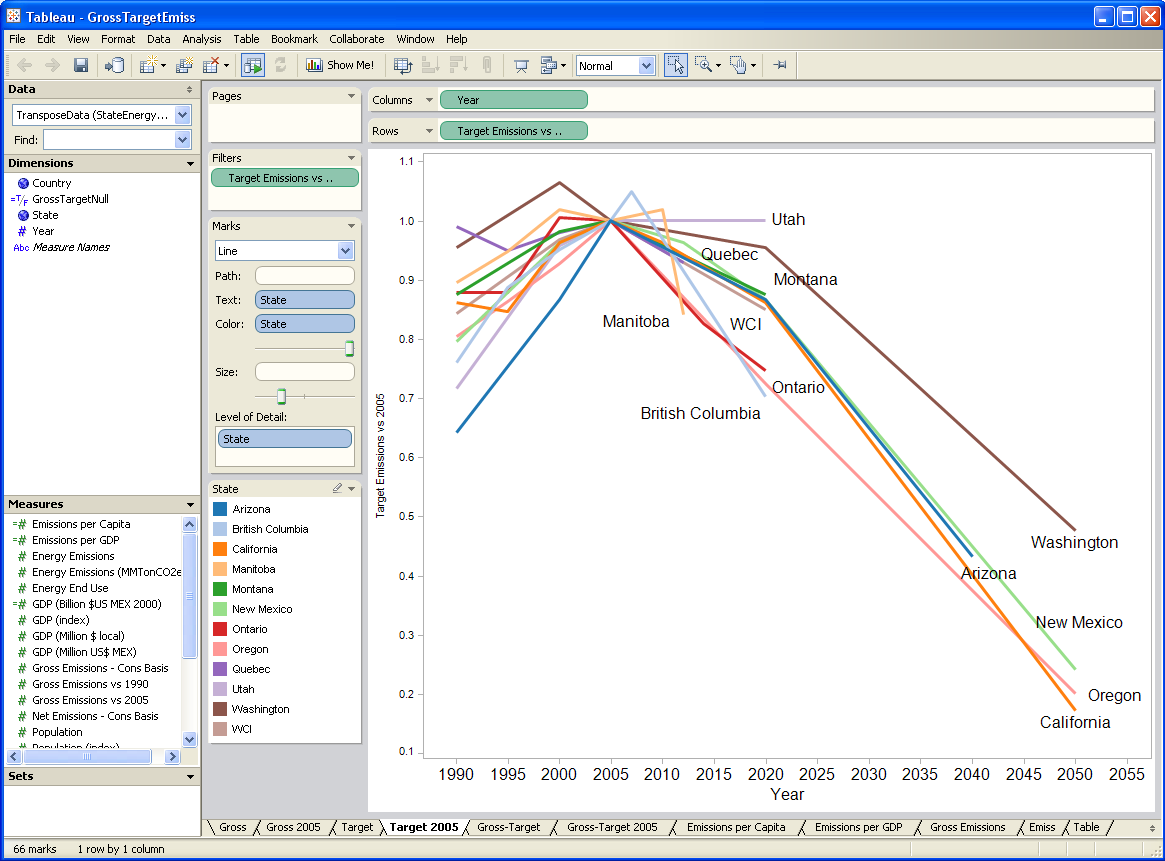
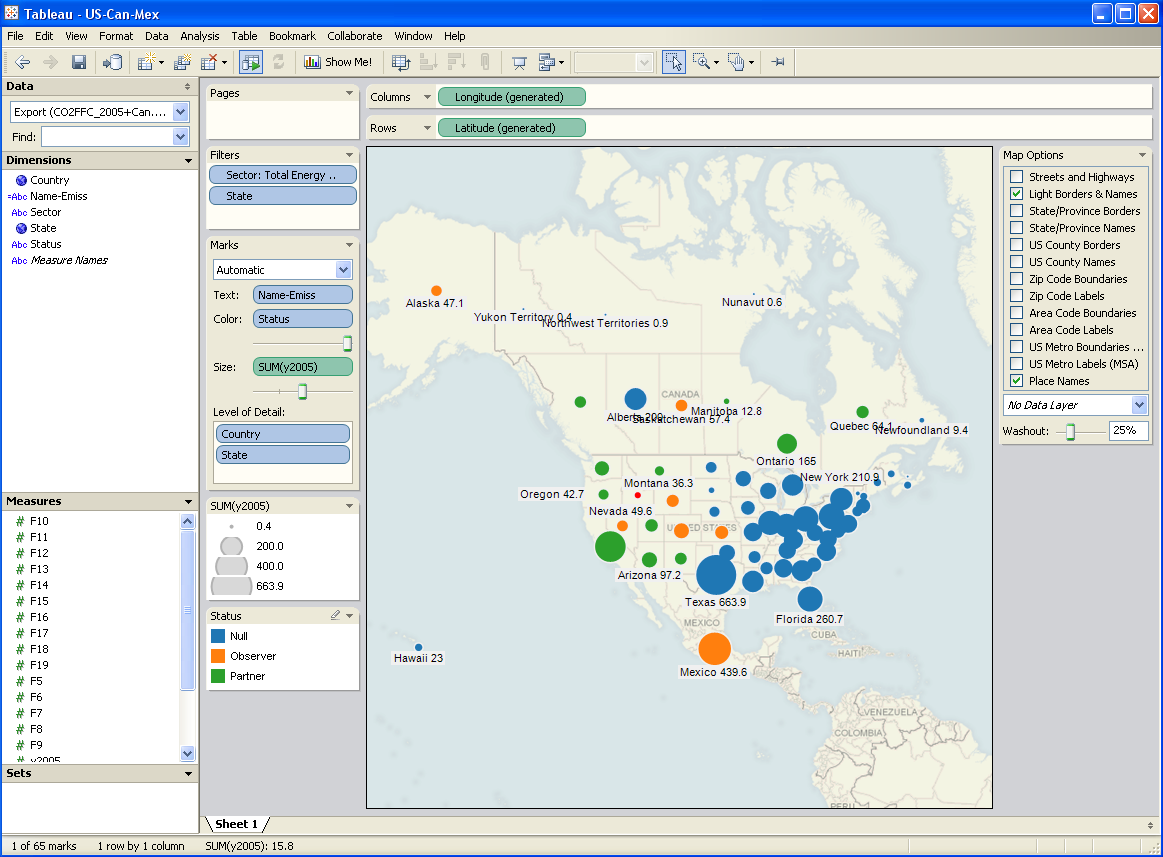
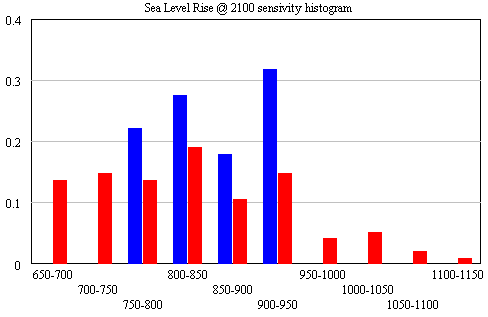
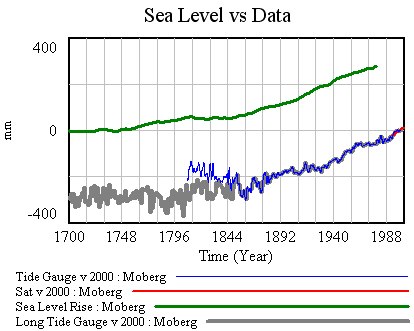
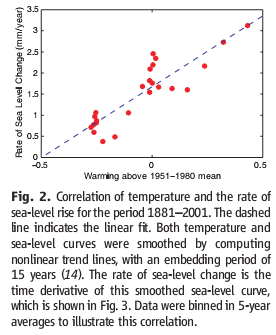
I’ve written quite a bit about bathtub dynamics here. I got the term from “Cloudy Skies” and other work by John Sterman and Linda Booth Sweeney.
We report experiments assessing people’s intuitive understanding of climate change. We presented highly educated graduate students with descriptions of greenhouse warming drawn from the IPCC’s nontechnical reports. Subjects were then asked to identify the likely response to various scenarios for CO2 emissions or concentrations. The tasks require no mathematics, only an understanding of stocks and flows and basic facts about climate change. Overall performance was poor. Subjects often select trajectories that violate conservation of matter. Many believe temperature responds immediately to changes in CO2 emissions or concentrations. Still more believe that stabilizing emissions near current rates would stabilize the climate, when in fact emissions would continue to exceed removal, increasing GHG concentrations and radiative forcing. Such beliefs support wait and see policies, but violate basic laws of physics.
The climate bathtubs are really a chain of stock processes: accumulation of CO2 in the atmosphere, accumulation of heat in the global system, and accumulation of meltwater in the oceans. How we respond to those, i.e. our emissions trajectory, is conditioned by some additional bathtubs: population, capital, and technology. This post is a quick look at the first.
I’ve grabbed the population sector from the World3 model. Regardless of what you think of World3’s economics, there’s not much to complain about in the population sector. It looks like this:

