A colleague recently pointed me to this survey:
Estimating the price elasticity of fuel demand with stated preferences derived from a situational approach
It starts with a review of a variety of studies:
Table 1. Price elasticities of fuel demand reported in the literature, by average year of observation.
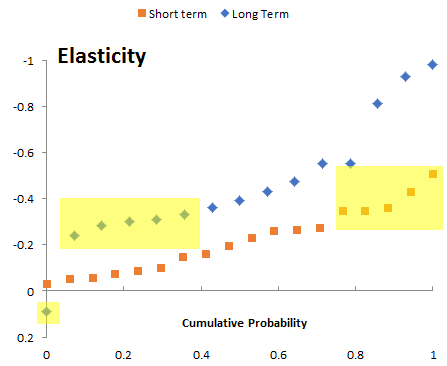
This is similar to other meta-analyses and surveys I’ve seen in the past. That means using it directly is potentially problematic. In a model, you’d typically plug the elasticity into something like the following:
Indicated fuel demand = reference fuel demand * (price/reference price) ^ elasticity
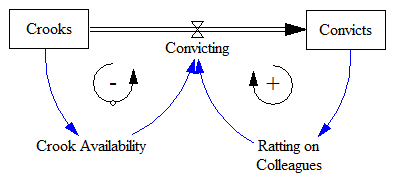
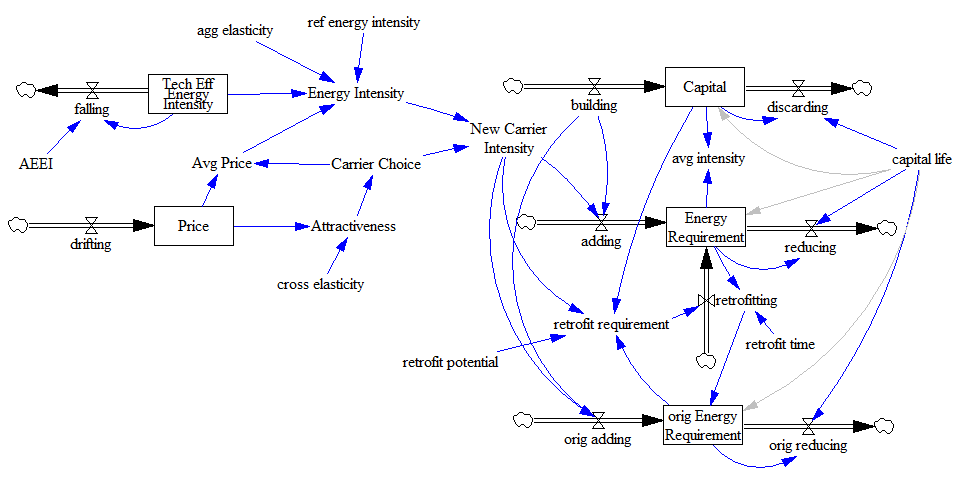
You’d probably have the expression above embedded in a larger structure, with energy requirements embodied in the capital stock, and various market-clearing feedback loops (as below). The problem is that plugging the elasticities from the literature into a dynamic model involves several treacherous leaps.
First, do the parameter values even make sense? Notice in the results plotted above that 33% of the long term estimates have magnitude < .3, overlapping the top 25% of the short term estimates. That’s a big red flag. Do they have conflicting definitions of “short” and “long”? Are there systematic methods problems?
Second, are they robust as you plan to use them? Many of the short term estimates have magnitude <<.1, meaning that a modest supply shock would cause fuel expenditures to exceed GDP. This is primarily problem with the equation above (but that’s likely similar to what was estimated). A better formulation would consider non-constant elasticity, but most likely the data is not informative about the extremes. One of the long term estimates is even positive – I’d be interested to see the rationale for that. Perhaps fuel is a luxury good?
Third, are the parameters any good? My guess is that some of these estimates are simply violating good practice for estimating dynamic systems. The real long term response involves a lot of lags on varying time scales, from annual (perceptions of prices and behavior change) to decadal (fleet turnover, moving, mode-switching) to longer (infrastructure and urban development). Almost certainly some of this is ignored in the estimate, meaning that the true magnitude of the long term response is understated.
Stated preference estimates avoid some problems, but create others. In the short run, people have a good sense of their options and responses. But in the long term, likely not: you’re essentially asking them to mentally simulate a complex system, evaluating options that may not even exist at present. Expert judgments are subject to some of the same limitations.
I think this explains why it’s possible to build a model that’s backed up with a lot of expertise and literature at every equation, that fails to reproduce the aggregate behavior of the system. Until you spend time integrating components, reconciling conflicting definitions across domains, and revisiting open-loop estimates in a closed-loop context, you don’t have an internally consistent story. Getting to that is a big part of the value of dynamic modeling.