Don't just do something, stand there! Reflections on the counterintuitive behavior of complex systems, seen through the eyes of System Dynamics, Systems Thinking and simulation.
I’ve recently run across an interesting example. I’m working on Chronic Wasting Disease in deer, which essentially combines an epidemiology model with a deer population model, surrounded by some social and environmental features.
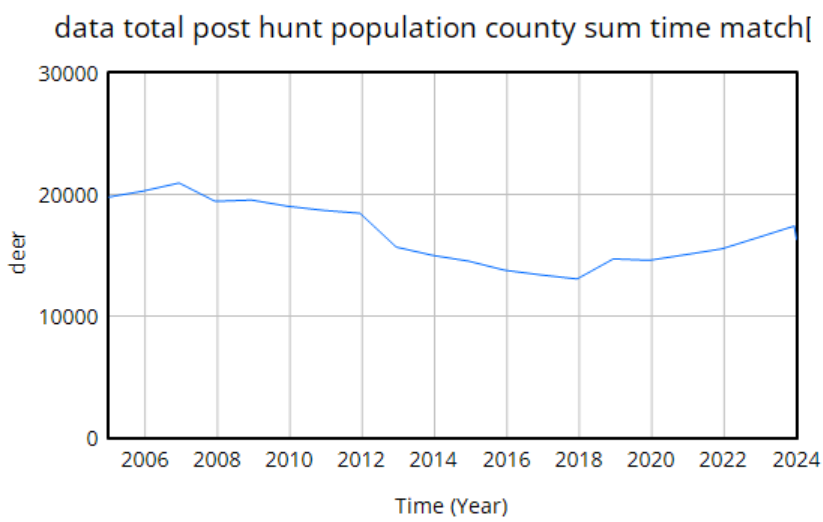
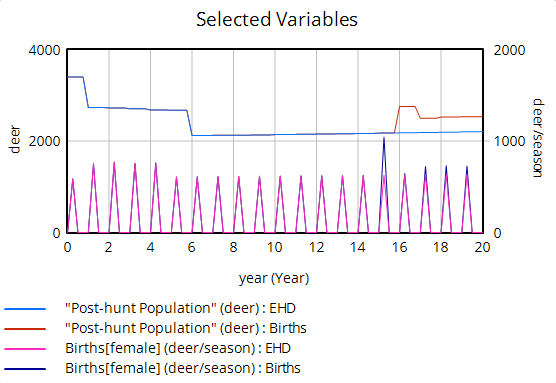
We use data heavily. The model is driven by hunter harvest and targeted removals of deer, which are fairly reliable measurement streams with long histories. We calibrate primarily against surveillance (positive CWD tests) and population data. The surveillance is very noisy because sample sizes are small, but as far as we know it’s fairly free of big systematic problems. The population data is more aggregate and less noisy. It typically looks like this:
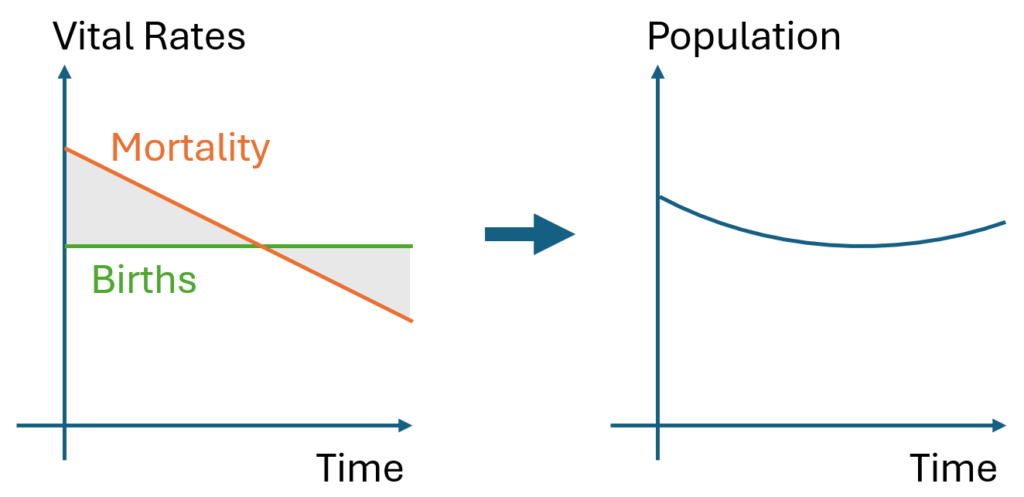
The U-shaped pattern here is intuitively attractive, because it’s doing bathtub dynamics. Population integrates the difference between births and deaths (shaded area, left plot – or really its negative). In reality mortality is declining (due to declining hunting pressure), so a population that declines early, levels off, and later grows is a plausible outcome.
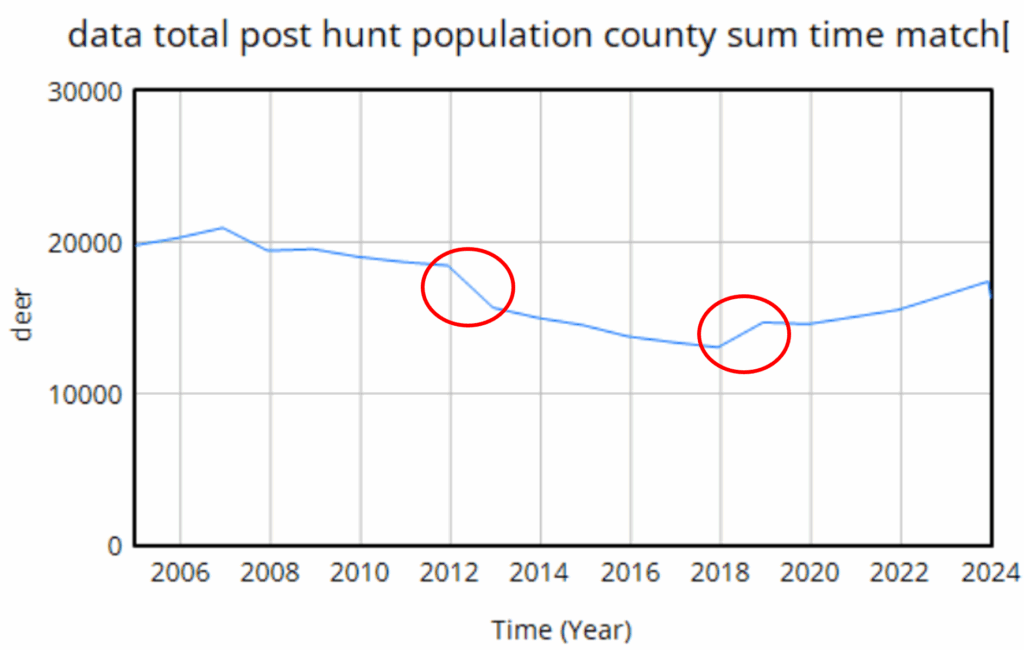
However … it proves difficult to replicate this trajectory with realistic parameters. Part of the problem is that there are two discontinuities:
The first one is real – it’s an EHD outbreak that caused widespread mortality. That can easily be captured in the model with an exogenous event. The second one though turns out to be a change in methods, and that’s the real problem here. This deer “data” isn’t really data, it’s an accounting model with its own assumptions. Really there’s no such thing as pure data – it’s always captured through some kind of process that is effectively a model. But in this case, the model is problematic, because it changed in 2018, and we don’t know how.
