
Talking with COVID conspiracy theorists
Tech review has a nice article on how to talk to conspiracy theorists.
 What are they hiding in the woods?
What are they hiding in the woods?
I think some of the insights here are also applicable to talking about models, which is turning out to be a real challenge in the COVID era, with high rates of belief in conspiracies. My experience in social media settings is very negative. If I mention anything indicating that I might actually know something about the problem, that triggers immediate suspicion – oh, so you work for the government, eh? Somehow non sequiturs and hearsay beat models every time.
h/t Chris Soderquist for an interesting resource:
“Any assertion of expertise from an actual expert, meanwhile, produces an explosion of anger from certain quarters of the American public, who immediately complain that such claims are nothing more than fallacious “appeals to authority,” sure signs of dreadful “elitism,” and an obvious effort to use credentials to stifle the dialogue required by a “real” democracy. Americans now believe that having equal rights in a political system also means that each person’s opinion about anything must be accepted as equal to anyone else’s. This is the credo of a fair number of people despite being obvious nonsense. It is a flat assertion of actual equality that is always illogical, sometimes funny, and often dangerous.”
Notes From: Tom Nichols. “The Death of Expertise.” Apple Books.
I’m finding the Tech Review article’s points 3 & 6 to be most productive: test the waters first, and use the Socratic method (careful questioning to reveal gaps in thinking). But the best advice is really proving to be, don’t look and don’t take on the trolls directly. It’s more productive to help people who are curious and receptive to modeling than to battle people who basically resist everything since the enlightenment.
On Problem Statements
Saras Chung’s plenary commentary at ISDC 2020 reminded me of this nice article:
The Most Underrated Skill in Management
There are few management skills more powerful than the discipline of clearly articulating the problem you seek to solve before jumping into action.
BY NELSON P. REPENNING, DON KIEFFER, AND TODD ASTOR
A good problem statement has five basic elements:
• It references something the organization cares about and connects that element to a clear and specific goal;
• it contains a clear articulation of the gap between the current state and the goal;
• the key variables — the target, the current state, and the gap — are quantifiable;
• it is as neutral as possible concerning possible diagnoses or solutions; and
• it is sufficiently small in scope that you can tackle it quickly.
Excel, lost in the cloud
Excel is rapidly becoming unusable as Microsoft tries to shift everyone into the OneDrive/Sharepoint cloud. Here’s a very simple equation from a population model:
='https://ventanasystems-my.sharepoint.com/personal/vrbo_onmicrosoft_com/Documents/_Mkt/lxpgi/Model/Model/[Cohort Model Natural Increase.xlsx]Boston'!S135+'https://ventanasystems-my.sharepoint.com/personal/vrbo_onmicrosoft_com/Documents/_Mkt/lxpgi/Model/Model/[Cohort Model Immigration.xlsx]Boston'!S119+('https://ventanasystems-my.sharepoint.com/personal/vrbo_onmicrosoft_com/Documents/_Mkt/lxpgi/Model/Model/[Cohort Model NPR.xlsx]Boston'!S119-'https://ventanasystems-my.sharepoint.com/personal/vrbo_onmicrosoft_com/Documents/_Mkt/lxpgi/Model/Model/[Cohort Model.xlsx]Boston'!R119
URLs as equation terms? What were they thinking? This is an interface choice that makes things easy for programmers, and impossible for users.
Coronavirus Roundup II
Some things I’ve found interesting and useful lately:
R0
What I think is a pretty important article from LANL: High Contagiousness and Rapid Spread of Severe Acute Respiratory Syndrome Coronavirus 2. This tackles the questions I wondered about in my steady state growth post, i.e. that high observed growth rates imply high R0 if duration of infectiousness is long.
Earlier in the epidemic, this was already a known problem:
The reproductive number of COVID-19 is higher compared to SARS coronavirus
Data
Epiforecasts’ time varying R0 estimates
CMMID’s time varying reporting coverage estimates
NECSI’s daily update for the US
The nifty database of US state policies from Raifman et al. at BU
A similar policy tracker for the world
The covidtracking database. Very useful, if you don’t mind a little mysterious turbulence in variable naming.
The Kinsa thermometer US health weather map
Miscellaneous
Nature’s Special report: The simulations driving the world’s response to COVID-19
Pandemics Depress the Economy, Public Health Interventions Do Not: Evidence from the 1918 Flu
Projecting the transmission dynamics of SARS-CoV-2 through the postpandemic period has some interesting dynamics, including seasonality.
Quantifying SARS-CoV-2 transmission suggests epidemic control with digital contact tracing looks at requirements for contact tracing and isolation
Models for Count Data With Overdispersion has important considerations for calibration
Variolation: hmm. Filed under “interesting but possibly crazy.”
Creative, and less obviously crazy: An alternating lock-down strategy for sustainable mitigation of COVID-19
How useful are antibody tests?
