Objecting to experiments that compare two unobjectionable policies or treatments
Randomized experiments have enormous potential to improve human welfare in many domains, including healthcare, education, finance, and public policy. However, such “A/B tests” are often criticized on ethical grounds even as similar, untested interventions are implemented without objection. We find robust evidence across 16 studies of 5,873 participants from three diverse populations spanning nine domains—from healthcare to autonomous vehicle design to poverty reduction—that people frequently rate A/B tests designed to establish the comparative effectiveness of two policies or treatments as inappropriate even when universally implementing either A or B, untested, is seen as appropriate. This “A/B effect” is as strong among those with higher educational attainment and science literacy and among relevant professionals. It persists even when there is no reason to prefer A to B and even when recipients are treated unequally and randomly in all conditions (A, B, and A/B). Several remaining explanations for the effect—a belief that consent is required to impose a policy on half of a population but not on the entire population; an aversion to controlled but not to uncontrolled experiments; and a proxy form of the illusion of knowledge (according to which randomized evaluations are unnecessary because experts already do or should know “what works”)—appear to contribute to the effect, but none dominates or fully accounts for it. We conclude that rigorously evaluating policies or treatments via pragmatic randomized trials may provoke greater objection than simply implementing those same policies or treatments untested.
Author: Tom
Complexity should be the default assumption
Whether or not we can prove that a system experiences trophic cascades and other nonlinear side-effects, we should manage as if it does, because we know that these dynamics are common.
There’s been a long-running debate over whether wolf reintroduction led to a trophic cascade in Yellowstone. There’s a nice summary here:
Yesterday, June initiated an in depth discussion on the benefit of wolves in Yellowstone, in the form of trophic cascade with the video: How Wolves Change the River:
This was predicted by some, and has been studied by William Ripple, Robert Beschta Trophic Cascades in Yellowstone: The first fifteen years after wolf reintroduction http://www.cof.orst.edu/leopold/papers/RippleBeschtaYellowstone_BioConserv.pdf
Shannon, Roger, and Mike, voiced caution that the verdict was still out.
I would like to caution that many of the reported “positive” impacts wolves have had on the environment after coming back to Yellowstone remain unproven or are at least controversial. This is still a hotly debated topic in science but in the popular media the idea that wolves can create a Utopian environment all too often appears to be readily accepted. If anyone is interested, I think Dave Mech wrote a very interesting article about this (attached). As he puts it “the wolf is neither a saint nor a sinner except to those who want to make it so”.
Mech: Is Science in Danger of Sanctifying Wolves
Roger added
I see 2 points of caution regarding reports of wolves having “positive” impacts in Yellowstone. One is that understanding cause and effect is always hard, nigh onto impossible, when faced with changes that occur in one place at one time. We know that conditions along rivers and streams have changed in Yellowstone but how much “cause” can be attributed to wolves is impossible to determine.
Perhaps even more important is that evaluations of whether changes are “positive” or “negative” are completely human value judgements and have no basis in science, in this case in the science of ecology.
-Ely Field Naturalists
Of course, in a forum discussion, this becomes:
Wolves changed rivers.
Not they didn’t.
Yes they did.
(iterate ad nauseam)
Prove it.
… with “prove it” roughly understood to mean establishing that river = a + b*wolves, rejecting the null hypothesis that b=0 at some level of statistical significance.
I would submit that this is a poor framing of the problem. Given what we know about nonlinear dynamics in networks like an ecosystem, it’s almost inconceivable that there would not be trophic cascades. Moreover, it’s well known that simple correlation would not be able to detect such cascades in many cases anyway.
A “no effect” default in other situations seems equally naive. Is it really plausible that a disturbance to a project would not have any knock-on effects? That stressing a person’s endocrine system would not cause a path-dependent response? I don’t think so. Somehow we need ordinary conversations to employ more sophisticated notions about models and evidence in complex systems. I think at least two ideas are useful:
- The idea that macro behavior emerges from micro structure. The appropriate level of description of an ecosystem, or a project, is not a few time series for key populations, but an operational, physical description of how species reproduce and interact with one another, or how tasks get done.
- A Bayesian approach to model selection, in which our belief in a particular representation of a system is proportional to the degree to which it explains the evidence, relative to various alternative formulations, not just a naive null hypothesis.
In both cases, it’s important to recognize that the formal, numerical data is not the only data applicable to the system. It’s also crucial to respect conservation laws, units of measure, extreme conditions tests and other Reality Checks that essentially constitute free data points in parts of the parameter space that are otherwise unexplored.
The way we think and talk about these systems guides the way we act. Whether or not we can prove in specific instances that Yellowstone had a trophic cascade, or the Chunnel project had unintended consequences, we need to manage these systems as if they could. Complexity needs to be the default assumption.
Big Ideas About Systems
A slide at ISSS wonders what the big ideas about systems are:

*
Here’s my take:
- Stocks & flows – a.k.a. states and rates, levels and rates, integration, accumulation, delays – understanding these bathtub dynamics is absolutely central.
- Feedback -positive and negative feedback, leading to exponential growth and decay and other simple or complex behaviors.
- Emergence – including the idea that structure determines behavior, the iceberg, and more generally that complex, counter-intuitive patterns can emerge from simple structures.
- Relationships – ranging from simple connections, to networks, to John Muir’s insight, “When we try to pick out anything by itself, we find it hitched to everything else in the Universe.”
