (middle) to the average age at which entities self-delete (bottom). At bottom, you can see that all variants eventually converge to (roughly) the expected 50-year entity lifespan. However, each trajectory initially indicates a shorter lifespan. This is due to a form of censoring bias – at a given point in time, the longest-lived entities have not yet been observed.
The middle panel indicates how average age can mislead. In this case, age=time for all entities, and therefore the average age increases linearly, even though the expected residence time is constant.
At the opposite extreme, here’s an experiment with a constant flow of new agents, so that the system is in equilibrium after a few time constants:
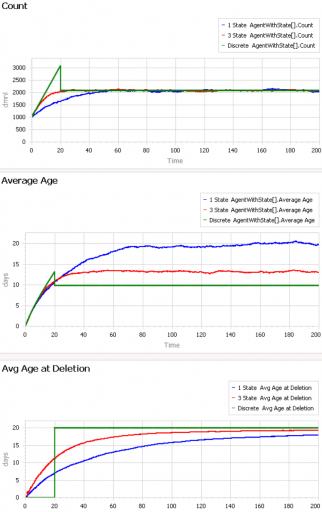
After the initial transient has died out (by time 20 to 60), all 3 residence times (age at deletion) converge to the expected value of 20. But notice the ages. They converge, too, but the value is dependent on the distribution. For the 1st-order system (blue), the average age does equal the average residence time of 20 years. But the pipeline system (green) has an average age that’s half that, at 10 years. This makes sense, if you think about an equilibrium population composed of a uniform mix of ages between 0 and 20 years. The 3rd-order system is in between.
This uncertain relationship between age and residence time means that we can’t use the average age of the vehicle fleet to determine the rate of vehicle turnover. That’s too bad, because age is the one statistic that’s easy to compute from a database of vehicle registrations. To know more, we have to start making inferences about the inflows and outflows – but that’s tricky if data coverage varies with time. Unfortunately, this is a number that we care about, because the residence time of vehicles in the system is an important driver of future penetration of low-carbon technologies.
The model: AgentAge2.zip
The Delay Sandbox can be used to explore similar phenomena in a continuous, aggregate, deterministic setting.
See Sterman’s Business Dynamics, section 11.2.6 for more on Little’s Law and delays.
Dick Larson and I had a similar issue dealing with the estimation of “postdoc duration” based on surveys from “current” postdocs: we rarely have access to people who finish their postdoc training, so a distribution of time in postdoc from people who are postdoc is the only thing available. The question is can you estimate the distribution of total time in postdoc.
.
As you wrote the assumption of steady state can be problematic here. Dick later published an article that looks into the problem, but still in a steady state situation (general form: if you see people waiting in a queue and ask them how long they have been waiting, and get the distribution of their elapse time, can you estimate the distribution of total time in the queue). The results are very interesting, but still is not what you are looking for in systems that are necessarily in steady state. Back then we thought that with some work this can be expanded to non-steady state conditions. Remember that the inflow is more sensitive to stochastic changes than the whole stock.
Cross-sectional surveys: Inferring total eventual time in current state using only elapsed time-to-date https://www.sciencedirect.com/science/article/abs/pii/S0038012115300501
Tom, When at Sandia National Laboratories we looked at the future of personal vehicle drive trains (gas, diesel, electric, hybid, etc.). I will try to find the paper and send it to you. We used up to 25 years when you consider original owner and the used market. I also have a Vensim model with vehicle aging and decreases in performance (fuel efficiency) with aging.
Hi Len,
Could you please share that paper when you can. I am trying to model how the growth in Electric Vehicles will affect the air quality in the UK using system dynamics (VENSIM) for my research project at university.
Many thanks,
Aashay