I just ran across this meta-analysis of antibody test performance on medrxiv:
Antibody tests in detecting SARS-CoV-2 infection: a meta-analysis
In total, we identified 38 eligible studies that include data from 7,848 individuals. The analyses showed that tests using the S antigen are more sensitive than N antigen-based tests. IgG tests perform better compared to IgM ones, andshow better sensitivity when the samples were taken longer after the onset of symptoms. Moreover, irrespective of the method, a combined IgG/IgM test seems to be a better choice in terms of sensitivity than measuring either antibody type alone. All methods yielded high specificity with some of them (ELISA and LFIA) reaching levels around 99%. ELISA-and CLIA-based methods performed better in terms of sensitivity (90-94%) followed by LFIA and FIA with sensitivities ranging from 80% to 86%.
The sensitivity results are interesting, but I’m more interested in timing:
Sample quality, low antibody concentrations and especially timing of the test -too soon after a person is infected when antibodies have not been developed yet or toolate when IgM antibodies have decreased or disappeared -could potentially explain the low ability of the antibody tests to identify people with COVID-19. According to kinetic measurements of some of the included studies 22, 49, 54 IgM peaks between days 5 and 12 and then drops slowly. IgGs reach peak concentrations after day 20 or so as IgM antibodies disappear. This meta-analysis showed, through meta-regression, that IgG tests did have better sensitivity when the samples were taken longer after the onset of symptoms. This is further corroborated by the lower specificity of IgM antibodies compared to IgG 15. Only few of the included studies provided data stratified by the time of onset of symptoms, so a separate stratified analysis was not feasible, but this should be a goal for future studies.
This is an important knowledge gap. Timing really matters, because tests that aren’t sensitive to early asymptomatic transmission have limited utility for preventing spread. Consider the distribution of serial infection times (Ferretti et al., Science):
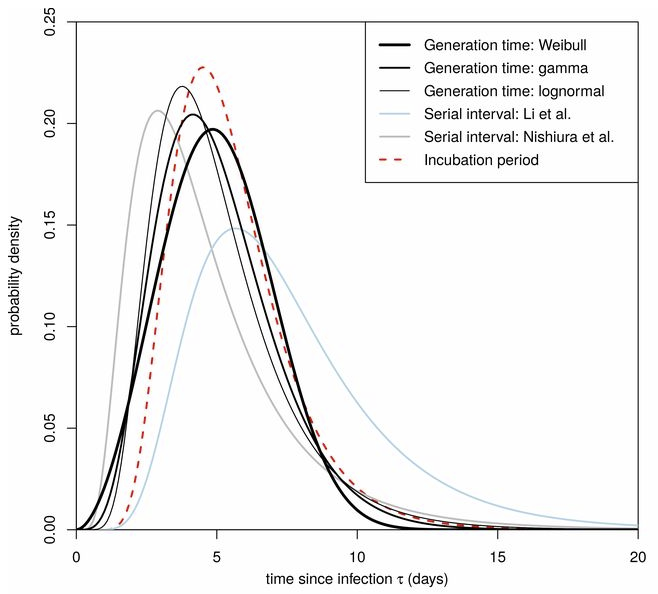
Testing by itself doesn’t do anything to reduce the spread of infection. It’s an enabler: transmission goes down only if coronavirus-positive individuals identified through testing change their behavior. That implies a chain of delays:
- Conduct the test and get the results
- Inform the positive person
- Get them into a situation where they won’t infect their coworkers, family, etc.
- Trace their contacts, test them, and repeat
A test that only achieves peak sensitivity at >5 days may not leave much time for these delays to play out, limiting the effectiveness of contact tracing and isolation. A test that peaks at day 20 would be pretty useless (though interesting for surveillance and other purposes).
