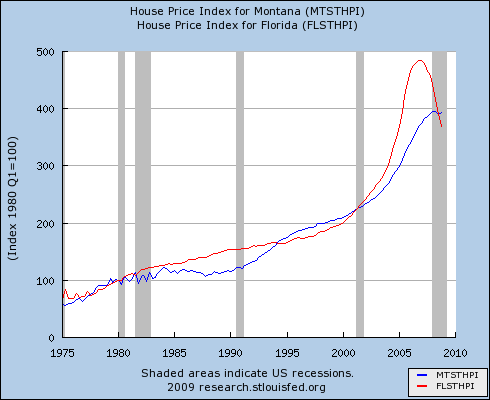
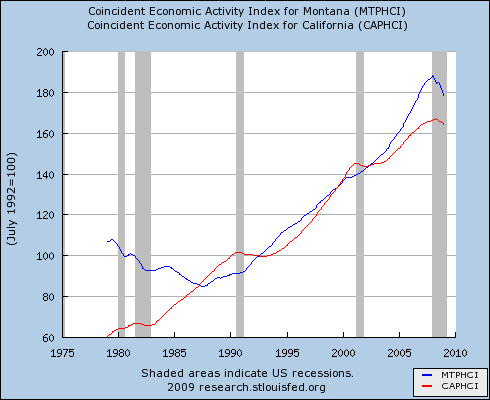
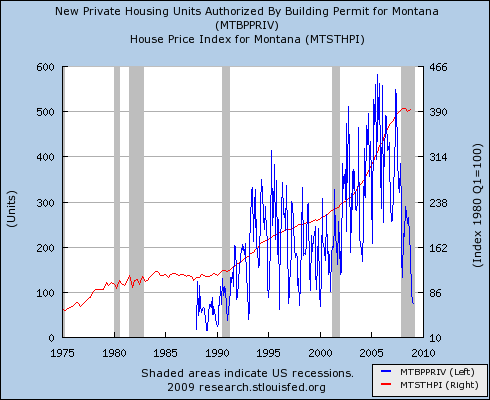
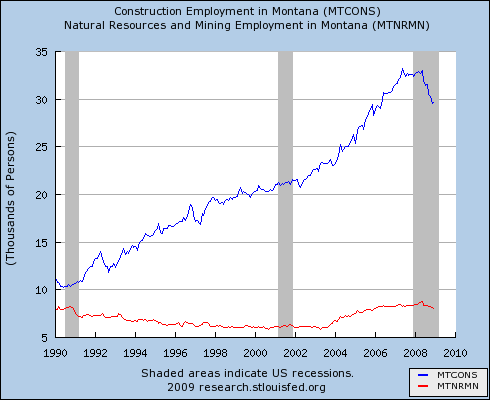
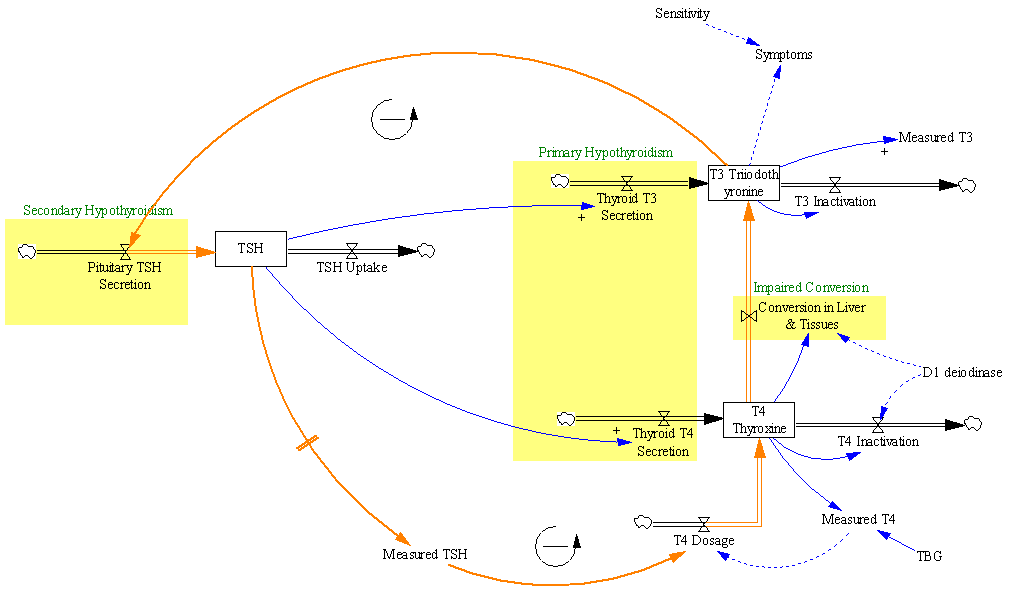
I caught up with my email just after my last post, which questioned the role of the real economy in the current financial crisis. I found this in my inbox, by Thomas Friedman, currently the most-emailed article in the NYT:
Let’s today step out of the normal boundaries of analysis of our economic crisis and ask a radical question: What if the crisis of 2008 represents something much more fundamental than a deep recession? What if it’s telling us that the whole growth model we created over the last 50 years is simply unsustainable economically and ecologically and that 2008 was when we hit the wall ’” when Mother Nature and the market both said: ‘No more.’