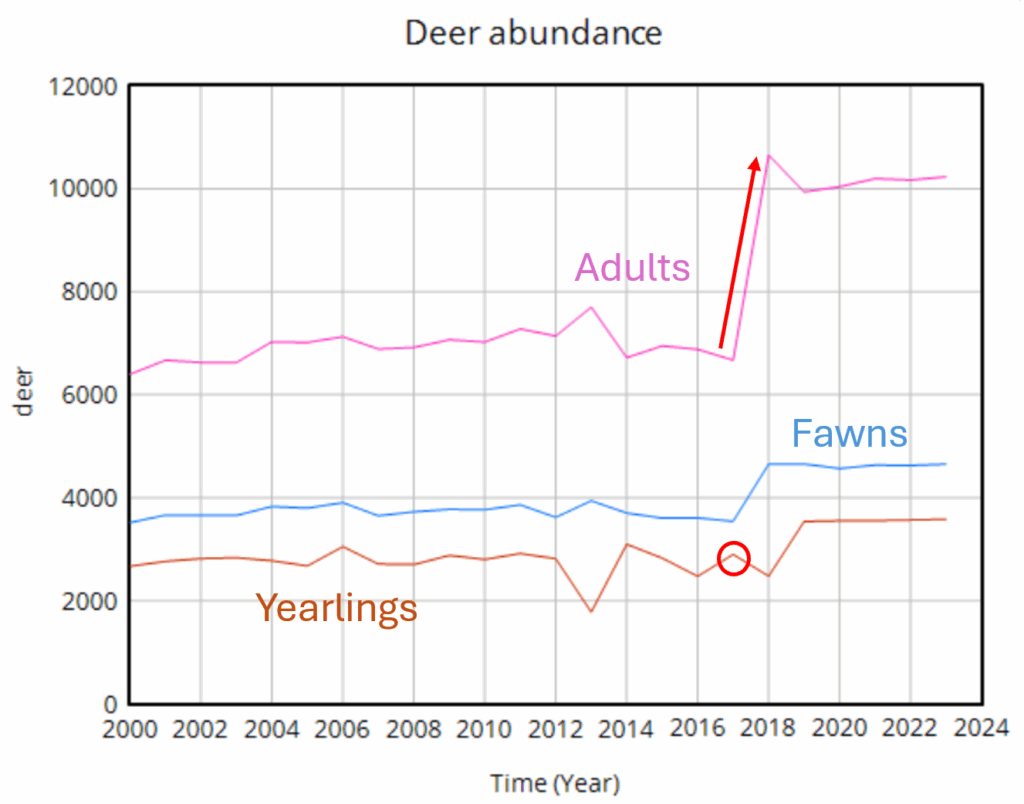
We do know it’s wrong though. Difficulty tuning a model to the data led us look into the details of the age structure, and it’s problematic. Here’s an adjacent county:
Deer populations have age structures. Fawns are born, in a year they mature into (surprise!) yearlings, and in another year they mature to adults. So this year’s yearlings are next year’s adults. But in the plot above, the increase in the adult data is about 4000 deer (red arrow), while the total yearling population aging into the adult category is about 3000. So the adult trajectory is simply impossible without negative mortality or an alien airdrop of 1000 extra deer into the county. Obviously this is an artifact of the methods change.
Once you’re aware of the age structure issue, other questionable features of the population data surface. For example, if you impose a one-year birth bonanza on a reduced form model, you see that births can’t produce a simple monotonic jump in population.
Instead, population spikes up, but falls back almost halfway to its initial level. This is because the spike of new fawns doesn’t immediately produce more births; fawns have a very low birth rate, so they have to mature through yearlings to adults before they make a substantial contribution to future population. Again if you look into the age structure, you can see these effects:
The bottom line is that abrupt increases in population are not very plausible – the dynamics just impose too many constraints.
In this modeling project, that means we’re in a bit of a pickle. Population dynamics have important interactions with CWD, but we don’t have reliable population measurements. The only option left to us is to do a lot of scenario analysis to try to capture the uncertain effects of various plausible trajectories.