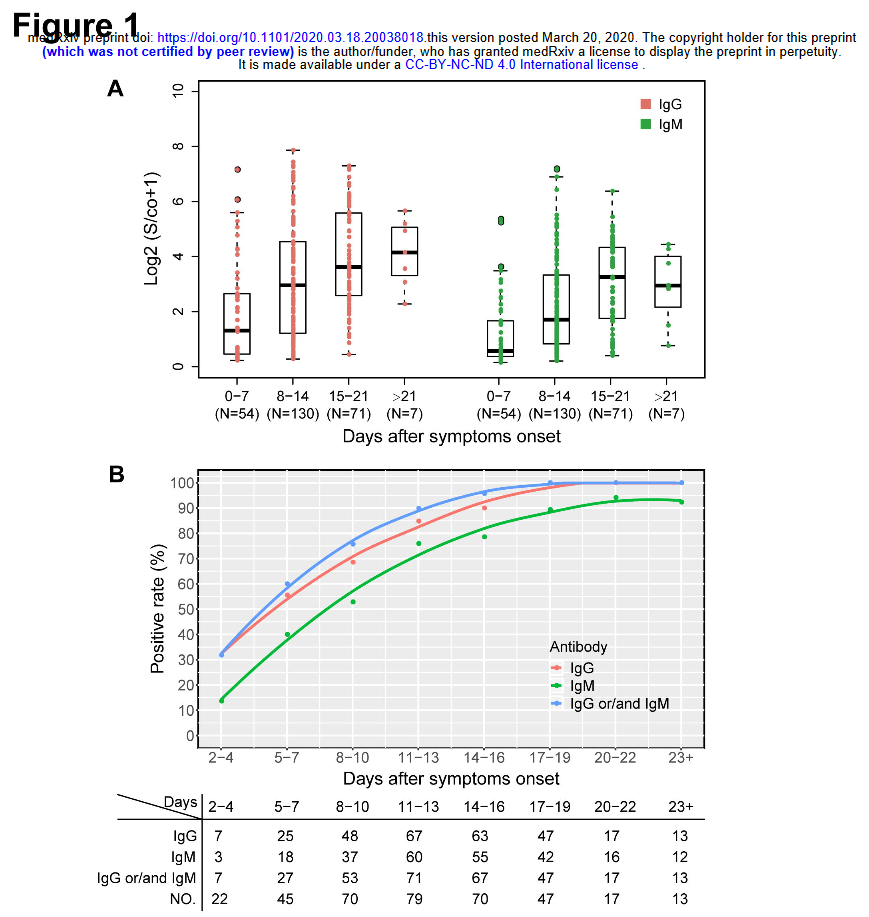
Seroconversion rates of 30% at onset of symptoms seem problematic, given the significant pre-symptomatic transmission implied by the Ferretti, Liu & Nishiura results on serial infection times. I hope the US testing strategy relies on lots of fast tests, not just lots of tests.
See also:
Antibody surveys suggesting vast undercount of coronavirus infections may be unreliable in Science
h/t Yioryos Stamboulis
A coronavirus prediction you can bank on
How many cases will there be on June 1? Beats me. But there’s one thing I’m sure of.
My confidence bounds on future behavior of the epidemic are still pretty wide. While there’s good reason to be optimistic about a lot of locations, there are also big uncertainties looming. No matter how things shake out, I’m confident in this:
The antiscience crowd will be out in force. They’ll cherry-pick the early model projections of an uncontrolled epidemic, and use that to claim that modelers predicted a catastrophe that didn’t happen, and conclude that there was never a problem. This is the Cassandra’s curse of all successful modeling interventions. (See Nobody Ever Gets Credit for Fixing Problems that Never Happened for a similar situation.)
But it won’t stop there. A lot of people don’t really care what the modelers actually said. They’ll just make stuff up. Just today I saw a comment at the Bozeman Chronicle to the effect of, “if this was as bad as they said, we’d all be dead.” Of course that was never in the cards, or the models, but that doesn’t matter in Dunning Krugerland.
Modelers, be prepared for a lot more of this. I think we need to be thinking more about defensive measures, like forecast archiving and presentation of results only with confidence bounds attached. However, it’s hard to do that and to produce model results at a pace that keeps up with the evolution of the epidemic. That’s something we need more infrastructure for.
Coronavirus Curve-fitting OverConfidence
This is a follow-on to The Normal distribution is a bad COVID19 model.
I understand that the IHME model is now more or less the official tool of the Federal Government. Normally I’m happy to see models guiding policy. It’s better than the alternative: would you fly in a plane designed by lawyers? (Apparently we have been.)
However, there’s nothing magic about a model. Using flawed methods, bad data, the wrong boundary, etc. can make the results GIGO. When a bad model blows up, the consequences can be just as harmful as any other bad reasoning. In addition, the metaphorical shrapnel hits the rest of us modelers. Currently, I’m hiding in my foxhole.
On top of the issues I mentioned previously, I think there are two more problems with the IHME model:
First, they fit the Normal distribution to cumulative cases, rather than incremental cases. Even in a parallel universe where the nonphysical curve fit was optimal, this would lead to understatement of the uncertainty in the projections.
Second, because the model has no operational mapping of real-world concepts to equation structure, you have no hooks to use to inject policy changes and the uncertainty associated with them. You have to construct some kind of arbitrary index and translate that to changes in the size and timing of the peak in an unprincipled way. This defeats the purpose of having a model.
For example, from the methods paper:
A covariate of days with expected exponential growth in the cumulative death rate was created using information on the number of days after the death rate exceeded 0.31 per million to the day when different social distancing measures were mandated by local and national government: school closures, non-essential business closures including bars and restaurants, stay-at-home recommendations, and travel restrictions including public transport closures. Days with 1 measure were counted as 0.67 equivalents, days with 2 measures as 0.334 equivalents and with 3 or 4 measures as 0.
This postulates a relationship that has only the most notional grounding. There’s no concept of compliance, nor any sense of the effect of stringency and exceptions.
In the real world, there’s also no linear relationship between “# policies implemented” and “days of exponential growth.” In fact, I would expect this to be extremely nonlinear, with a threshold effect. Either your policies reduce R0 below 1 and the epidemic peaks and shrinks, or they don’t, and it continues to grow at some positive rate until a large part of the population is infected. I don’t think this structure captures that reality at all.
