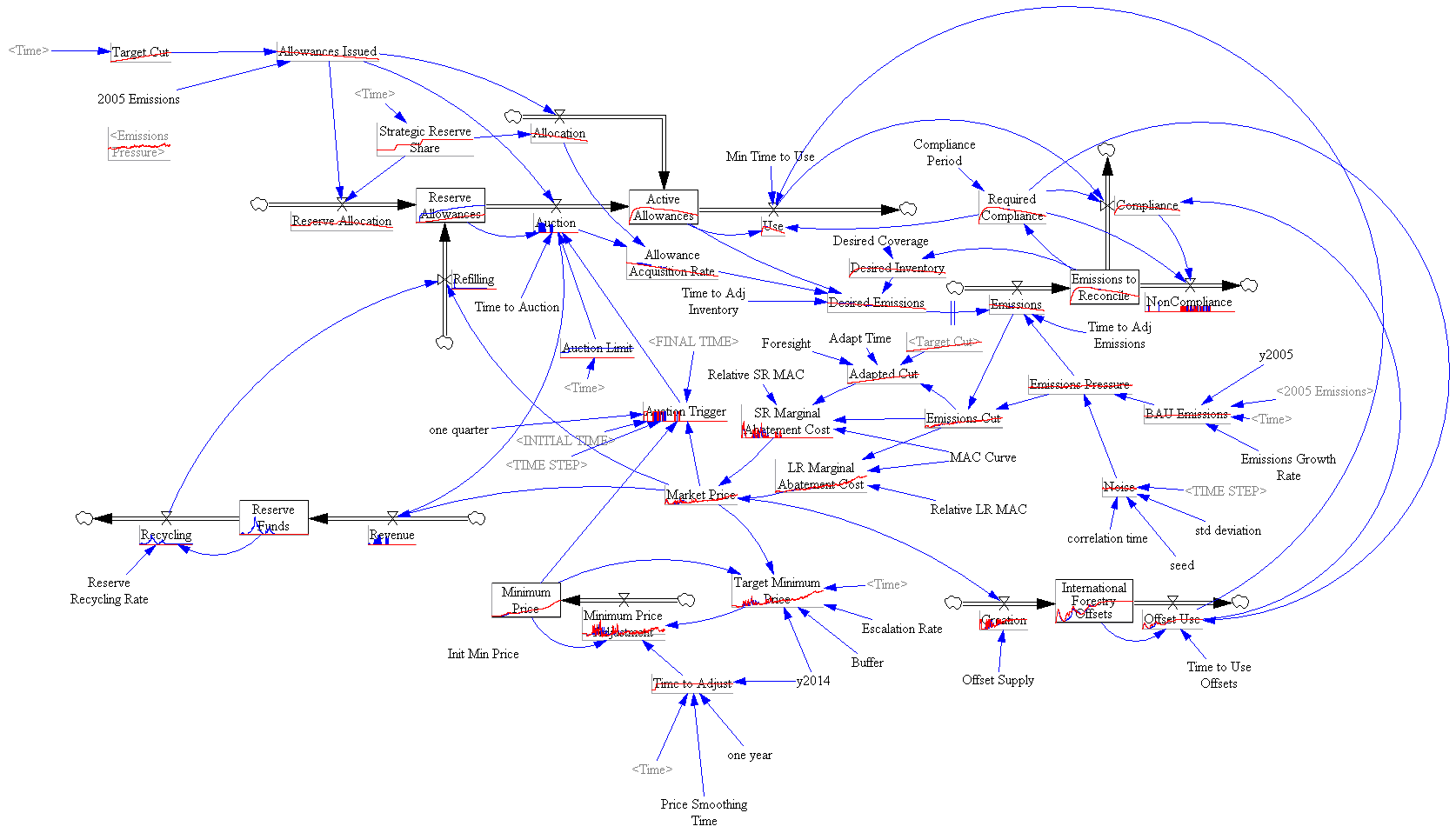
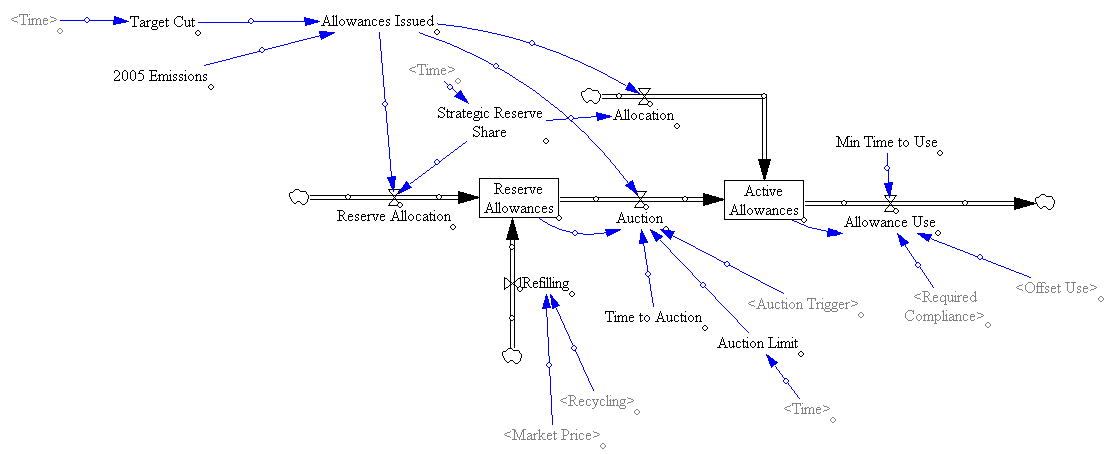
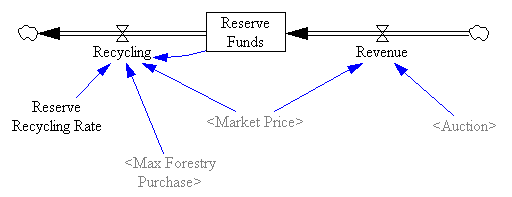
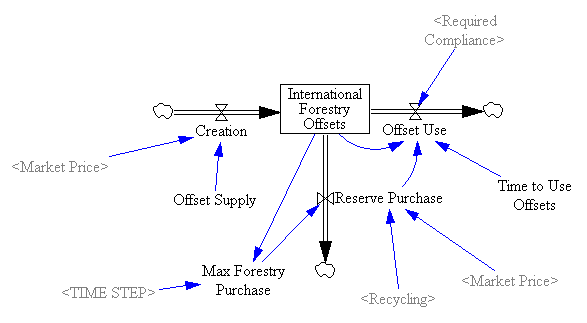
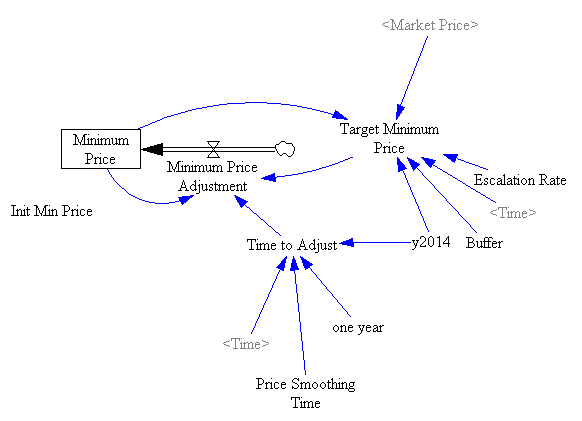