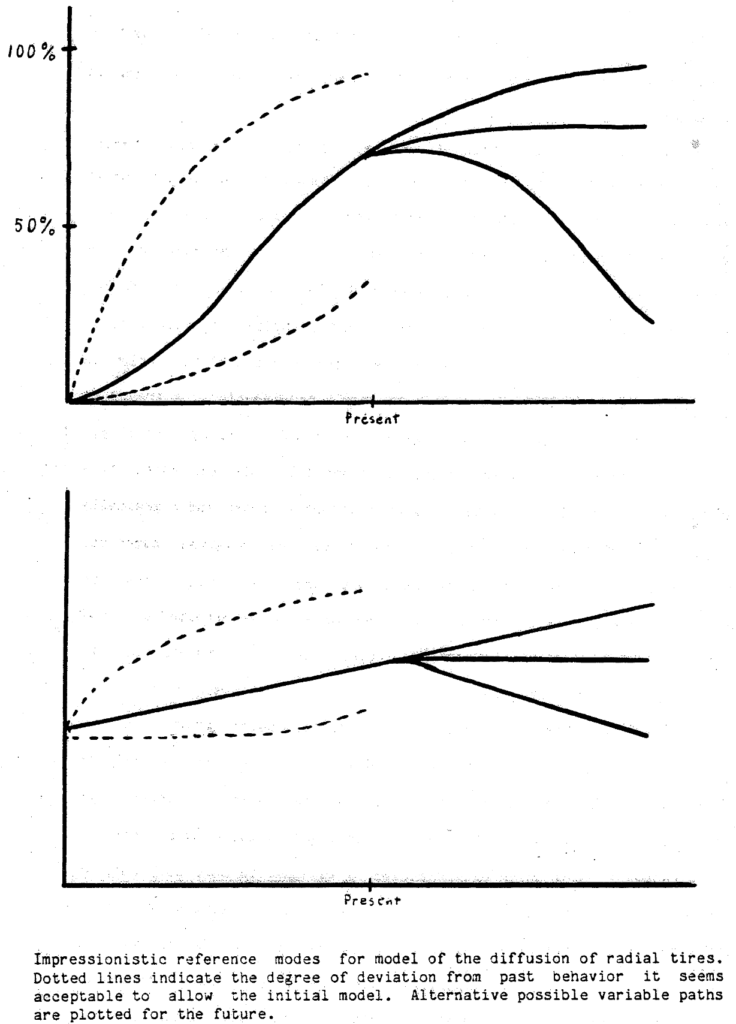
I often run across interesting time series that make good reference mode diagrams. Reference modes, in System Dynamics jargon, are plots that “neatly summarize the real-world problem behavior that motivated a model” (VanderWerf, 1981). There’s a lot of variation in practice, but drawing reference modes is often a nice way to get started on model conceptualization, particularly in a group model building session.
My typical practice is to get participants to identify some key variables that they think are of interest in their system, and then generate some time series plots of history, what they think will happen in the future, bounded by what they hope or fear may happen. VanderWerf has a nice example:
I have one quibble with this: the axes should be labeled with a real time horizon, variable name, and units of measure. This last point is critical for establishing good habits early.
There’s often real data as a starting point, but capturing participants’ “impressionistic” reference modes is often revealing. When you collect the data that ought to underlie those, you might learn (a) that participants’ impressions are wrong (revealing something about their mental models), or (b) that the data are wrong in some sense, either due to measurement and interpretation problems, or because the chosen variables aren’t really the key drivers of a problem. Either way, this is valuable information.
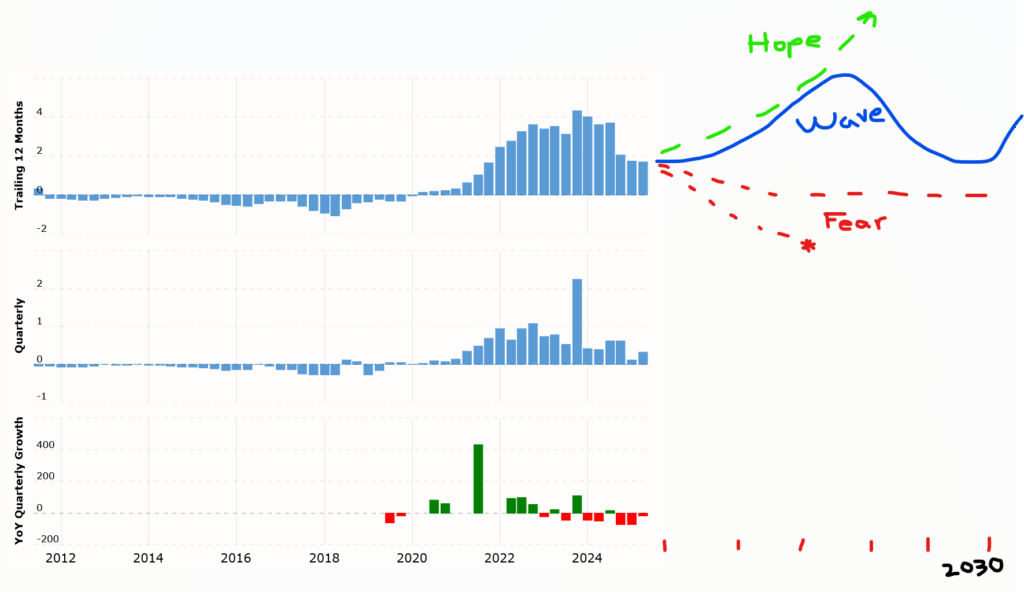
If you have the data to hand, you can still use it effectively for conceptualization. Here’s an example:
This is TSLA earnings per share in $/share (or YOY growth at bottom), with my markup on the first plot. Looking at this abstractly, it’s tempting to view it as some kind of logistic growth or overshoot-and-collapse dynamic, in which case one might fear (red) the extrapolation to negative earnings and bankruptcy, or at least something like mild decline or persistence of the status quo (which is roughly what yesterday’s earnings did). However, the stock market clearly hopes (green) for something else: the PE ratio in the hundreds indicates an expectation of resumed exponential growth to well above 10x recent earnings. One might also notice some cyclical peaks and troughs and hypothesize future oscillations (blue).
I’m not putting a stake in the ground as to which of these will happen, but I think this is a nice illustration of the first point of Khalid Saeed’s policy space concept: if your model can’t capture both the hope and the fear scenarios, “The problem definition might be linked too intimately to a preferred rather than a competing set of manifestations, hence the model it creates has no way to transform behavior to an alternative manifestation.” You won’t be able to use the model to discriminate among competing predictions, or to talk to people with different beliefs about the future or response to intervention.
This war must have shewn to all, but to military men in particular the weakness of republicks, & the exertions the army has been able to make by being under a proper head, therefore I little doubt, when the benefits of a mixed government are pointed out & duly considered, but such will be readily adopted; in this case it will, I believe, be uncontroverted that the same abilities which have lead us, through difficulties apparently unsurmountable by human power, to victory & glory, those qualities that have merited & obtained the universal esteem & veneration of an army, would be most likely to conduct & direct us in the smoother paths of peace.
Some people have so connected the ideas of tyranny & monarchy as to find it very difficult to seperate them, it may therefore be requisite to give the head of such a constitution as I propose, some title apparently more moderate, but if all other things were once adjusted I believe strong arguments might be produced for admitting the title of king, which I conceive would be attended with some material advantages.