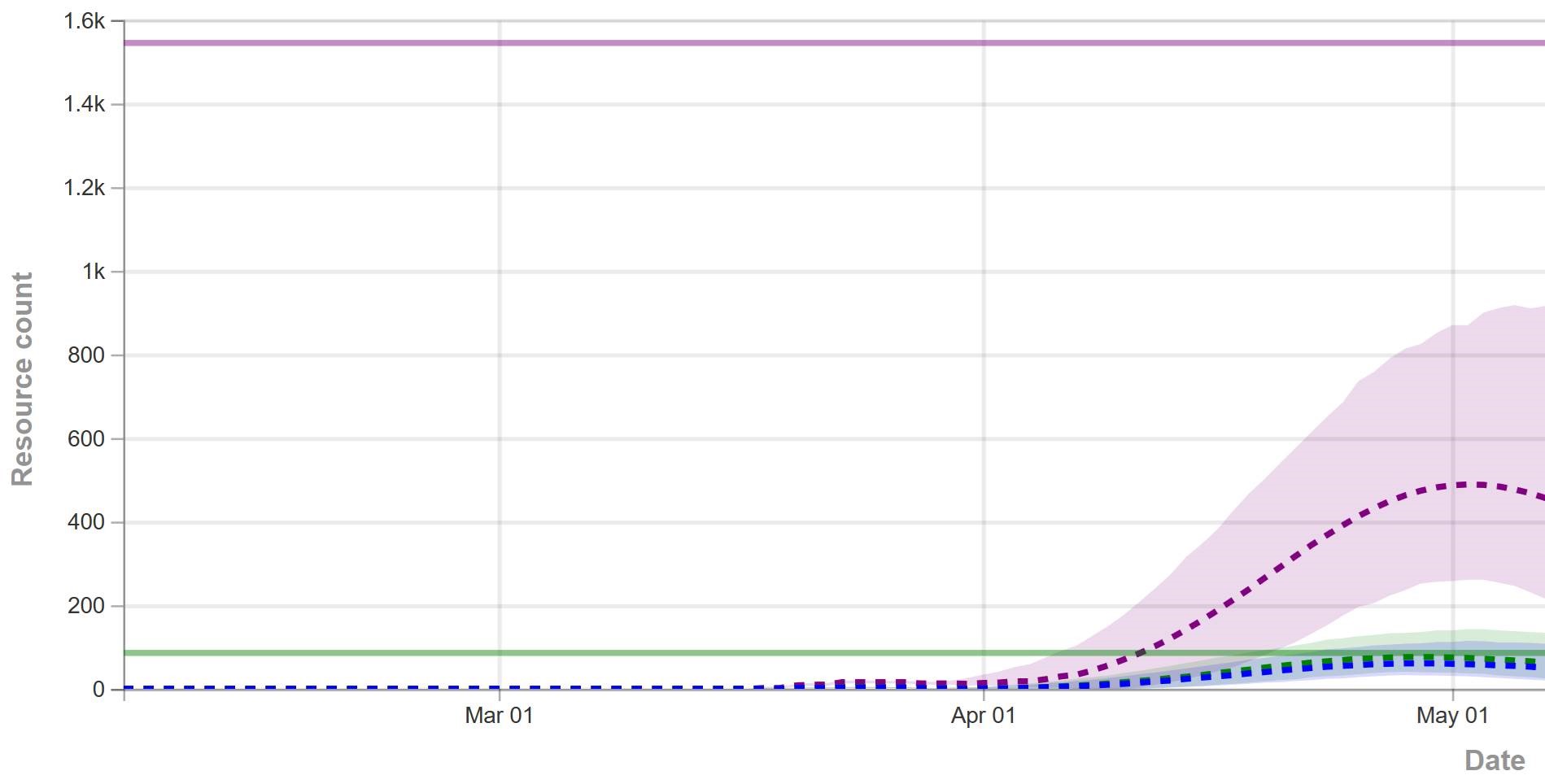
That’s why, in the IHME figure above (retrieved yesterday), you don’t see any scenarios in which the epidemic fizzles, because we get lucky and warm weather slows the virus, or there are many more mild cases than we thought. You also don’t see any runaway scenarios in which measures fail to bring R0 below 1, resulting in sustained growth. Nor is there any possibility of ending measures too soon, resulting in an echo.
For comparison, I ran some sensitivity runs my model for North Dakota last night. I included uncertainty from fit to data (for example, R0 constrained to fit observations via MCMC) and some a priori uncertainty about effectiveness and duration of measures, and from the literature about fatality rates, seasonality, and unobserved asymptomatics.