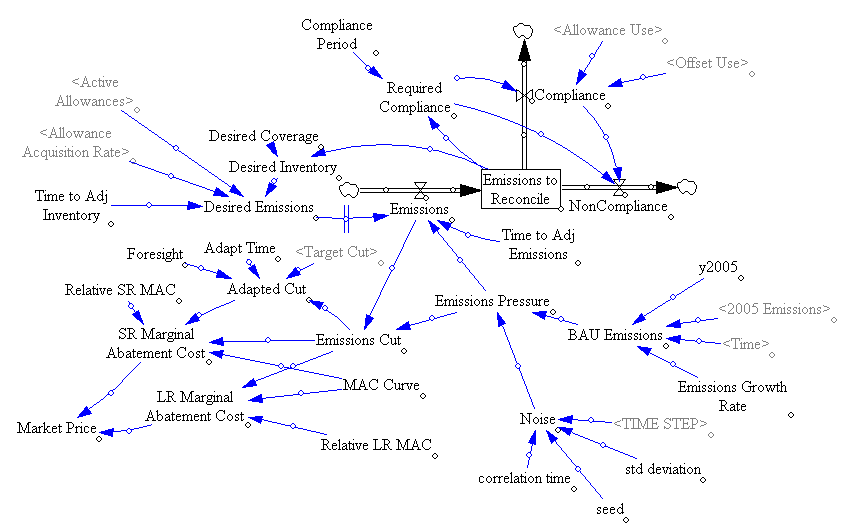
Model in hand, I tried some experiments (actually I built the model iteratively, while experimenting, but it’s hard to write that way, so I’m retracing my steps).