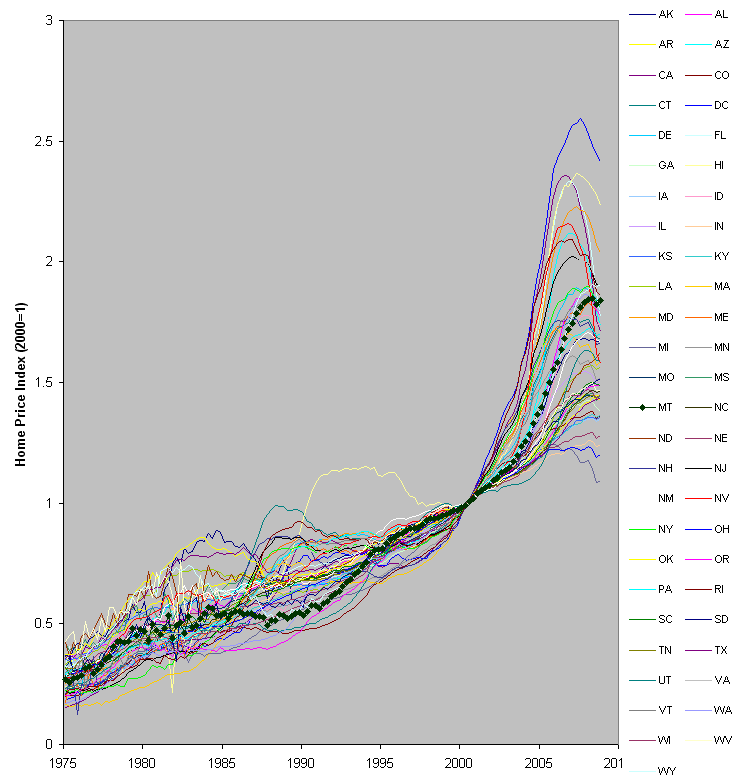
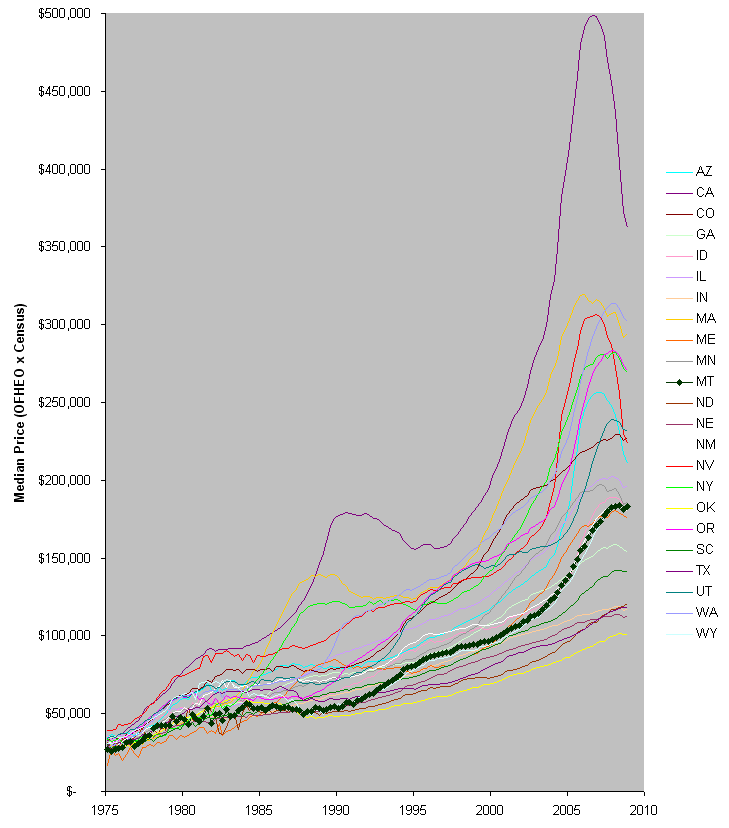
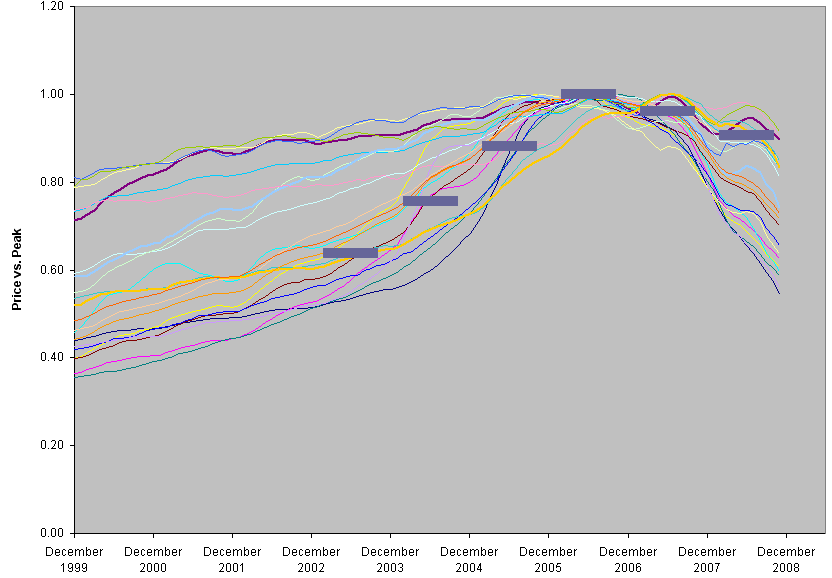
Certainly there are some parallels between the housing bubble and environment/growth issues. You have your eternal growth enthusiasts with plausible-sounding theories, cheered on by people in industry who stand to profit.
There’s plenty of speculation about the problem ahead of time:
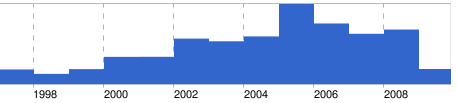
Google news timeline – housing bubble
People in authority doubt that there’s a problem, and envision a soft landing. In any case, nobody does anything about it.
Sound familiar so far?
However, I think it’s a bit of a leap to attribute our current mess to unsustainability in the real economy. For one thing, in hindsight, it’s clear that we weren’t overshooting natural carrying capacity in 1929, so it’s clearly possible to have a depression without an underlying resource problem. For another, we had ridiculously high commodity prices, but not many other direct impacts of environmental catastrophe (other than all the ones that have been slowly worsening for decades). My guess is that environmental overshoot has a lot longer time constant than housing or tech stock markets, both on the way up and the way down, so overshoot will evolve in more gradual and diverse ways at first. I think at best you can say that detecting the role of unsustainable resource management is like the tropical storm attribution problem. There are good theoretical reasons to think that higher sea surface temperatures contribute to tropical storm intensity, but there’s little hope of pinning Katrina on global warming specifically.
Personally, I think it’s possible that EIA is right, and peak oil is a little further down the road. With a little luck, asset prices might stabilize, and we could get another run of growth, at least from the perspective of those who benefit most from globalization. If so, will we learn from this bubble, and take corrective action before the next? I hope so.
I think the most important lesson could be the ending of the housing bubble, as we know it so far. It’s not a soft landing; positive feedbacks have taken over, as with a spark in a dry forest. That seems like a really good reason to step back and think, not just how to save big banks, but how to turn our current situation into a storm of creative destruction that mitigates the bigger one coming.