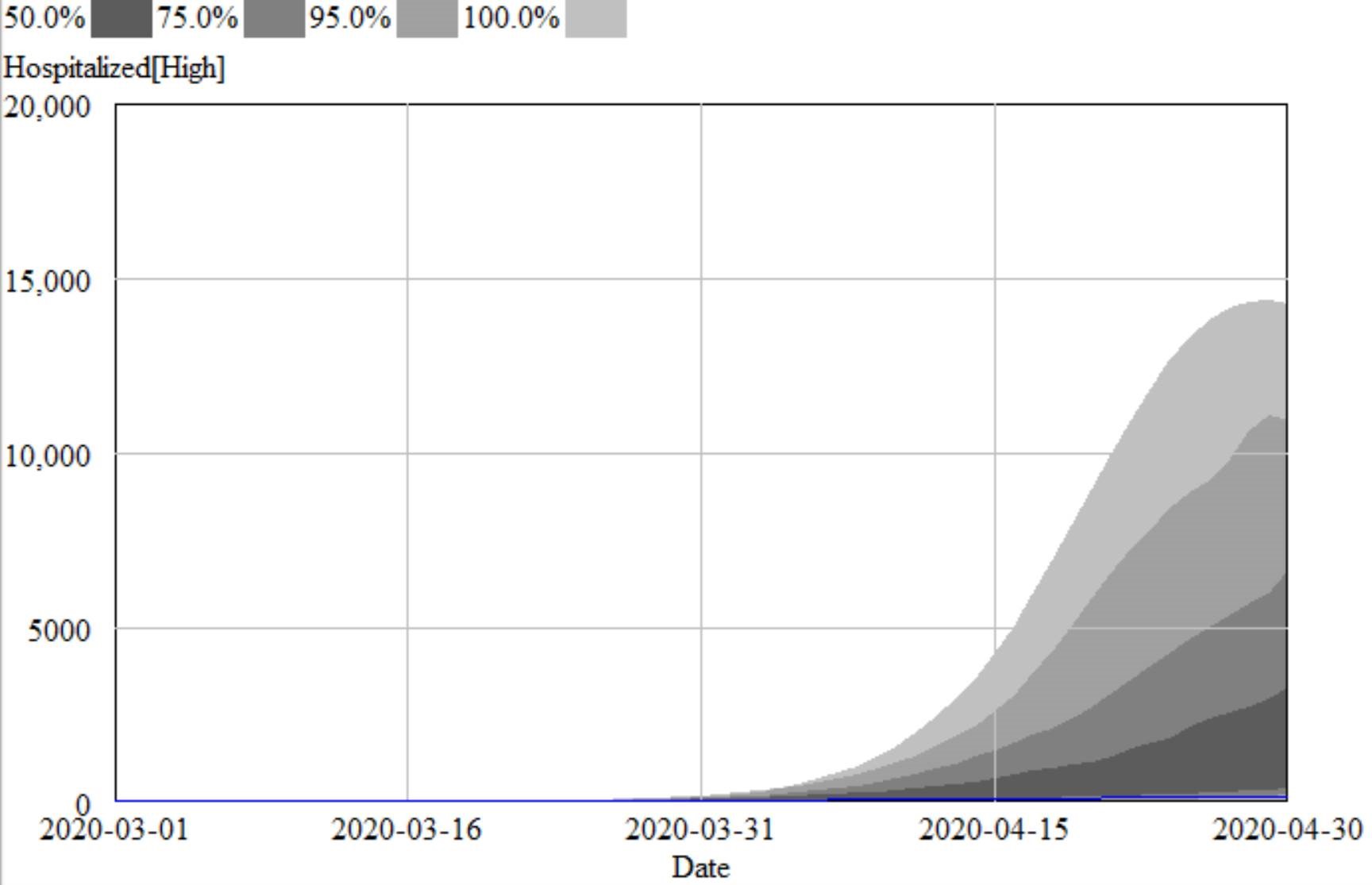
I found that I couldn’t exclude the IHME projections from my confidence bounds, so they’re not completely crazy. However, they understate the uncertainty in the situation by a huge margin. They forecast the peak at a fairly definite time, plus or minus a factor of two. With my hybrid-SEIR model, the 95% bounds include variation by a factor of 10. The difference is that their bounds are derived only from curve fitting, and therefore omit a vast amount of structural uncertainty that is represented in my model.
Who is right? We could argue, but since the IHME model is statistically flawed and doesn’t include any direct effect of uncertainty in R0, prevalence of unobserved mild cases, temperature sensitivity of the virus, effectiveness of measures, compliance, travel, etc., I would not put any money on the future remaining within their confidence bounds.
Crusonia on COVID19
On Saturday I gave a quick introduction to modeling the coronavirus epidemic in a Crusonia livestream, followed by Q&A. We had some really smart people on the call, with lots of interesting ideas to follow up on. I talk a bit about economic tradeoffs, using a speculative extension of my earlier model. One thing that was clearer to me after the discussion than before is just how hamstrung we’ve been by the lack of testing. I think it would not be much of stretch to say that this failure is costing us a billion dollars a day, due to inability to isolate the infected and lack of information for decision making.
The second panelist – Eugene Scarberry – was really interesting, both for his extensive experience in the trenches getting things approved at the FDA, and some good background on ventilators and alternatives, and how to get more of them.
