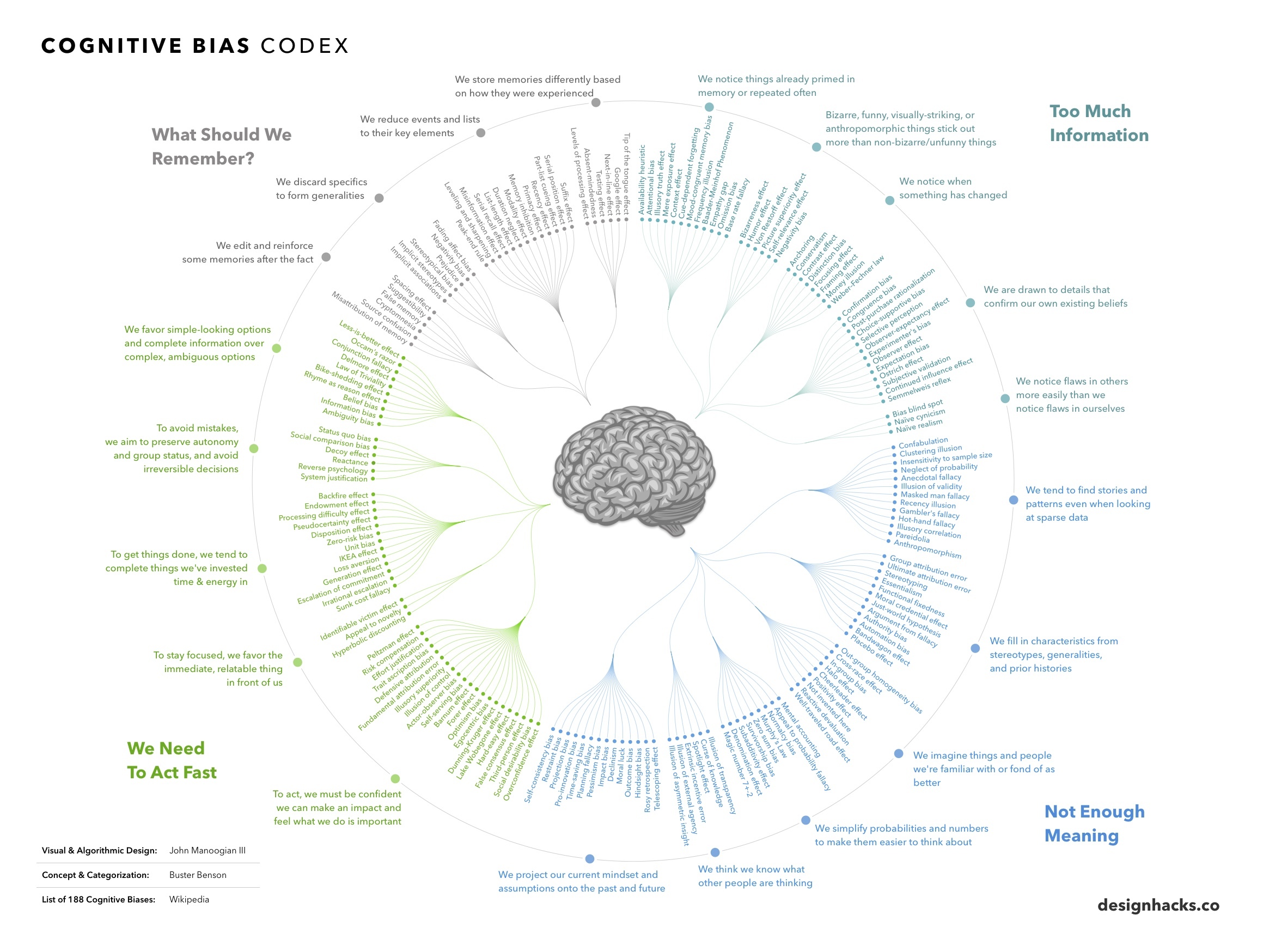
The HBR has a nice article asking, Why Do So Many Incompetent Men Become Leaders? Gender may amplify the problem, but I think its roots lie much deeper. We have a general surplus of incompetence across all walks of life.
So, how does this unhappy situation persist? One would hope that evolution would take care of this – that companies or nations that were systematically fooled by confidence over substance would be naturally selected out of the population. But that doesn’t seem to happen.
I think the explanation lies in the weaknesses of our mental models (and failure to refine them with formal models), and therefore our inability to attribute success and failure to decisions, in hindsight or prospects.