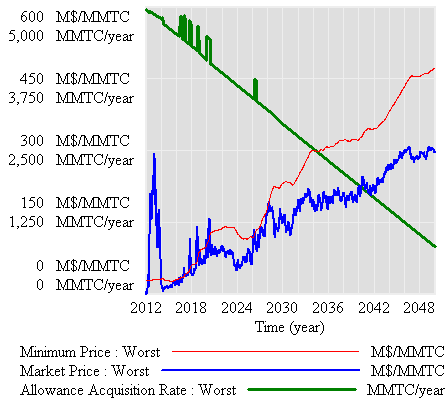
First, the “general equilbrium equivalent” version: no volatility, no SR marginal cost penalty for surprise, and firms see the policy coming. Result: smooth price escalation, and the strategic reserve is never triggered. Allowances just pile up in the reserve:
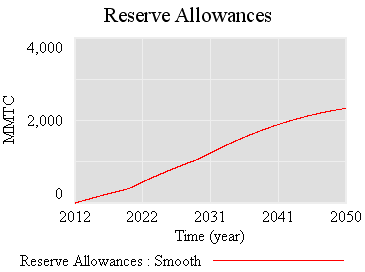
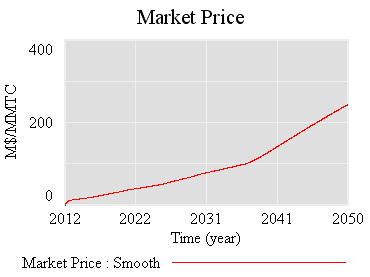
Since allowances accumulate, the de facto cap is 1-3% lower (by the share of allowances allocated to the reserve).
If there’s noise (SD=4.4%, comparable to petroleum demand), imperfect foresight, and short run adjustment costs, the market is more volatile:
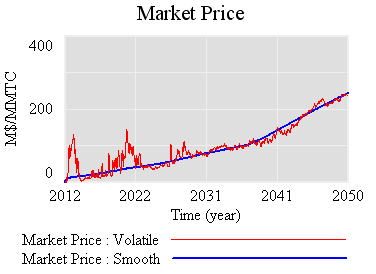
However, something strange happens. The stock of reserve allowances actually increases, even though some reserves are auctioned intermittently. That’s due to the refilling mechanism. An early auction, plus overreaction by firms, triggers a near-collapse in allowance prices (as happened in the ETS). Thus revenues generated in the reserve auction at high prices used to buy a lot of forestry offsets at very low prices:
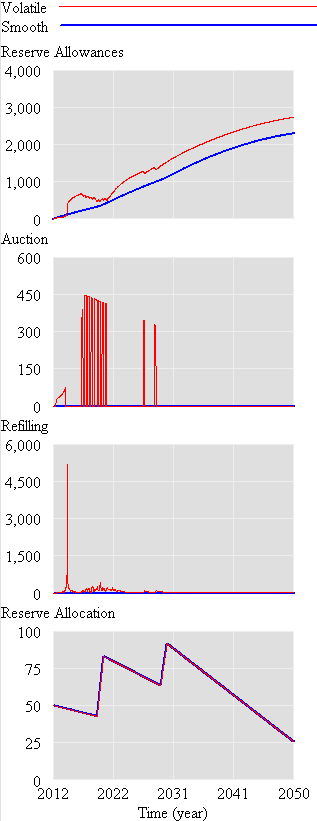
Could this happen in reality? I’m not sure – it depends on timing, behavior, and details of the recycling implementation. I think it’s safe to say that the current design is not robust to such phenomena. Fortunately, the market impact over the long haul is not great, because the extra accumulated allowances don’t get used (they pile up, as in the smooth case).