The Normal distribution is a bad COVID19 model
Forecasting diffusion processes by fitting sigmoid curves has a long history of failure. Let’s not repeat those mistakes in the COVID19 epidemic.
I’ve seen several models explaining “flattening the curve” that use the Normal distribution as a model of the coronavirus epidemic. Now this model uses it to forecast peak hospital load:
We developed a curve-fitting tool to fit a nonlinear mixed effects model to the available admin 1 cumulative death data. The cumulative death rate for each location is assumed to follow a parametrized Gaussian error function … where the function is the Gaussian error function(written explicitly above), p controls the maximum death rate at each location, t is the time since death rate exceeded 1e-15, ß(beta)is a location-specific inflection point(time at which rate of increase of the death rate is maximum), and α(alpha)is a location-specific growth parameter. Other sigmoidal functional forms … were considered but did not fit the data as well. Data were fit to the log of the death rate in the available data, using an optimization framework described in the appendix.
One bell-shaped curve is as good as another, right? No!
 Like Young Frankenstein, epidemic curves are not Normal.
Like Young Frankenstein, epidemic curves are not Normal.
1. Fit to data is a weak test.
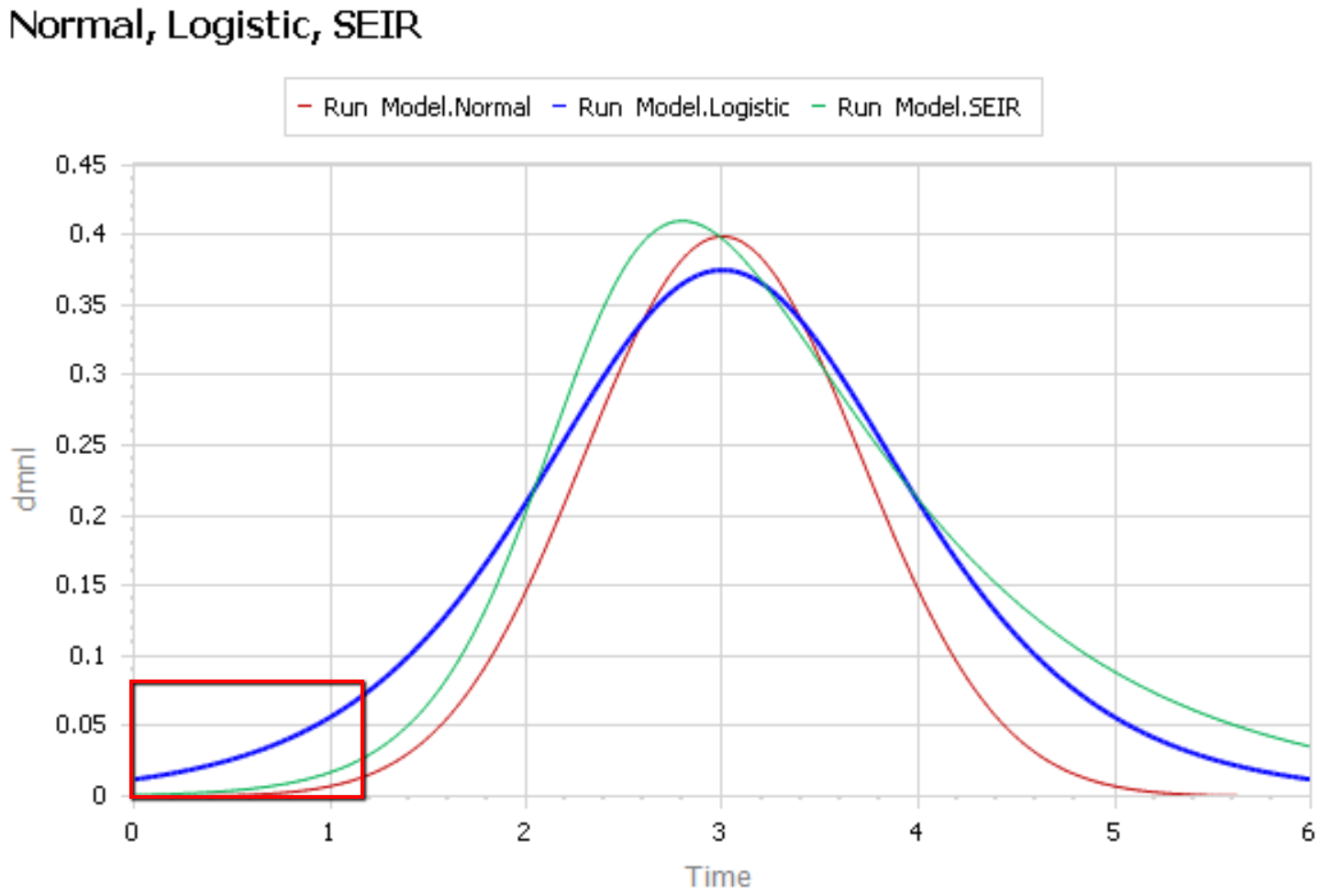
The graph below compares 3 possible models: the Normal distribution, the Logistic distribution (which has an equivalent differential equation interpretation), and the SEIR model. Consider what’s happening when you fit a sigmoid to the epidemic data so far (red box). The curves below are normalized to yield similar peaks, but imagine what would happen to the peaks if you fit all 3 to the same data series.