The HBR has a nice article asking, Why Do So Many Incompetent Men Become Leaders? Some excerpts:
In my view, the main reason for the uneven management sex ratio is our inability to discern between confidence and competence. That is, because we (people in general) commonly misinterpret displays of confidence as a sign of competence, we are fooled into believing that men are better leaders than women. In other words, when it comes to leadership, the only advantage that men have over women … is the fact that manifestations of hubris — often masked as charisma or charm — are commonly mistaken for leadership potential, and that these occur much more frequently in men than in women.
…
The truth of the matter is that pretty much anywhere in the world men tend to think that they that are much smarter than women. Yet arrogance and overconfidence are inversely related to leadership talent — the ability to build and maintain high-performing teams, and to inspire followers to set aside their selfish agendas in order to work for the common interest of the group.
…
The paradoxical implication is that the same psychological characteristics that enable male managers to rise to the top of the corporate or political ladder are actually responsible for their downfall. In other words, what it takes to get the job is not just different from, but also the reverse of, what it takes to do the job well. …
…
In fact, most leaders — whether in politics or business — fail. That has always been the case: the majority of nations, companies, societies and organizations are poorly managed, as indicated by their longevity, revenues, and approval ratings, or by the effects they have on their citizens, employees, subordinates or members. Good leadership has always been the exception, not the norm.
Gender may amplify the problem, but I think its roots lie much deeper. We have a general surplus of incompetence across all walks of life.
So, how does this unhappy situation persist? One would hope that evolution would take care of this – that companies or nations that were systematically fooled by confidence over substance would be naturally selected out of the population. But that doesn’t seem to happen.
I think the explanation lies in the weaknesses of our mental models (and failure to refine them with formal models), and therefore our inability to attribute success and failure to decisions, in hindsight or prospects. Here’s the purest expression of this line of thinking I’ve seen:
Why I Switched My Endorsement from Clinton to Trump
1. Things I Don’t Know: There are many things I don’t know. For example, I don’t know the best way to defeat ISIS. Neither do you. I don’t know the best way to negotiate trade policies. Neither do you. I don’t know the best tax policy to lift all boats. Neither do you. …. So on most political topics, I don’t know enough to make a decision. Neither do you, but you probably think you do.
3. Party or Wake: It seems to me that Trump supporters are planning for the world’s biggest party on election night whereas Clinton supporters seem to be preparing for a funeral. I want to be invited to the event that doesn’t involve crying and moving to Canada. (This issue isn’t my biggest reason.)
Scott Adams, Dilbert creator
If you can’t predict which leader’s proposals or methods will work, why not go with the ones that sound the best? Or, if you can’t figure out how to grow the pie for everyone, why not at least choose the tribal affiliation that gives you the best chance at a slice of patrimony?
Still, at the end of the day, the honeymoon is over, and the effects of decisions should come home to roost, right? Not necessarily. Even after the fact, attribution of causality in dynamic systems is difficult, because causes and effects are separated in space in time. So, you can’t learn to do better by simple pattern matching; you have to understand the structure that’s producing behavior. Firm policies and election rules worsen the problem by rotating people around, so that they can launch initiatives and be gone before the consequences are observed, defeating evolution.
John Sterman and Nelson Repenning explain in another context:
The Capability Trap
The capability trap arises from the interactions between judg-
mental biases and the physical structure of work processes.
For example, machine operators or design engineers facing a
shortfall may initially work harder …, do more rework
…, or focus on throughput …, all of which
reduce the time available for improvement. These responses
are tempting because they yield immediate gains, while their
costs are distant in time and space, uncertain, and hard to
detect. But, while throughput improves in the short run, the
reduction in time dedicated to learning causes process capa-
bility to decline. Eventually, workers find themselves again
falling short of their throughput target, forcing a further shift
toward working and away from improving. Instead of making
up for the improvement activity they skipped earlier, their
own past actions, by causing the reinvestment loops … to work as vicious cycles, trap them in a downward
spiral of eroding process capability, increasing work hours,
and less and less time for improvement.
…
Misperceptions of Feedback
While the literature and field data support the links in the
model, our account of the capability trap raises several
questions. First, wouldn’t people recognize the existence of
the reinforcing feedbacks that create the trap and take
actions to avoid it? Second, if they find themselves stuck in
the trap, wouldn’t people learn to escape it by making appro-
priate short-term sacrifices? Studies of decision making in
dynamic environments suggest that such learning is far from
automatic.