With a mixture of great surprise & astonishment I have read with attention the Sentiments you have submitted to my perusal. Be assured, Sir, no occurrence in the course of the War, has given me more painful sensations than your information of there being such ideas existing in the Army as you have expressed, & I must view with abhorrence, and reprehend with severity—For the present, the communicatn of them will rest in my own bosom, unless some further agitation of the matter, shall make a disclosure necessary.
I am much at a loss to conceive what part of my conduct could have given encouragement to an address which to me seems big with the greatest mischiefs that can befall my Country. If I am not deceived in the knowledge of myself, you could not have found a person to whom your schemes are more disagreeable—at the same time in justice to my own feeling I must add, that no man possesses a more sincere wish to see ample Justice done to the Army than I do, and as far as my powers & influence, in a constitution[al] way extend, they shall be employed to the utmost of my abilities to effect it, should there be any occasion—Let me [conj]ure you then, if you have any regard for your Country, concern for your self or posterity—or respect for me, to banish these thoughts from your Mind, & never communicate, as from yourself, or any one else, a sentiment of the like nature. With esteem I am Sir Yr Most Obedt Servt
To the efficacy and permanency of your Union, a Government for the whole is indispensable. No alliances, however strict, between the parts can be an adequate substitute; they must inevitably experience the infractions and interruptions, which all alliances in all times have experienced. Sensible of this momentous truth, you have improved upon your first essay, by the adoption of a Constitution of Government better calculated than your former for an intimate Union, and for the efficacious management of your common concerns. This Government, the offspring of our own choice, uninfluenced and unawed, adopted upon full investigation and mature deliberation, completely free in its principles, in the distribution of its powers, uniting security with energy, and containing within itself a provision for its own amendment, has a just claim to your confidence and your support. Respect for its authority, compliance with its laws, acquiescence in its measures, are duties enjoined by the fundamental maxims of true Liberty. The basis of our political systems is the right of the people to make and to alter their Constitutions of Government. But the Constitution which at any time exists, till changed by an explicit and authentic act of the whole people, is sacredly obligatory upon all. The very idea of the power and the right of the people to establish Government presupposes the duty of every individual to obey the established Government.
All obstructions to the execution of the Laws, all combinations and associations, under whatever plausible character, with the real design to direct, control, counteract, or awe the regular deliberation and action of the constituted authorities, are destructive of this fundamental principle, and of fatal tendency. They serve to organize faction, to give it an artificial and extraordinary force; to put, in the place of the delegated will of the nation, the will of a party, often a small but artful and enterprising minority of the community; and, according to the alternate triumphs of different parties, to make the public administration the mirror of the ill-concerted and incongruous projects of faction, rather than the organ of consistent and wholesome plans digested by common counsels, and modified by mutual interests.
However combinations or associations of the above description may now and then answer popular ends, they are likely, in the course of time and things, to become potent engines, by which cunning, ambitious, and unprincipled men will be enabled to subvert the power of the people, and to usurp for themselves the reins of government; destroying afterwards the very engines, which have lifted them to unjust dominion.
Towards the preservation of your government, and the permanency of your present happy state, it is requisite, not only that you steadily discountenance irregular oppositions to its acknowledged authority, but also that you resist with care the spirit of innovation upon its principles, however specious the pretexts. One method of assault may be to effect, in the forms of the constitution, alterations, which will impair the energy of the system, and thus to undermine what cannot be directly overthrown. In all the changes to which you may be invited, remember that time and habit are at least as necessary to fix the true character of governments, as of other human institutions; that experience is the surest standard, by which to test the real tendency of the existing constitution of a country; that facility in changes, upon the credit of mere hypothesis and opinion, exposes to perpetual change, from the endless variety of hypothesis and opinion; and remember, especially, that, for the efficient management of our common interests, in a country so extensive as ours, a government of as much vigor as is consistent with the perfect security of liberty is indispensable. Liberty itself will find in such a government, with powers properly distributed and adjusted, its surest guardian. It is, indeed, little else than a name, where the government is too feeble to withstand the enterprises of faction, to confine each member of the society within the limits prescribed by the laws, and to maintain all in the secure and tranquil enjoyment of the rights of person and property.
I have already intimated to you the danger of parties in the state, with particular reference to the founding of them on geographical discriminations. Let me now take a more comprehensive view, and warn you in the most solemn manner against the baneful effects of the spirit of party, generally.
This spirit, unfortunately, is inseparable from our nature, having its root in the strongest passions of the human mind. It exists under different shapes in all governments, more or less stifled, controlled, or repressed; but, in those of the popular form, it is seen in its greatest rankness, and is truly their worst enemy.
The alternate domination of one faction over another, sharpened by the spirit of revenge, natural to party dissension, which in different ages and countries has perpetrated the most horrid enormities, is itself a frightful despotism. But this leads at length to a more formal and permanent despotism. The disorders and miseries, which result, gradually incline the minds of men to seek security and repose in the absolute power of an individual; and sooner or later the chief of some prevailing faction, more able or more fortunate than his competitors, turns this disposition to the purposes of his own elevation, on the ruins of Public Liberty.
Without looking forward to an extremity of this kind, (which nevertheless ought not to be entirely out of sight,) the common and continual mischiefs of the spirit of party are sufficient to make it the interest and duty of a wise people to discourage and restrain it.
It serves always to distract the Public Councils, and enfeeble the Public Administration. It agitates the Community with ill-founded jealousies and false alarms; kindles the animosity of one part against another, foments occasionally riot and insurrection. It opens the door to foreign influence and corruption, which find a facilitated access to the government itself through the channels of party passions. Thus the policy and the will of one country are subjected to the policy and will of another.
There is an opinion, that parties in free countries are useful checks upon the administration of the Government, and serve to keep alive the spirit of Liberty. This within certain limits is probably true; and in Governments of a Monarchical cast, Patriotism may look with indulgence, if not with favor, upon the spirit of party. But in those of the popular character, in Governments purely elective, it is a spirit not to be encouraged. From their natural tendency, it is certain there will always be enough of that spirit for every salutary purpose. And, there being constant danger of excess, the effort ought to be, by force of public opinion, to mitigate and assuage it. A fire not to be quenched, it demands a uniform vigilance to prevent its bursting into a flame, lest, instead of warming, it should consume.