The problem is that this curve-fitting exercise expects data from a small portion of the behavior to tell you about the peak. But over that interval, there’s little behavior variation. Any exponential is going to fit reasonably well. Even worse, if there are any biases in the data, such as dramatic shifts in test coverage, the fit is likely to reflect those biases as much as it does the physics of the system. That’s largely why the history of fitting diffusion models to emerging trends in the forecasting literature is so dreadful.
After the peak, the right tail of the SEIR model is also quite different, because the time constant of recovery is different from the time constant for the growth phase. This asymmetry may also have implications for planning.
2. The properties of the Normal distribution don’t match the observed behavior of coronavirus.
It’s easier to see what’s going on if you plot the curves above on a log-y scale:
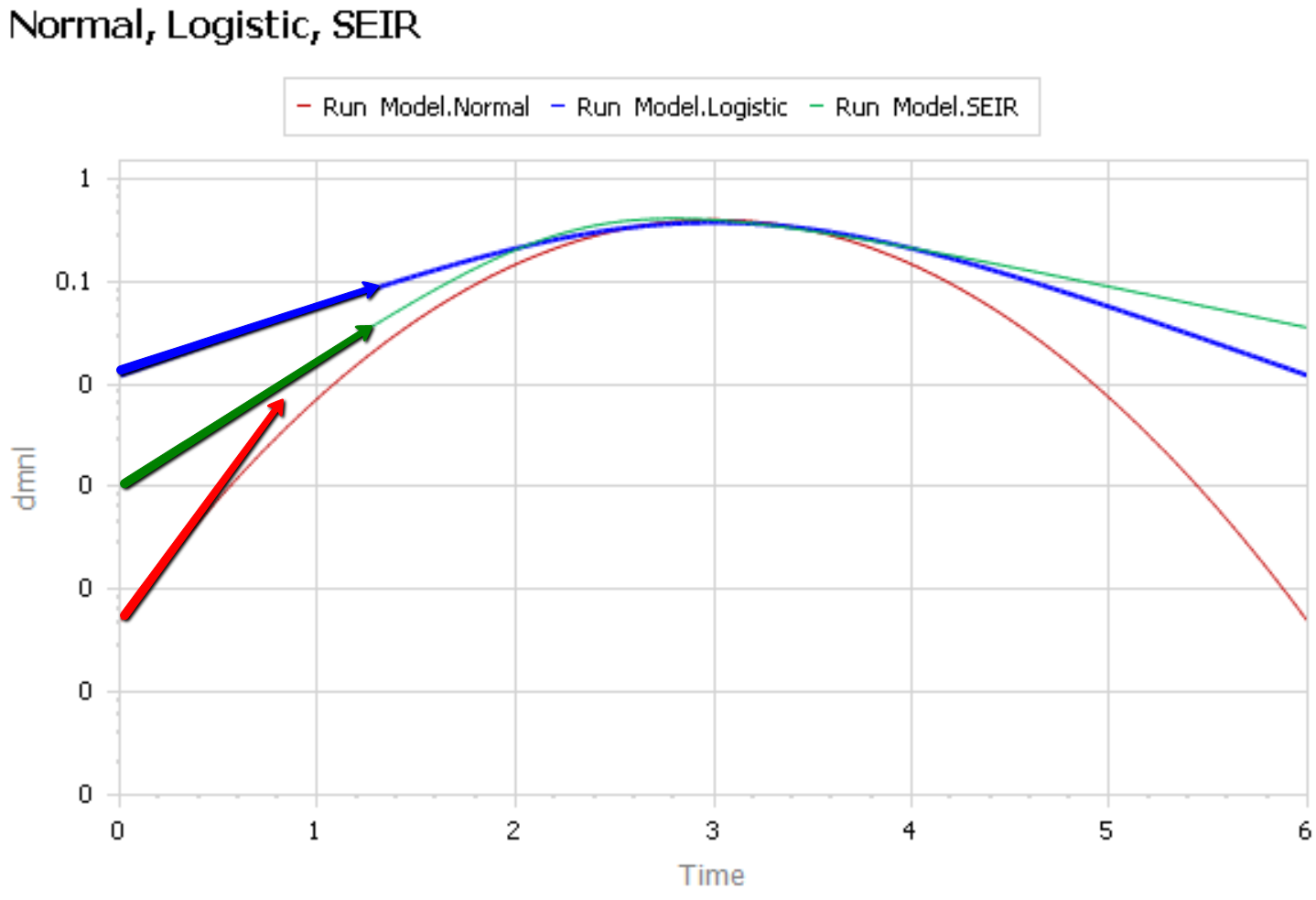
The logistic and SEIR models have a linear left tail. That is to say that they have a constant growth rate in the early epidemic, until controls are imposed or you run out of susceptible people.
