I’m increasingly running into machine learning approaches to prediction in health care. A common application is identification of risks for (expensive) infections or readmission. The basic idea is to treat patients like a function approximation problem.
The hospital compiles a big dataset on patient demographics, health status, exposure to procedures, and infection outcomes. A vendor slurps this up and turns some algorithm loose on the data, seeking the risk factors associated with the infection. It might look like this:
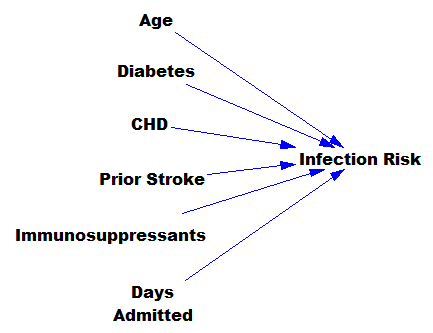
… except that there might be 200 predictors, not six – more than you can handle by eyeballing scatter plots or control charts. Once you have a risk model, you know which patients to target for mitigation, and maybe also which associated factors to pursue further.
However, this is only half the battle. Systems thinkers will recognize this model as a dead buffalo: a laundry list with unidirectional causality. The real situation is rich in feedback, including a lot of things that probably don’t get measured, and therefore don’t end up in the data for consideration by the algorithm. For example:
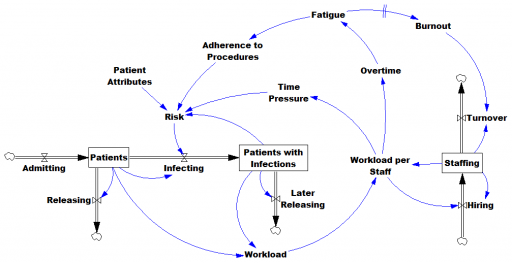
Infections aren’t just a random event for the patient; they happen for reasons that are larger than the patient. Even worse, there are positive feedbacks that can make prevention of infections, and errors more generally, hard to manage. For example, as the number of patients with infections rises, workload goes up, which creates time pressure and fatigue. That induces shortcuts and errors that create risk for patients, leading to more infections. Infections spread to other patients. Fatigued staff burn out and turn over faster, which dilutes the staff experience that might otherwise mitigate risk. (Experience, like many other dynamics, is not shown above.)
An algorithm that predicts risk in this context is certainly useful, because anything that reduces risk helps to diminish the gain of the vicious cycles. But it’s no longer so clear what to do with the patient assessments. Time spent on staff education and action for risk mitigation has to come from somewhere, and therefore might have unintended consequences that aren’t assessed by the algorithm. The algorithm is actually blind in two ways: it can’t respond to any input (like staff fatigue or skill) that isn’t in the data, and it probably isn’t statistically smart enough to deal with the separation of cause and effect in time and space that arises in a feedback system.
Deep learning systems like Alpha Go Zero might learn to deal with dynamics. But so far, high performance requires very large numbers of exemplars for reinforcement learning, and that’s never going to happen in a community hospital dataset. Then again, we humans aren’t too good at managing dynamic complexity either. But until the machines take over, we can build dynamic models to sort these problems out. By taking an endogenous point of view, we can put machine learning in context, refine our understanding of leverage points, and redesign systems for greater performance.