Consider the outcome feedback received from a decision to
spend more time working and less on improvement. Perfor-
mance quickly increases, producing a clear, salient, unam-
biguous outcome. In contrast, the negative consequences of
this action—the decline in process capability—take time, are
hard to observe, and may have ambiguous interpretations. In
experiments ranging from running a simulated production and
distribution system (Sterman, 1989) to fighting a simulated
forest fire (Brehmer, 1992) or managing a simulated fishery
(Moxnes, 1999), subjects have been shown to grossly over-
weight the short-run positive benefits of their decisions while
ignoring the long-run, negative consequences. Participants in
these experiments produce wildly oscillating production
rates, allow their fire-fighting headquarters to burn down, and
find their fleets idled after overexploiting their fisheries.
….
Once caught in the capability trap, people are also unlikely to
learn to escape it. A new improvement program, by reducing
the time available for throughput, causes an immediate and
salient drop in performance, while its benefits are uncertain,
delayed, difficult to assess, and may be insufficient to switch
the reinforcing feedbacks to virtuous cycles. People are likely
to conclude that the improvement program they attempted
does not work and should be abandoned.
Attribution Errors in Judging the Cause of Low Throughput
When choosing to emphasize first- or second-order improve-
ment, managers must make a judgment about the causes of
low process throughput. If they believe the cause of low per-
formance lies in the physical structure of the process, they
are likely to focus their efforts on process improvement. If,
however, low throughput is thought to result from lack of
worker effort or discipline, then managers are better off
focusing on increasing the quantity of work. The cues people
use to make causal attributions include temporal order,
covariation, and contiguity in time and space (Einhorn and
Hogarth, 1986). Attributing low throughput to inadequate
worker effort is consistent with all these cues: …. Managers are thus likely to attribute a throughput shortfall to inadequate worker effort, even when the true causes are systemic process
problems.
Managers’ tendency to attribute performance shortfalls to
problems with the workforce rather than the production sys-
error, or dispositional bias. …. Existing research thus suggests that managers facing throughput gaps are likely to conclude that workers, not the process, are the cause of low throughput, reinforcing the bias against fundamental improvement.
As Sterman & Repenning go on to explain, these attribution errors are likely to become self-confirming, and to be institutionalized in organizational routines, leading to self-reinforcing organizational pathologies.
Blaming workers for productivity shortfalls that ultimately arise from the firm leadership’s failure to focus on process improvement is a lot like blaming poverty on the shortcomings of poor people, rather than their social environment, which subjects them to poor education, predatory monopolies and disproportionate criminal and environmental burdens. Programs that focus exclusively on motivating (or punishing) the impoverished are at least as naive as those that seek to alleviate poverty through transfers of money without creating skills or opportunities.
Back to Scott Adams, one argument in favor of unfounded overconfidence remains:
6. Persuasion: Economies are driven by psychology. If you expect things to go well tomorrow, you invest today, which causes things to go well tomorrow, as long as others are doing the same. The best kind of president for managing the psychology of citizens – and therefore the economy – is a trained persuader. You can call that persuader a con man, a snake oil salesman, a carnival barker, or full of shit. It’s all persuasion. And Trump simply does it better than I have ever seen anyone do it.
…
Most of the job of president is persuasion. Presidents don’t need to understand policy minutia. They need to listen to experts and then help sell the best expert solutions to the public. Trump sells better than anyone you have ever seen, even if you haven’t personally bought into him yet. You can’t deny his persuasion talents that have gotten him this far.
Psychology is in steady state over any reasonably long time horizon, so it’s not really psychology that drives economic growth. Psychology is necessary, in that people have to feel that conditions are right for risk-taking, but it’s not sufficient. The real long run driver is innovation, embodied in people, technology and organizations. That means it’s also necessary that innovations work, so investments produce, GDP makes people happy, schools teach, infrastructure serves, and wars defeat more enemies than they create. Mere bluster does not get you those things.
So here’s the problem: the overconfidence that lends itself to persuasion has side effects:
- It’s hostile to “listening to experts” (or to anyone).
- It favors naive, simple causal attributions over inquiry into system structure.
- It opposes learning from feedback, whether from constituents or objective measurements.
- Confronted by adversity, it retreats into confirmation bias and threat rigidity.
So, overconfidence doesn’t make the economy grow faster. It just makes things go faster, whether paradise or a cliff lies ahead.
I don’t think firms or planets want to speed off a cliff, so we need to do better. It’s a tall order, but I think awareness of the problem is a good start. After that, it’s a hard road, but we all need to become better system scientists, and spend more time participating in governance and attempting to understand how systems work.
There’s reason for hope – not all firms fall into capability traps. Emulating those that succeed, we might start by investing some time in process improvement. The flawed processes by which we now pick leaders look like low-hanging fruit to me.