It is important, likewise, that the habits of thinking in a free country should inspire caution, in those intrusted with its administration, to confine themselves within their respective constitutional spheres, avoiding in the exercise of the powers of one department to encroach upon another. The spirit of encroachment tends to consolidate the powers of all the departments in one, and thus to create, whatever the form of government, a real despotism. A just estimate of that love of power, and proneness to abuse it, which predominates in the human heart, is sufficient to satisfy us of the truth of this position. The necessity of reciprocal checks in the exercise of political power, by dividing and distributing it into different depositories, and constituting each the Guardian of the Public Weal against invasions by the others, has been evinced by experiments ancient and modern; some of them in our country and under our own eyes. To preserve them must be as necessary as to institute them. If, in the opinion of the people, the distribution or modification of the constitutional powers be in any particular wrong, let it be corrected by an amendment in the way, which the constitution designates. But let there be no change by usurpation; for, though this, in one instance, may be the instrument of good, it is the customary weapon by which free governments are destroyed. The precedent must always greatly overbalance in permanent evil any partial or transient benefit, which the use can at any time yield.
I’m working on Chronic Wasting Disease in deer in a couple US states. One interesting question is, what have historical management actions actually done to mitigate prevalence and spread of the disease?
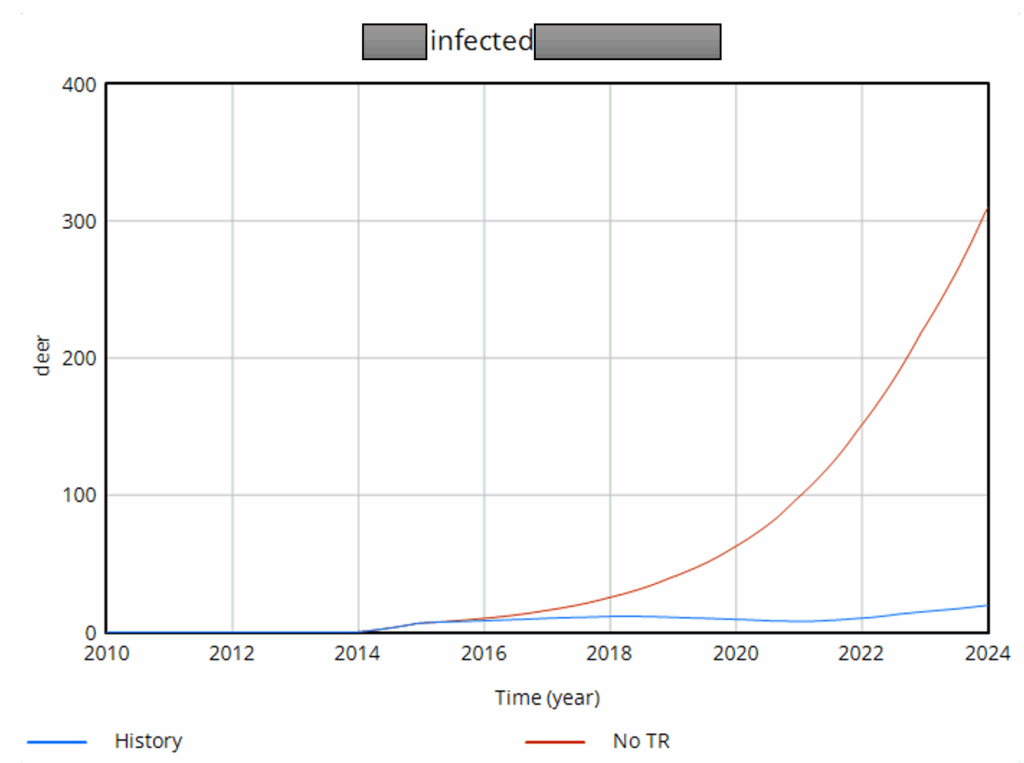
We think we have pretty strong evidence that targeted removals and increased harvest of antlerless deer (lowering population density) have a substantial effect, though not many regions have been able to fully deploy these measures. Here’s one that’s been highly effective:
… and here’s one that’s less successful, due to low targeted removal rates and a later start:
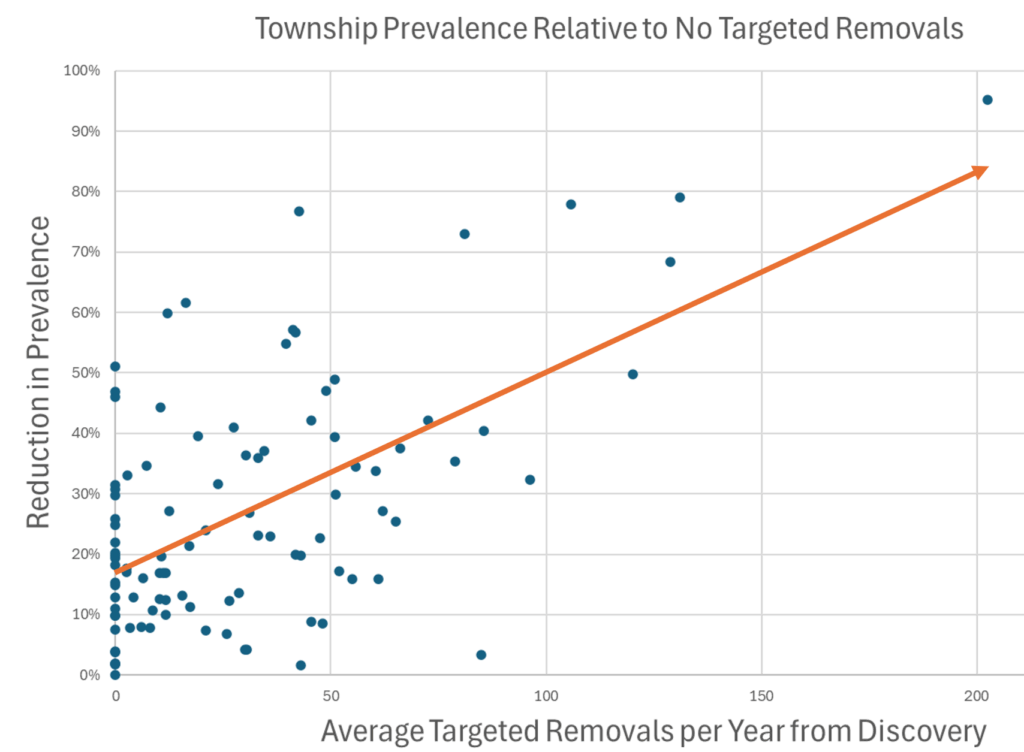
When you look at the result across lots of regions, there’s a clear pattern. More removals = lower prevalence, and even regions that received no treatment benefited due to geographic spillovers from deer dispersal.