So, what is the reserve really accomplishing? Not much, it seems. Here’s the same trajectory, with volatility but no strategic reserve system:
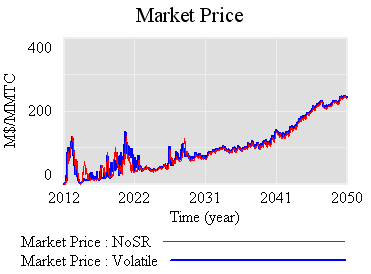
The mean price with the reserve (blue) is actually slightly higher, because the reserve mainly squirrels away allowances, without ever releasing them. Volatility is qualitatively the same, if not worse. That doesn’t seem like a good trade (unless you like the de facto emissions cut, which could be achieved more easily by lowering the cap and scrapping the reserve mechanism).
One reason the reserve fails to achieve its objectives is the recycling mechanism, which creates a perverse feedback loop that offsets the strategic reserve’s intended effect:
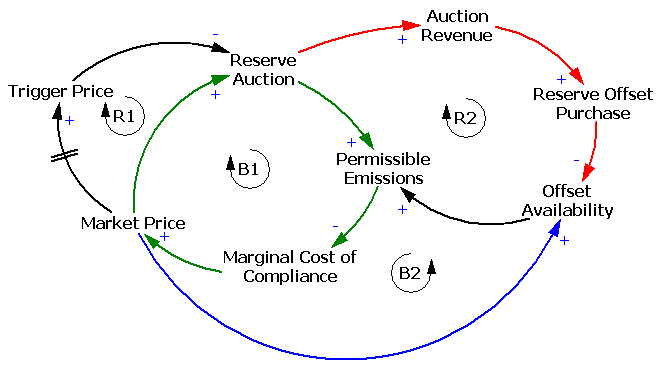
The intent of the reserve is to add a balancing feedback loop (B2, green) that stabilizes price. The problem is, the recycling mechanism (R2, red) consumes international forestry offsets that would otherwise be available for compliance, thus working against normal market operations (B2, blue). Thus the mechanism is only helpful to the extent that it exploits clever timing (doubtful), has access to offsets unavailable to the broad market (also doubtful), or doesn’t recycle revenue to refill the reserve. If you have a reserve, but don’t refill, you get some benefit:
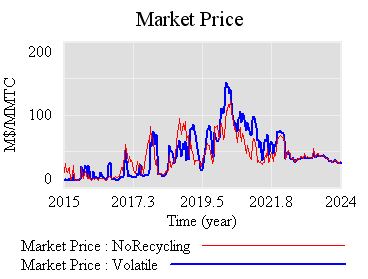
Still, the reserve mechanism seems like a lot of complexity yielding little benefit. At best, it can iron out some wrinkles, but it does nothing about strong, sustained price excursions (due to picking an infeasible target, for example). Perhaps there is some other design that could perform better, by releasing and refilling the reserve in a more balanced fashion. That ideal starts to sound like “buy low, sell high” – which is what speculators in the market are supposed to do. So, again, why bother?
I suspect that a more likely candidate for stabilization, robust to uncertainty, involves some possible violation of the absolute cap (gasp!). Realistically, if there are sustained price excursions, congress will violate it for us, so perhaps its better to recognize that up front and codify some orderly process for adaptation. At the least, I think congress should scrap the current reserve, and write the legislation in such a way as to kick the design problem to EPA, subject to a few general goals. That way, at least there’d be time to think about the design properly.