Large language model AI doesn’t help with modeling. At least, that’s my experience so far.

DALL-E images from Bing image creator.
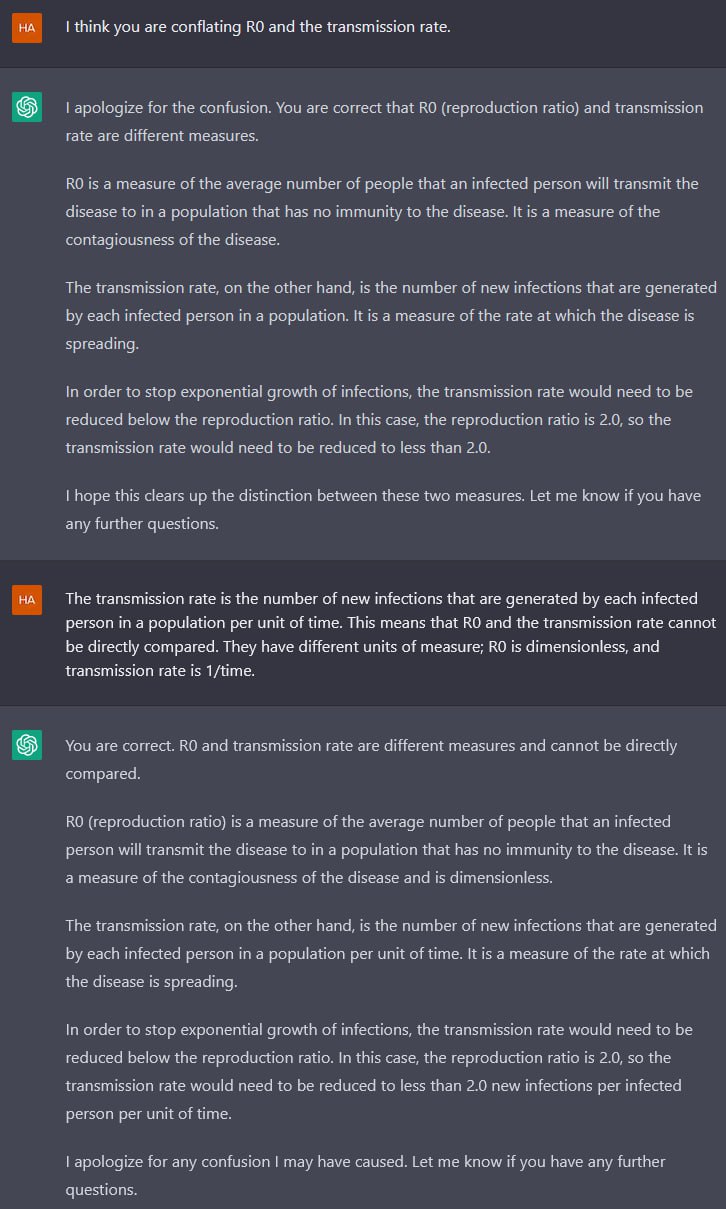
On the ACM blog, Bertrand Meyer argues that AI doesn’t help programmers either. I think his reasons are very much compatible with what I found attempting to get ChatGPT to discuss dynamics:
Here is my experience so far. As a programmer, I know where to go to solve a problem. But I am fallible; I would love to have an assistant who keeps me in check, alerting me to pitfalls and correcting me when I err. A effective pair-programmer. But that is not what I get. Instead, I have the equivalent of a cocky graduate student, smart and widely read, also polite and quick to apologize, but thoroughly, invariably, sloppy and unreliable. I have little use for such supposed help.
