I’ve just acquired a pair of 18″ Dell XPS portable desktop tablets. It’s one slick piece of hardware, that makes my iPad seem about as sexy as a beer coaster.
They came with Win8 installed. Now I know why everyone hates it. It makes a good first impression with pretty colors and a simple layout. But after a few minutes, you wonder, where’s all my stuff? There’s no obvious way to run a desktop application, so you end up scouring the web for ways to resurrect the Start menu.
It’s bizarre that Microsoft seems to have forgotten the dynamics that made it a powerhouse in the first place. It’s basically this:

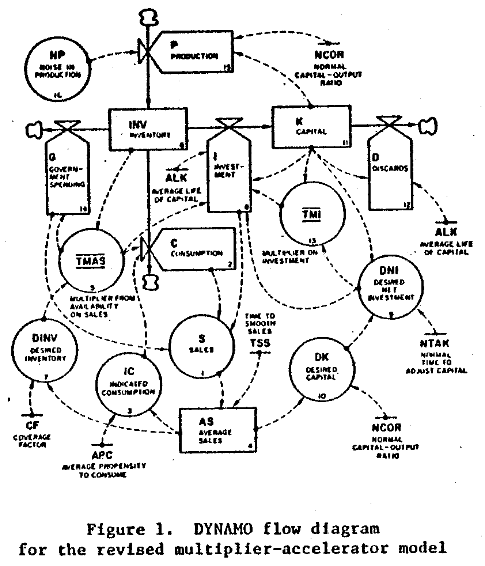
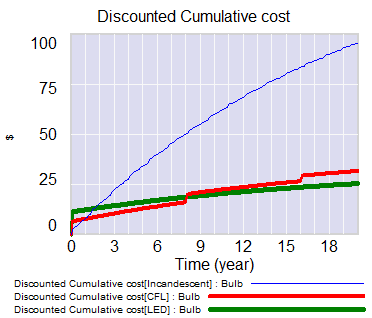
Software is a big nest of positive feedbacks, producing winner-take-all behavior. A few key loops are above. The bottom pair is the classic Bass diffusion model – reinforcing feedback from word of mouth, and balancing feedback from saturation (running out of potential customers). The top loop is an aspect of complementary infrastructure – the more users you have on your platform, the more attractive it is to build apps for it; the more apps there are, the more users you get.
There are lots of similar loops involving accumulation of knowledge, standards, etc. More importantly, this is not a one-player system; there are multiple platforms competing for users, each with its own reinforcing loops. That makes this a success-to-the-successful situation. Microsoft gained huge advantage from these reinforcing loops early in the PC game. Being the first to acquire a huge base of users and applications carried it through many situations in which its tech was not the most exciting thing out there.
So, if you’re Microsoft, and Apple throws you a curve ball by launching a new, wildly successful platform, what should you do? It seems to me that the first imperative should be to preserve the advantages conferred by your gigantic user and application base.
Win8 does exactly the opposite of that:
- Hiding the Start menu means that users have to struggle to find their familiar stuff, effectively chucking out a vast resource, in favor of new apps that are slicker, but pathetically few in number.
- That, plus other decisions, enrage committed users and cause them to consider switching platforms, when a smoother transition would have them comfortably loyal.

This strategy seems totally bonkers.