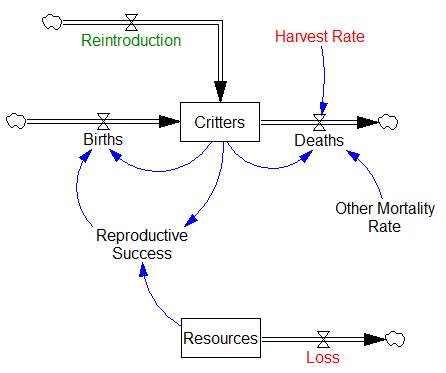
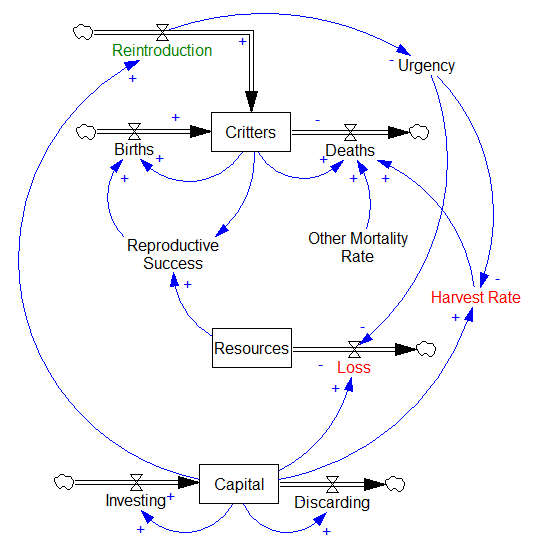
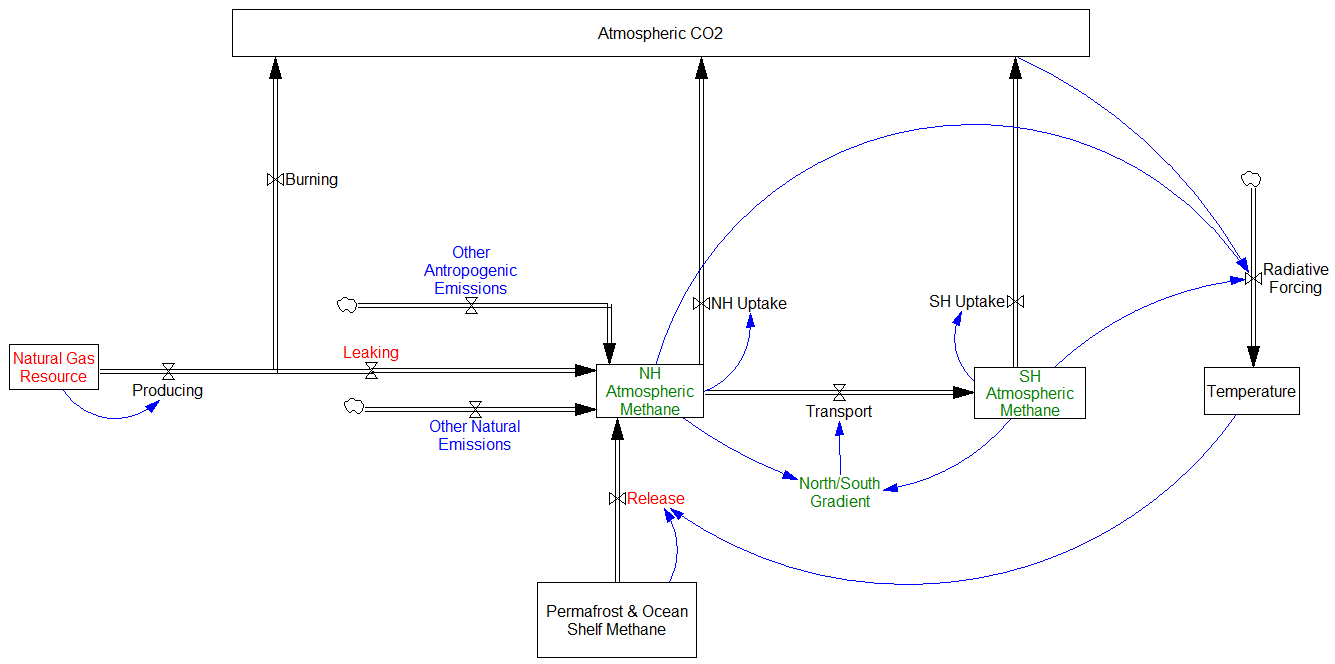
Vensim‘s answer to exploring ill-behaved problem spaces is either to do hill-climbing with random restarts, or MCMC and simulated annealing. Either way, you need to start with some initial distribution of points to search.
It’s helpful if that distribution is somehow efficient at exploring the interesting parts of the space. I think this is closely related to the problem of selecting uninformative priors in Bayesian statistics. There’s lots of research about appropriate uninformative priors for various kinds of parameters. For example,
- If a parameter represents a probability, one might choose the Jeffreys or Haldane prior.
- Indifference to units, scale and inversion might suggest the use of a log uniform prior, where nothing else is known about a positive parameter
However, when a user specifies a parameter in Vensim, we don’t even know what it represents. So what’s the appropriate prior for a parameter that might be positive or negative, a probability, a time constant, a scale factor, an initial condition for a physical stock, etc.?
On the other hand, we aren’t quite as ignorant as the pure maximum entropy derivation usually assumes. For example,
- All numbers have to lie between the largest and smallest float or double, i.e. +/- 3e38 or 2e308.
- More practically, no one scales their models such that a parameter like 6.5e173 would ever be required. There’s a reason that metric prefixes range from yotta to yocto (10^24 to 10^-24). The only constant I can think of that approaches that range is Avogadro’s number (though there are probably others), and that’s not normally a changeable parameter.
- For lots of things, one can impose more constraints, given a little more information,
- A time constant or delay must lie on [TIME STEP,infinity], and the “infinity” of interest is practically limited by the simulation duration.
- A fractional rate of change similarly must lie on [-1/TIME STEP,1/TIME STEP] for stability
- Other parameters probably have limits for stability, though it may be hard to discover them except by experiment.
- A parameter with units of year is probably modern, [1900-2100], unless you’re doing Mayan archaeology or paleoclimate.
At some point, the assumptions become too heroic, and we need to rely on users for some help. But it would still be really interesting to see the distribution of all parameters in real models. (See next …)