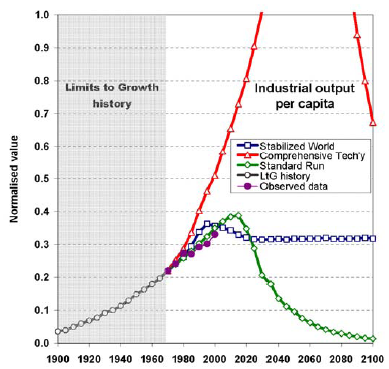
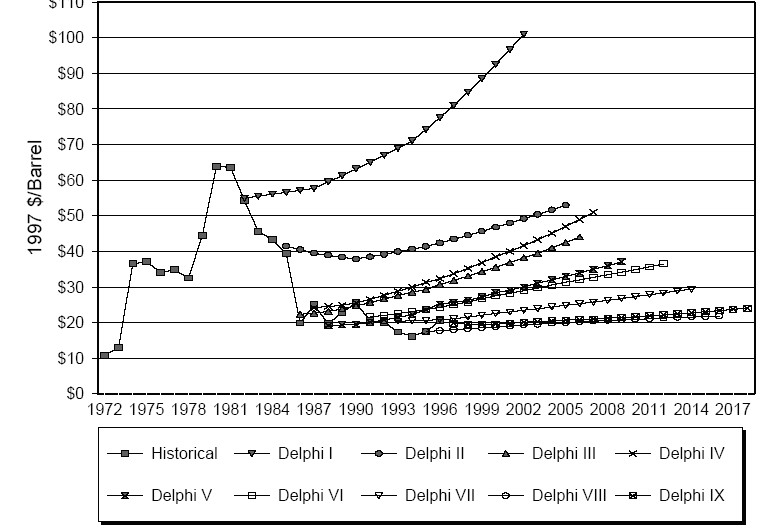
I hadn’t noticed until I heard it here, but Armstrong & Green are back at it, with various claims that climate forecasts are worthless. In the Financial Post, they criticize the MIT Joint Program model,
… No more than 30% of forecasting principles were properly applied by the MIT modellers and 49 principles were violated. For an important problem such as this, we do not think it is defensible to violate a single principle.
As I wrote in some detail here, the Forecasting Principles are a useful seat-of-the-pants guide to good practices, but there’s no evidence that following them all is necessary or sufficient for a good outcome. Some are likely to be counterproductive in many situations, and key elements of good modeling practice are missing (for example, balancing units of measure).
It’s not clear to me that A&G really understand models and modeling. They seem to view everything through the lens of purely statistical methods like linear regression. Green recently wrote,
Another important principle is that the forecasting method should provide a realistic representation of the situation (Principle 7.2). An interesting statement in the MIT report that implies (as one would expect given the state of knowledge and omitted relationships) that the modelers have no idea to what extent their models provide a realistic representation of reality is as follows:
‘Changes in global surface average temperature result from a combination of emissions and climate parameters, and therefore two runs that look similar in terms of temperature may be very different in detail.’ (MIT Report p. 28)
While the modelers have sufficient latitude in their parameters to crudely reproduce a brief period of climate history, there is no reason to believe the models can provide useful forecasts.
What the MIT authors are saying, in essence, is that
T = f(E,P)
and that it is possible to achieve the same future temperature T with different combinations of emissions E and parameters P. Green seems to be taking a leap, to assume that historic T does not provide much constraint on P. First, that’s not necessarily true, given that historic E cannot be chosen freely. It could still be the case that the structure of f(E,P) means that historic T provides a weak constraint on P given E. But if that’s true (as it basically is), the problem is self-diagnosing: estimates of P will have broad confidence bounds, as will forecasts of T. Green completely ignores the MIT authors’ explicit characterization of this uncertainty. He also ignores the fact that the output of the model is not just T, and that we have priors for many elements of P (from more granular models or experiments, for example). Thus we have additional lines of evidence with which to constrain forecasts. Green also neglects to consider the implications of uncertainties in P that are jointly distributed in an offsetting manner (as is likely for climate sensitivity, ocean circulation, and aerosol forcing).
A&G provide no formal method to distinguish between situations in which models yield useful or spurious forecasts. In an earlier paper, they claimed rather broadly,
‘To our knowledge, there is no empirical evidence to suggest that presenting opinions in mathematical terms rather than in words will contribute to forecast accuracy.’ (page 1002)
This statement may be true in some settings, but obviously not in general. There are many situations in which mathematical models have good predictive power and outperform informal judgments by a wide margin.