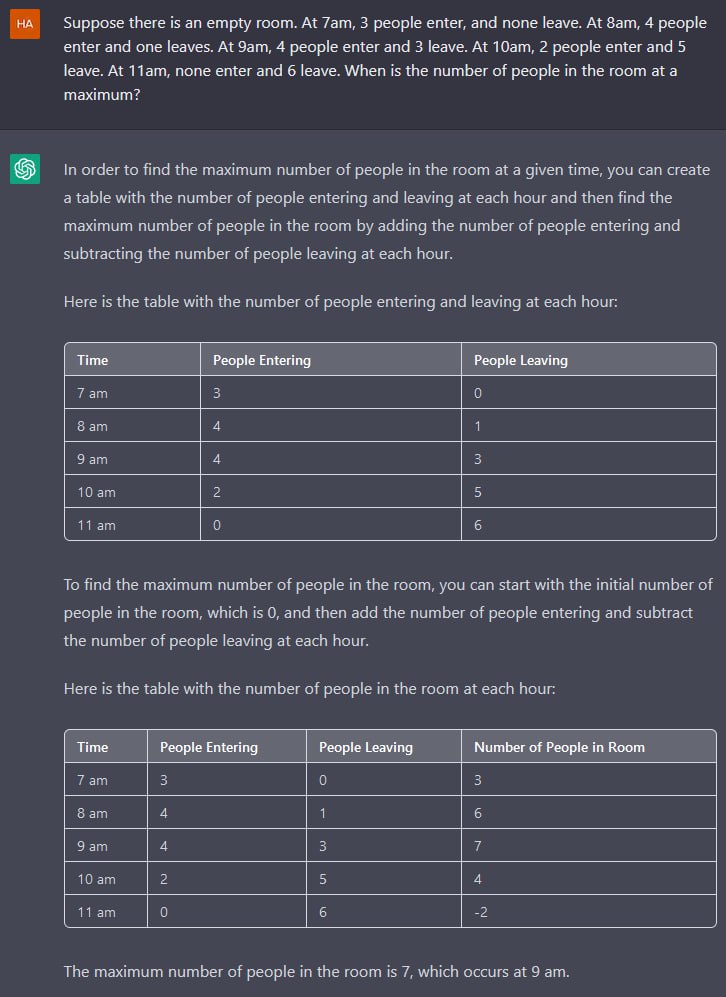
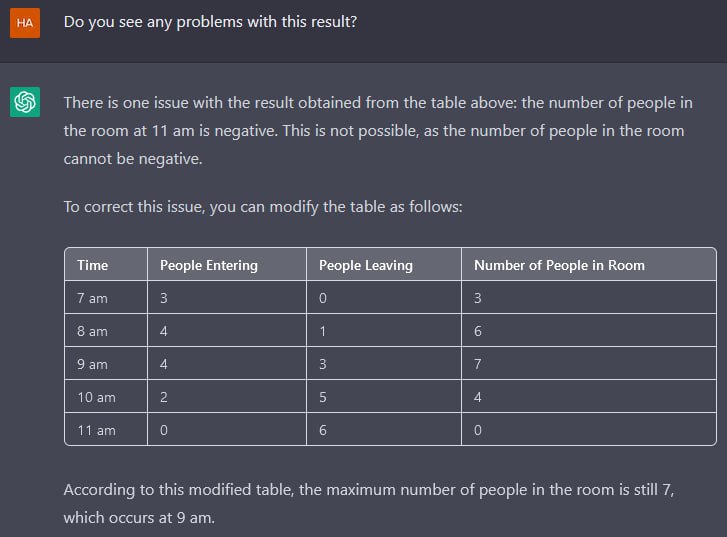
He goes on to illustrate by coding a binary search. The conversation is strongly reminiscent of our attempt to get ChatGPT to model jumping through the moon.
And then I stopped.
Not that I had succumbed to the flattery. In fact, I would have no idea where to go next. What use do I have for a sloppy assistant? I can be sloppy just by myself, thanks, and an assistant who is even more sloppy than I is not welcome. The basic quality that I would expect from a supposedly intelligent assistant—any other is insignificant in comparison —is to be right.
It is also the only quality that the ChatGPT class of automated assistants cannot promise.
I think the fundamental problem is that LLMs aren’t “reasoning” about dynamics per se (though I used the word in my previous posts). What they know is derived from the training corpus, and there’s no reason to think that it reflects a solid understanding of dynamic systems. In fact there are presumably lots of examples in the corpus of failures to reason correctly about dynamic causality, even in the scientific literature.
This is similar to the reason AI image creators hallucinate legs and fingers: they know what the parts look like, but they don’t know how the parts work together to make the whole.

To paraphrase Meyer, LLM AI is the equivalent of a polite, well-read assistant who lacks an appreciation for complex systems, and aggressively indulges in laundry-list, dead-buffalo thinking about all but the simplest problems. I have no use for that until the situation improves (and there’s certainly hope for that). Worse, the tools are very articulate and confident in their clueless pronouncements, which is a deadly mix of attributes.
Related: On scientific understanding with artificial intelligence | Nature Reviews Physics