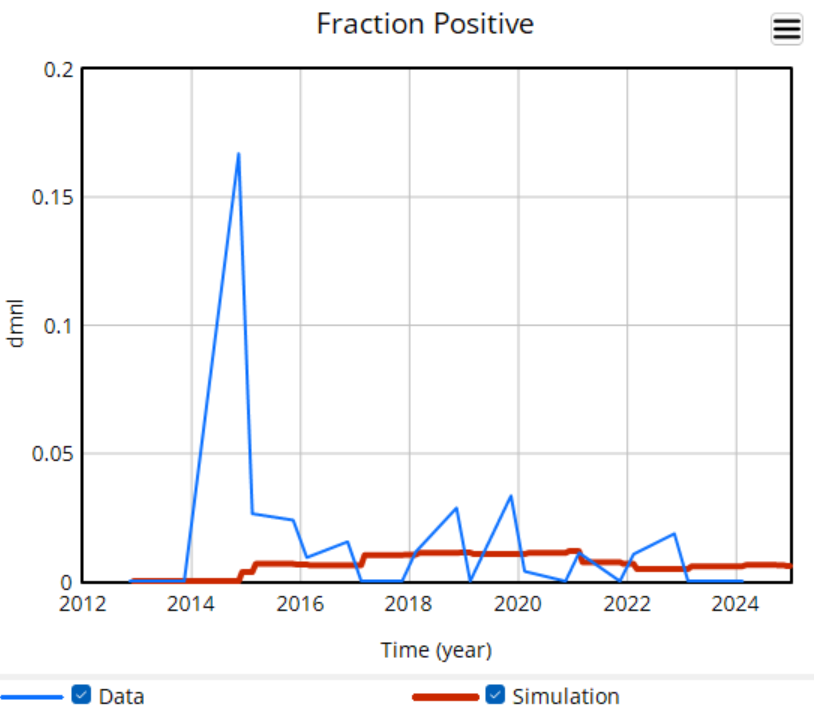
There’s a challenge with these results though: they’re all from simulations. There’s a good reason for that: most of the raw data is too noisy to be informative. Here’s some of the better data we have:
The noise in the data is inherent in sampling processes, and here it’s exacerbated by the fact that the sample size is small and varying a lot. The initial spike, for example, is a lucky discovery of 2 positive deer in a sample of 12. This makes it almost impossible to do sensible eyeball comparisons between regions in the raw data, and of course the data doesn’t include counterfactuals.
The model does do counterfactuals, but as soon as you show simulated results, you have a hill to climb. You have to explain what a model is and does, and what’s in the particular model in use. Some people may be skeptical (wrongly) of the very idea of a model. You may not have time for these conversations. So, one habit I’ve picked up from Ventana is to use the model result as a guide for where to look for compelling data that cleanly illustrates what the model is doing.
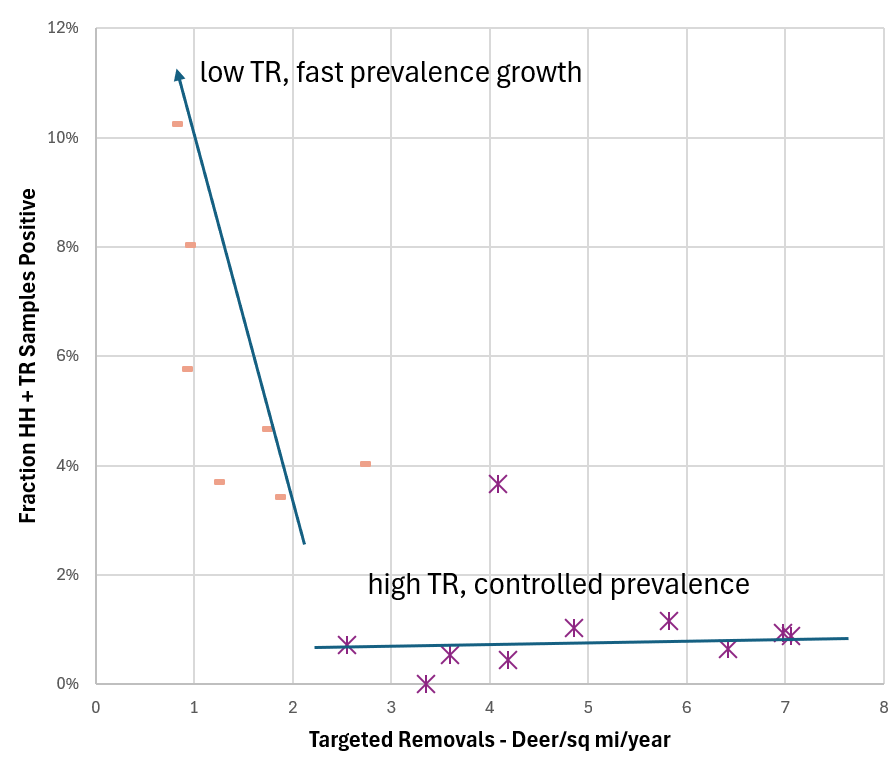
It turns out there is some in this case. Here are the histories of two regions that received different CWD management treatments, and had wildly different outcomes:
There are still some assumptions here – any interpretation of data is really a model – but I think this view is skeptic-resistant. It’s still not ideal, because scatterplots are less widely understood than time series plots, but I think it’s a useful complement to the simulation model results.
Subjectivity in Model Design: Model boundaries, assumptions, and relationships are defined by modelers, which can introduce bias or limit the model’s applicability. [See Dana Meadows’ Unavoidable A Priori.]
Difficulty in Validation: Validating SD models is challenging, especially for long-term predictions, as real-world systems evolve unpredictably, and historical data may not suffice. [What method doesn’t have this problem, other than trivial ones that are easy to reject?]