A&G’s latest paper with Willie Soon, Validity of Climate Change Forecasting for Public Policy Decision Making, apparently forthcoming in IJF, is an attempt to make the distinction, i.e. to determine whether climate models have any utility as predictive tools. An excerpt from the abstract summarizes their argument:
Policymakers need to know whether prediction is possible and if so whether any proposed forecasting method will provide forecasts that are substantively more accurate than those from the relevant benchmark method. Inspection of global temperature data suggests that it is subject to irregular variations on all relevant time scales and that variations during the late 1900s were not unusual. In such a situation, a ‘no change’ extrapolation is an appropriate benchmark forecasting method. … The accuracy of forecasts from the benchmark is such that even perfect forecasts would be unlikely to help policymakers. … We nevertheless demonstrate the use of benchmarking with the example of the Intergovernmental Panel on Climate Change’s 1992 linear projection of long-term warming at a rate of 0.03°C-per-year. The small sample of errors from ex ante projections at 0.03°C-per-year for 1992 through 2008 was practically indistinguishable from the benchmark errors. … Again using the IPCC warming rate for our demonstration, we projected the rate successively over a period analogous to that envisaged in their scenario of exponential CO2 growth’”the years 1851 to 1975. The errors from the projections were more than seven times greater than the errors from the benchmark method. Relative errors were larger for longer forecast horizons. Our validation exercise illustrates the importance of determining whether it is possible to obtain forecasts that are more useful than those from a simple benchmark before making expensive policy decisions.
There are many things wrong here:
- Demonstrating that unforced variability (history) can be adequately forecasted by a naive benchmark has no bearing on whether future forced variability will continue to be well-represented, or whether models can predict future emergence of a signal from noise. AG&S’ procedure is like watching an airplane taxi, concluding that aerodynamics knowledge is of no advantage, and predicting that the plane will remain on the ground forever.
- Comparing a naive forecast for global mean temperature against models amounts to a rejection of a vast amount of information. What is the naive forecast for the joint behavior of temperature, preciptiation, lapse rates, sea level, and their spatial and seasonal patterns? These have been evaluated for models, but AG&S do not suggest benchmarks.
- A no-change forecast is not necessarily the best naive forecast for a series with unknown variability, if that series has some momentum or structure which can be exploited to do better. The particular no change forecast selected byAG&S is suboptimal, because it uses a single year as a forecast, unneccesarily projecting annual variation into the future. In general, a stronger naive forecast (e.g., a smoothed value of a few recent years) would strengthen AG&S’ case, so it’s unclear why they’ve chosen an excessively naive benchmark. Fortunately, their base year, 1991, was rather “average”.
- The first exhibit presented is the EPICA ice core temperature. Roughly 85% of the data shown has a time interval too long to show century-scale temperature variations, and none of it could be expected to fully reveal decadal-scale variations, so it’s mostly irrelevant with respect to the kind of forecasts they seek to evaluate.
- The mere fact that a series has unknown historic variability does not mean that it cannot be forecast [corrected 8/18/09]. The EPICA and Vostok CO2 records look qualitatively much like the temperature record, yet CO2 accumulation in the atmosphere is quite predictable over decadal time scales, and models could handily beat a naive forecast.
- AG&S’ method of forecast evaluation unduly weights the short term, like the A&G sucker bet does. This is not strictly a problem, but it does make interpretation of the bounds on AG&S’ alternate forecast (“The benchmark forecast is that the global mean temperature for each year for the rest of this century will be within 0.5°C of the 2008 figure.”) a little tricky.
- The retrospective evaluation of the 1990/1992 IPCC projection of 0.3C/decade ignores many factors. First, 0.3C/decade over a century does not imply a smooth trend over short time scales; models and reality have substantial unforced variability which must be taken into account. The paragraph cited by AG&S includes the statement, “The rise will not be steady because of the influence of other factors.” Second, the 1992 report (in the very paragraph AG&S cite) notes that projections do not account for aerosols, so 0.3C/decade can’t be taken as a point prediction for the future, even if contingency on GHG emissions is resolved. Third, the IPCC projection stated approximate bounds – 0.2 to 0.5 C/decade – that should be accounted for in the evaluation, but are not. Still, the IPCC projection beats the naive benchmark.
- AG&S’ evaluation of the 0.3C/decade future BAU projection as a backcast over 1851-1975 is absurd. They write, “It is not unreasonable, then, to suppose for the purposes of our validation illustration that scientists in 1850 had noticed that the increasing industrialization of the world was resulting in exponential growth in ‘greenhouse gases’ and to project that this would lead to global warming of 0.03°C per year.” Actually, it’s completely unreasonable. Many figures in the 1990 FAR clearly indicate that the 0.3C/decade projection was not valid on [-infinity,infinity]. For example, figures 6, 8, and 9 from the SPM – just a few pages from material cited by AG&S – clearly show a gentle trend <0.05C/decade through 1950. Furthermore, even the most rudimentary understanding of the dynamics of GHG and heat accumulation is sufficient to realize that one would not expect a linear historic temperature trend to emerge from the emissions signal.
How do AG&S arrive at this sorry state? Their article embodies a “sh!t happens” epistemology. They write, “The belief that ‘things have changed’ and the future cannot be judged by the past is common, but invalid.” The problem is, one can say with equal confidence that, “the belief that ‘things never change’ and the past reveals the future is common, but invalid.” In reality, there are predictable phenomena (the orbits of the planets) and unpredictable ones (the fall of the Berlin wall). AG&S have failed to establish that climate is unpredictable or to provide us with an appropriate method for deciding whether it is predictable or not. Nor have they given us any insight into how to know or what to do if we can’t decide. Doing nothing because we think we don’t know anything is probably better than sacrificing virgins to the gods, but it doesn’t strike me as a robust strategy.