People are categorized into young, reproductive age, working age, and older groups. This 4th order structure doesn’t really capture the low dispersion of the true calendar aging process, but it’s more than enough for understanding the momentum of a population. If you think of the population in aggregate (the sum of the four boxes), it’s a bathtub that fills as long as births exceed deaths. Roughly tuned to history and projections, the bathtub fills until the end of the century, but at a diminishing rate as the gap between births and deaths closes:


Notice that the young (blue) peak in 2030 or so, long before the older groups come into near-equilibrium. An aging chain like this has a lot of momentum. A simple experiment makes that momentum visible. Suppose that, as of 2010, fertility suddenly falls to slightly below replacement levels, about 2.1 children per couple. (This is implemented by changing the total fertility lookup). That requires a dramatic shift in birth rates:

However, that doesn’t translate to an immediate equilibrium in population. Instead,population still grows to the end of the century, but reaching a lower level. Growth continues because the aging chain is internally out of equilibrium (there’s also a small contribution from ongoing extension of life expectancy, but it’s not important here). Because growth has been ongoing, the demographic pyramid is skewed toward the young. So, while fertility is constant per person of child-bearing age, the population of prospective parents grows for a while as the young grow up, and thus births continue to increase. Also, at the time of the experiment, the elderly population has not reached equilibrium given rising life expectancy and growth down the chain.

Achieving immediate equilibrium in population would require a much more radical fall in fertility, in order to bring births immediately in line with deaths. Implementing such a change would require shifting yet another bathtub – culture – in a way that seems unlikely to happen quickly. It would also have economic side effects. Often, you hear calls for more population growth, so that there will be more kids to pay social security and care for the elderly. However, that’s not the first effect of accelerated declines in fertility. If you look at the dependency ratio (the ratio of the very young and old to everyone else), the first effect of declining fertility is actually a net benefit (except to the extent that young children are intrinsically valued, or working in sweatshops making fake Gucci wallets):

The bottom line of all this is that, like other bathtubs, it’s hard to change population quickly, partly because of the physics of accumulation of people, and partly because it’s hard to even talk about the culture of fertility (and the economic factors that influence it). Population isn’t likely to contribute much to meeting 2020 emissions targets, but it’s part of the long game. If you want to win the long game, you have to anticipate long delays, which means getting started now.
The model (Vensim binary, text, and published formats): World3 Population.vmf World3-Population.mdl World3 Population.vpm