The Normal distribution (red) is a parabola, which means that the growth rate is steadily decreasing, long before you get near the peak. Similarly, if you go backwards in time, the Normal distribution predicts that the growth rate would have been higher back in November, when patient 0 emerged.
There is some reason to think that epidemics start faster due to social network topology, but also some reasons for slower emergence. In any case, that’s not what is observed for COVID19 – uncontrolled growth rates are pretty constant:
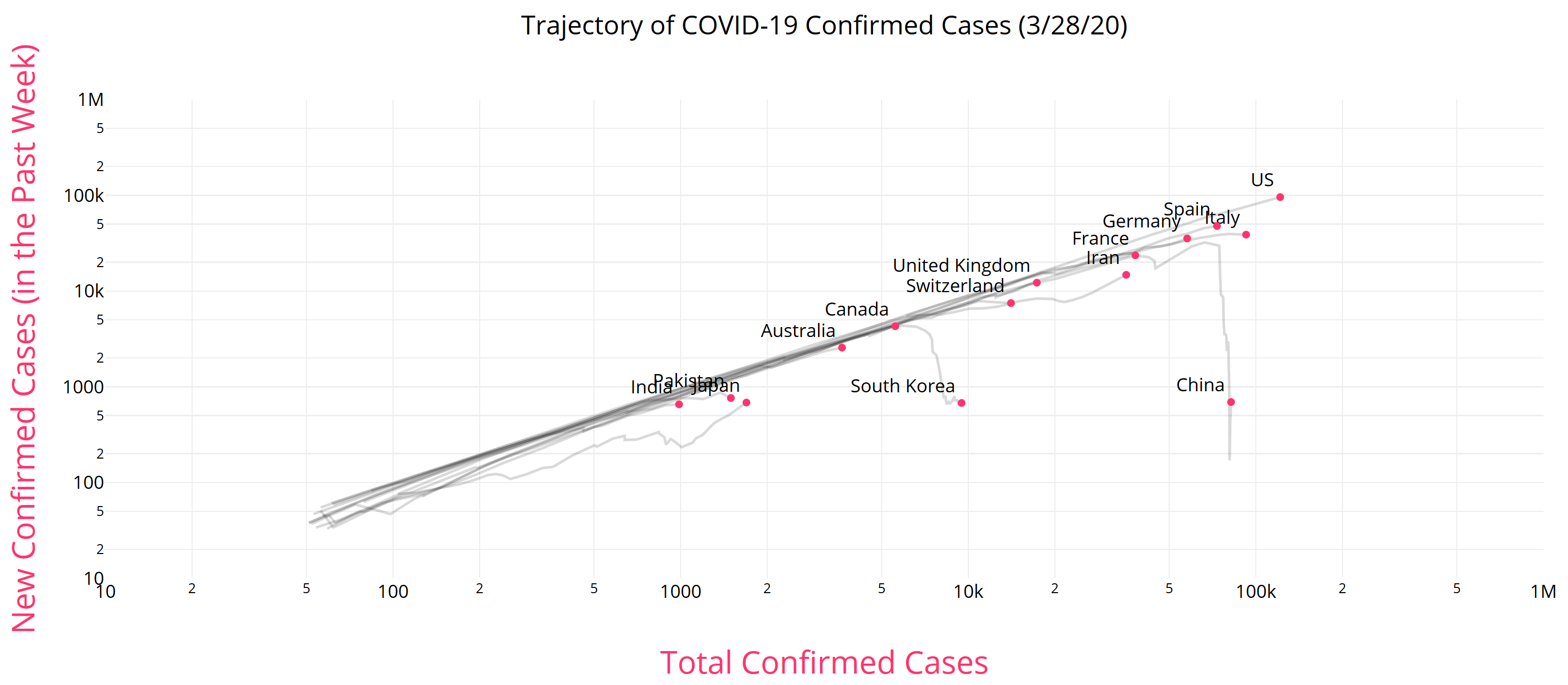
https://aatishb.com/covidtrends/
3. With weak data, you MUST have other quality checks
Mining data to extract relationships works great in many settings. But when you have sparse data with lots of known measurement problems, it’s treacherous. In that case, you need a model of the physics of the system and the lags and biases in the data generating process. Then you test that model against all available information, including
- conservation laws,
- operational correspondence with physical processes,
- opinions from subject matter experts and measurements from other levels of aggregation,
- dimensional consistency,
- robustness in extreme conditions, and finally
- fit to data.
Fortunately, a good starting point has existed for almost a century: the SEIR model. It’s not without pitfalls, and needs some disaggregation and a complementary model of policies and the case reporting process, but if you want simple projections, it’s a good place to start.
Once you have triangulation from all of these sources, you have some hope of getting the peak right. But your confidence bounds should still be derived not only from the fit itself, but also priors on parameters that were not part of the estimation process.