Computational Complexity: Large SD models can be computationally intensive, making them difficult to scale or analyze in real-time scenarios. [Yep.]
Limited Predictive Power: SD is better suited for understanding system behavior than precise forecasting, as it struggles with chaotic or highly stochastic systems. [Nope.]
Misinterpretation Risk: Non-experts may misinterpret model outputs, assuming deterministic results rather than recognizing them as scenarios or trends. [True, but hardly unique to SD. See Communicating uncertainty and policy sensitivity]
Neglect of Discrete Events: SD focuses on continuous processes, which may inadequately capture discrete events or abrupt changes in systems. [Common, but not a requirement, even in the early days of SD.]
Resistance to Interdisciplinary Integration: Some critics argue SD struggles to integrate with other modeling approaches (e.g., agent-based modeling), limiting its flexibility. [It might be a struggle, but I don’t think deliberate resistance is the issue.]
Overemphasis on Feedback Loops: While feedback loops are central to SD, overfocusing on them can downplay external drivers or one-off events impacting the system. [Consider George Richardson’s endogenous point of view.]
These critiques highlight the need for careful model design, validation, and clear communication of limitations when using SD. Would you like me to dive deeper into any specific critique?
Both Stella and Vensim draw conveyors incorrectly, in different ways.
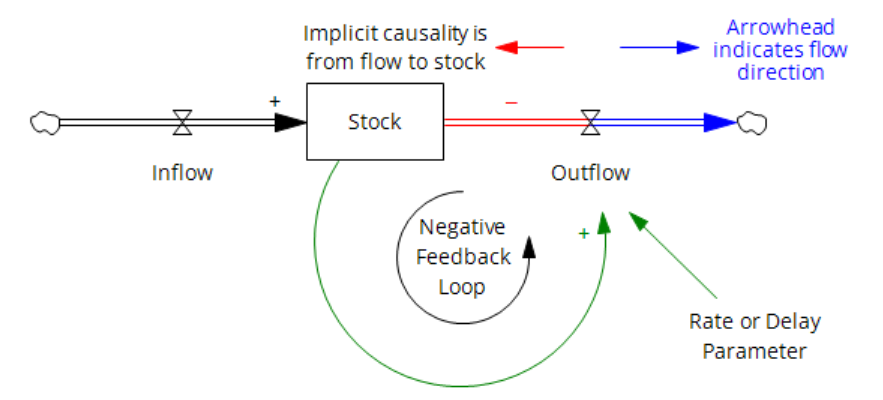
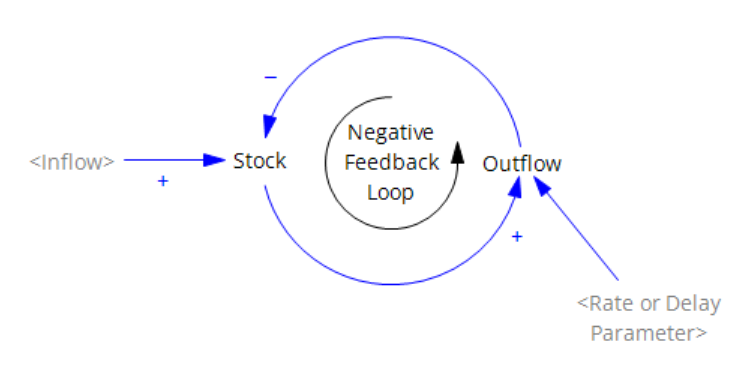
In part, the challenges arise from the standard SD convention for stock-flow diagramming. Consider the stock-flow structure above and its CLD equivalent below.
The CLD version has its own problems, but the stock-flow version is potentially baffling to novices because the arrowhead convention for flow pipes differs from an information arrow in its representation of causality. The arrowhead indicates the direction of material flow, which is the opposite of the direction of causality or information. In Stella, there may be a “shadow” arrowhead in the negative-flow direction, but this doesn’t really help – the concept of flow direction (bidirectional vs. unidirectional) is still confounded with causality (always flow->stock).
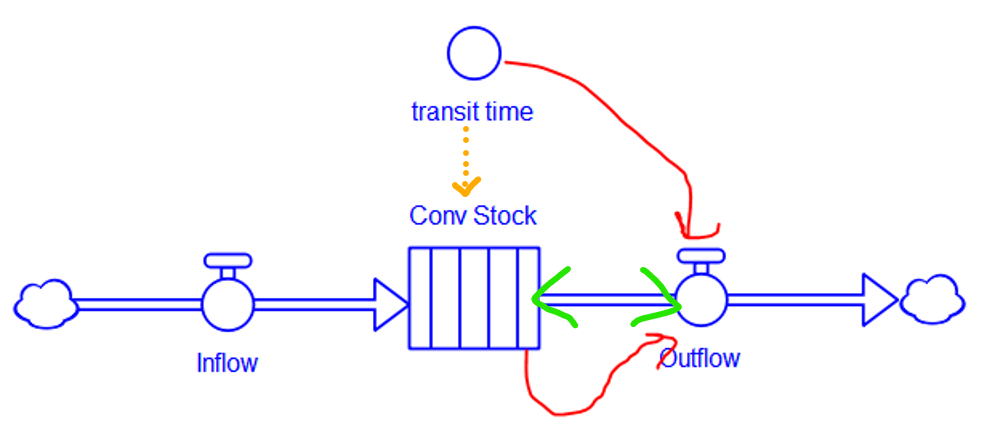
When the stock is a conveyor, the problems deepen.
In Stella, the conveyor has a distinct icon, which is good. It indicates that the stock is divided into internal compartments (which are essentially slats of TIME STEP aka DT duration, rendering the object higher-order than a normal stock). However, the transit time is a property setting in the stock dialog, implying the orange arrow, which can’t properly be drawn because stocks don’t normally have dynamic information arrow inputs, and transit time could potentially change during the simulation. The segment of flow pipe between the stock and outflow is now further overloaded, because it represents both the “expiration” of stock contents due to exceedance of transit time (i.e. reaching the end of the conveyor) and the old causal interpretation, that the outflow reduces the stock (green arrowheads). While the code is correct, the diagram fails to indicate that the outflow is a consequence of the stock contents and transit time. I think the user would be much better served by the conventional diagram approach (red arrows).
