
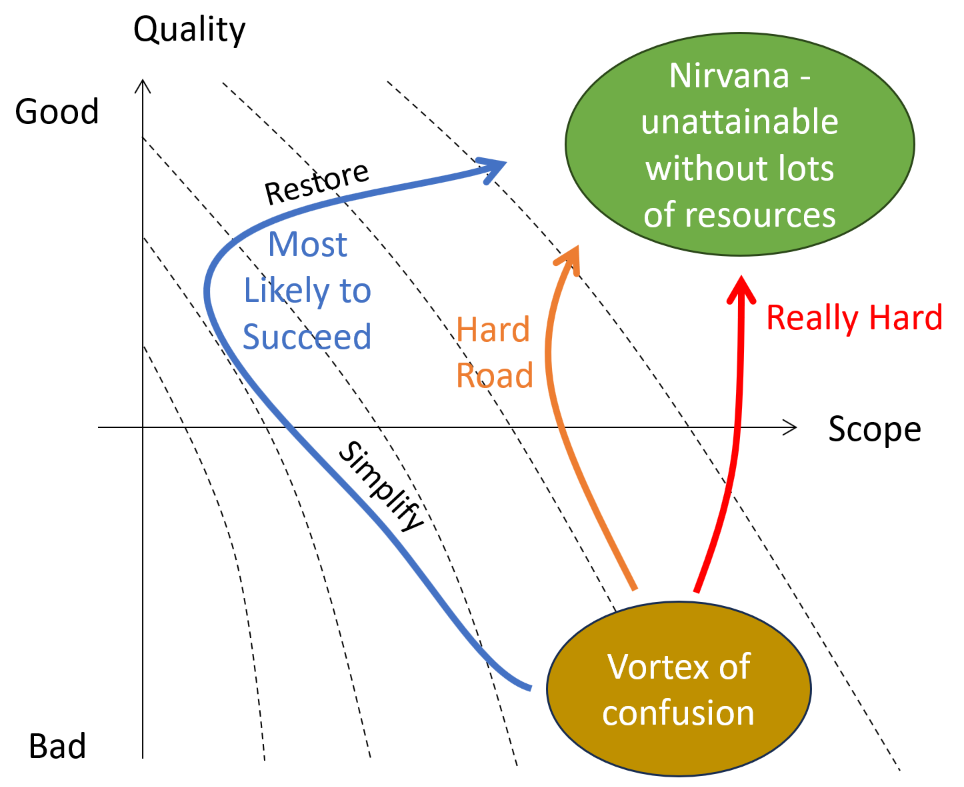
In my high road post a while ago, I advocated “voluntary simplicity” as a way of avoiding a large model with an insurmountable burden of undiscovered rework.
Sometimes this is not a choice, because you’re asked to repurpose a large model for some related question. Maybe you didn’t build it, or maybe you did, but it’s time to pause and reflect before proceeding. It’s critical to determine where on the spectrum above the model lies – between the Vortex of Confusion and Nirvana.
I will assert from experience that a large model was almost always built with some narrow questions in mind, and that it was exercised mainly over parts of its state space relevant to those questions. It’s quite likely that a lot of bad behaviors lurk in other parts of the state space. When you repurpose the model those things are going to bite you.
If you start down the red road, “we’ll just add a little stuff for the new question…” you will find yourself in a world of hurt later. It’s absolutely essential that you first do some rigorous testing to establish what the limitations of the model might be in the new context.
The reason scope is so dangerous is that its effect on your ability to make quality progress is nonlinear. The number of interactions you have to manage, and therefore opportunities for errors, and complexity of corrections, is proportional to scope squared. The speed of your model declines with 1/scope, as does the time you have to pay attention to each variable.
My tentative recipe for success, or at least survival:
1. Start early. Errors beget more errors, so the sooner you discover them, the sooner you can arrest that vicious cycle.
2. Be ruthless. Don’t test to see if the model can answer the new question; test to see if you can break it and get nonsense answers.