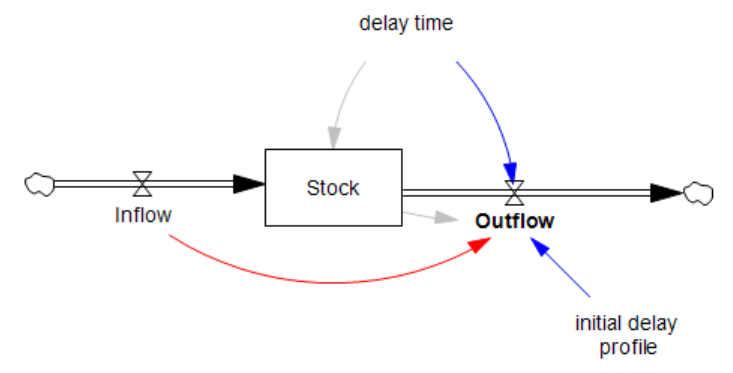
In Vensim, the conveyor is not really a distinct object in the language, which makes things better in one respect but worse in several others. The conveyor really lives in a function, DELAY CONVEYOR, which is used in the outflow. This means that the connection between the delay time parameter is properly both dynamic (for determining the outflow) and static (for initialization of the stock). However, the initial delay profile parameter is connected to the flow, not the stock, which is weird – this is because the stock is actually an accounting variable that is needed to keep track of the conveyor contents, rather than an actual dynamic participant in the structure, hence the lack of an arrow from stock to flow, except for initialization (gray). This convention also requires the oddity of a flow-to-flow connection (red) which is normally a no-no.
Similar problems exist for leakage flows, but I won’t detail those.
My conclusion is that both approaches are flawed. They both work mathematically, but neither portrays what’s really going on for the diagram viewer. We’ll get it right in a forthcoming version of Ventity, and maybe improve Vensim at some point.
The significant or well-known criticisms of system dynamics include:
William Nordhaus, Measurement without Data (The Economic Journal, 83,332; Dec. 1973) [Nordhaus objects to the fact that Forrester seriously proposes a world model fit to essentially only two data points. He simplifies the model to help him analyze it, carries through some investigations that cause him to doubt the model, and makes the mistake of critiquing a univariate relation (effect of material standard of living on births) using multivariate real world data — the real-world data has all the other influences in the system at work, while Nordhaus wants to pull out just the effect of standard of living). Sadly, a very influential critique in the economics literature.]
Joseph Weizenbaum, Computer Power and Human Reason (W.H. Freeman, 1976). [Weizenbaum, a professor of computer science at MIT, was the author of the speech processing and recognition program ELIZA. He became very distressed at what people were proposing we could do with computers (e.g., use ELIZA seriously to counsel emotionally disturbed people), and wrote this impassioned book about what in his view computers can do well and what they cant. Contains sections on system dynamics in various places and finds Forrester’s claims for the approach to be too broad and, like Herbert Simon’s, “very simple.”]
Robert Boyd, World Dynamics: A Note (Science, 177, August 11, 1972). [Boyd’s very original and interesting critique of World Dynamics tries to use Forrester’s model itself to argue that World Dynamics did not solve the essential question about limits to growth — whether technology can avert the limits explicitly assumed in World Dynamics and the Limits to Growth models. Boyd adds a Technology level to World Dynamics and incorporates four effects on things like pollution generated per capita, and finds that one can incorporate assumptions in the model that make the problem go away. Unfortunately for his argument, Boyd’s additions are extremely sensitive to particular parameter values and he unrealistically assumes things like the second law of thermodynamics doesn’t apply. We used to give this as an exercise: step 1 — build Boyd’s additions into Forrester’s model and investigate; step 2 — incorporate Boyd’s assumptions in Forrester’s original model just by changing parameters; step 3 — reflect on what you’ve learned. Still a great exercise.]
These are all rather ancient, “classical” critiques. I am not really familiar with current critiques, either because they exist but have not come to my attention or because they are few and far between. If the latter, that could be because we are doing less controversial work these days or because the critics think we’re not really a threat anymore.
I hope we’re still a threat.
…GPR
George P. Richardson Rockefeller College of Public Affairs and Policy, SUNY, Albany
I’ll add a few more when I get a chance. These critiques really concern World Dynamics and the Limits to Growth rather than SD per se, but many have thrown the baby out with the bathwater. Some of these critiques have not aged well. But some are also still true. For example, Solow’s critique of World Dynamics starts with the absence of a price system, and Boyd’s critique center’s on the absence of technology. There are lots of SD models with prices and technology in them, but there isn’t really a successor to World Dynamics or World3 that does a good job of addressing these critiques. At the same time, I think it’s now obvious that neither prices nor technology has brought stability to the environment and resources.
The second practice we need to exercise great care in executing is the purveyance of “Systems Archetypes” (Senge, 1990). The care required becomes multiplied several-fold when these archetypes are packaged for consumption via causal loop diagrams. Again, to me, one of the major “problems” with System Dynamics was the “we have a way to get the wisdom, we’ll get it, then we’ll share it with you” orientation. I feel that Systems Thinking should be about helping to build people’s capacity for generating wisdom for themselves. Though I believe that Senge offered the archetypes in this latter spirit, too many people are taking them as “revealed truth,” looking for instances of that truth in their organizations (i.e., engaging in what amounts to a “matching exercise”), and calling this activity Systems Thinking. It isn’t. I have encountered many situations in which the result of pursuing this approach has left people feeling quite disenchanted with what they perceive Systems Thinking to be. This is not a “cheap shot” at Peter. His book has raised the awareness with respect to Systems Thinking for many people around the globe. However, we all need to exercise great caution in the purveyance of Systems Archetypes – in particular when that purveyance makes use of causal loop diagrams.
I’ve seen the problem of the “matching exercise” in classroom settings but not real projects. In practical settings, I do see some utility to the use of archetypes as a compact way to communicate among people familiar with the required systems lingo. In my view the real challenge is that archetypes are underspecified (compared to a simulation model), and therefore ambiguous. You can’t really tell by looking at the structure of a CLD what behavior will emerge. However, if you simulate a model, you might quickly realize, “hey, this is eroding goals” which could convey a whole package of ideas to your systems-aware colleagues.