3. Use your tools. Pay attention to unit errors and runtime warnings. Write Reality Checks to automate tests. Set ranges on key variables to ensure that they’re within reason.
4. Isolate. Because of the nonlinear interaction problem, it’s hard to interpret tests on a full model. Instead, extract components and test them in isolation. You can do this by copy-pasting, or even easier in Vensim, by using Synthesim Overrides to modify inputs to steps, ramps, etc.
5. Don’t let go. When you find a problem, track it back to its root cause.
6. Document. Keep a lab notebook, or an email stream, or a todo list, so you don’t lose the thought when you have multiple issues to chase.
7. Be extreme. Pick a stock and kick it with a pulse or an override. Take all the people out of the factory, or all the ships out of the fleet. What happens? Does anything go negative? Do decisions remain consistent with goals?
8. Calibrate. Calibration against data can be a useful way to find issues, but it’s much slower than other options, so this is something to pursue late in the process. Also, remember that model-data gaps are equally likely to reveal a problem with the data.
9. Rebuild. If you’re finding a lot of problems, you may be better of starting clean, using the existing model as a conceptual guide, but reconsidering the detailed design of the implementation.
10. Submodel. It’s often hard to fix something inside the full plate of spaghetti. But you may be able to identify a solution in an external submodel, free of distractions, and then transplant it back into the host.
11. Reduce. If you can’t rebuild the full scope within available resources, cut things out. This may not be appetizing to the client, but it’s certainly better than delivering a fragile model that only works if you don’t touch it.
12. If you find you’re in a hole, stop digging. Don’t add any features until you have things under control, because they’ll only exacerbate the problems.
13. Communicate. Let the client, and your team, know what you’re up to, and why quality is more important than their cherished kitchen sink.

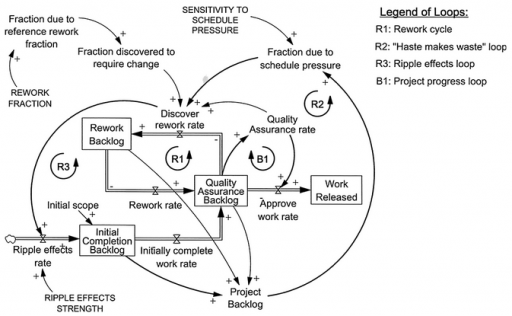
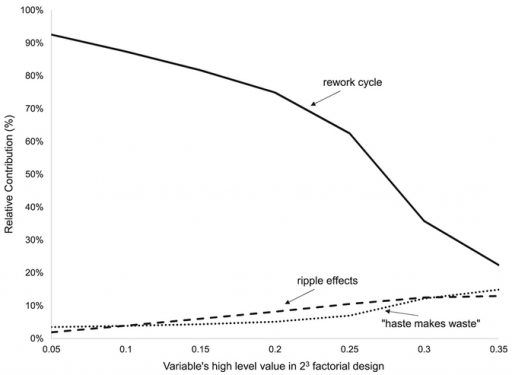
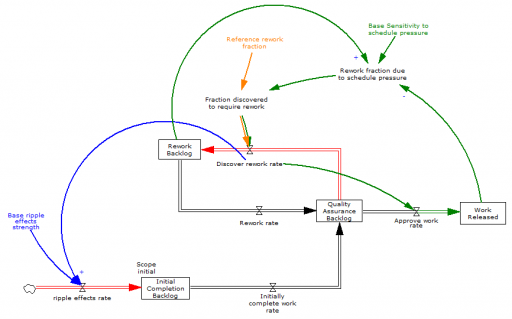




 Normal+uniformly-distributed uncertainty in project estimation, productivity and ripple/rework effects generates a lognormal-ish left tail (parabolic on the log-log axes above) and a heavy Power Law right tail.
Normal+uniformly-distributed uncertainty in project estimation, productivity and ripple/rework effects generates a lognormal-ish left tail (parabolic on the log-log axes above) and a heavy Power Law right tail.