- Randomness, risk and uncertainty – this does a disservice by condensing a large domain in its own right into an aspect of systems, but it’s certainly critical for understanding the nature of evidence and decision making.
- Self-reference, e.g., autopoiesis and second-order cybernetics.
- Evolution – population selection and modification by recombination, mutation and imitation.**
- Models – recognizing that mental models, diagrams, archetypes and stories can only get you so far – eventually you need simulation and other formal tools.
- Paradigms – in the sense in which Dana Meadows meant, “The mindset or paradigm out of which the system — its goals, power structure, rules, its culture — arises.”
If pressed for simplification, I’ll take stocks, flows and feedback. If you don’t have those, you don’t have much.
* h/t Angelika Schanda for posting the slide above in the SD Society Facebook group.
** Added following a suggestion by Gustavo Collantes on LinkedIn, which also mentioned learning. That’s an interesting case, because elements of learning are present in ordinary feedback loops, in evolution (imitation), and in self-reference (system redesign).
Coupled Catastrophes
I ran across this cool article on network dynamics, and thought the model would be an interesting application for Ventity:
Coupled catastrophes: sudden shifts cascade and hop among interdependent systems
Charles D. Brummitt, George Barnett and Raissa M. D’Souza
Abstract
An important challenge in several disciplines is to understand how sudden changes can propagate among coupled systems. Examples include the synchronization of business cycles, population collapse in patchy ecosystems, markets shifting to a new technology platform, collapses in prices and in confidence in financial markets, and protests erupting in multiple countries. A number of mathematical models of these phenomena have multiple equilibria separated by saddle-node bifurcations. We study this behaviour in its normal form as fast–slow ordinary differential equations. In our model, a system consists of multiple subsystems, such as countries in the global economy or patches of an ecosystem. Each subsystem is described by a scalar quantity, such as economic output or population, that undergoes sudden changes via saddle-node bifurcations. The subsystems are coupled via their scalar quantity (e.g. trade couples economic output; diffusion couples populations); that coupling moves the locations of their bifurcations. The model demonstrates two ways in which sudden changes can propagate: they can cascade (one causing the next), or they can hop over subsystems. The latter is absent from classic models of cascades. For an application, we study the Arab Spring protests. After connecting the model to sociological theories that have bistability, we use socioeconomic data to estimate relative proximities to tipping points and Facebook data to estimate couplings among countries. We find that although protests tend to spread locally, they also seem to ‘hop’ over countries, like in the stylized model; this result highlights a new class of temporal motifs in longitudinal network datasets.
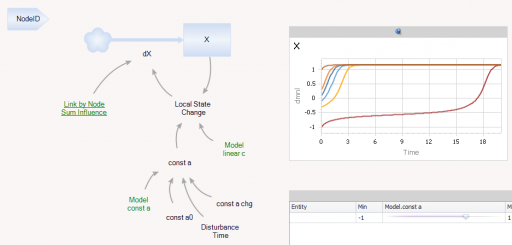
Ventity makes sense here because the system consists of a network of coupled states. Ventity makes it easy to represent a wide variety of network architectures. This means there are two types of entities in the system: “Nodes” and “Couplings.”
The Node entitytype contains a single state (X), with local feedback, as well as a remote influence from Coupling and a few global parameters referenced from the Model entity:
Tribonacci Numbers
Fibonacci Rabbits are inexplicably popular among all my posts and models. Here’s a cool video on generalization of the Fibonacci numbers to more dimensions:
Stress, Burnout & Biology
In my last post, stress takes center stage as both a driver and an outcome of the cortisol-cytokine-serotonin system. But stress can arise endogenously in another way as well, from the interplay of personal goals and work performance. Jack Homer’s burnout model is a system dynamics classic that everyone should explore:
Worker burnout: A dynamic model with implications for prevention and control
Jack B. Homer
This paper explores the dynamics of worker burnout, a process in which a hard‐working individual becomes increasingly exhausted, frustrated, and unproductive. The author’s own two‐year experience with repeated cycles of burnout is qualitatively reproduced by a small system dynamics model that portrays the underlying psychology of workaholism. Model tests demonstrate that the limit cycle seen in the base run can be stabilized through techniques that diminish work‐related stress or enhance relaxation. These stabilizing techniques also serve to raise overall productivity, since they support a higher level of energy and more working hours on the average. One important policy lever is the maximum workweek or work limit; an optimal work limit at which overall productivity is at its peak is shown to exist within a region of stability where burnout is avoided. The paper concludes with a strategy for preventing burnout, which emphasizes the individual’s responsibility for understanding the self‐inflicted nature of this problem and pursuing an effective course of stability.
You can find a copy of the model in the help system that comes with Vensim.
Biological Dynamics of Stress: the Outer Loops
A while back I reviewed an interesting model of hormone interactions triggered by stress. The bottom line:
I think there might be a lot of interesting policy implications lurking in this model, waiting for an intrepid explorer with more subject matter expertise than I have. I think the crucial point here is that the structure identifies a mechanism by which patient outcomes can be strongly path dependent, where positive feedback preserves a bad state long after harmful stimuli are removed. Among other things, this might explain why it’s so hard to treat such patients. That in turn could be a basis for something I’ve observed in the health system – that a lot of doctors find autoimmune diseases mysterious and frustrating, and respond with a variation on the fundamental attribution error – attributing bad outcomes to patient motivation when delayed, nonlinear feedback is responsible.
Since then, I’ve been reflecting on the fact that the internal positive feedbacks that give the hormonal system a tipping point, allowing people to get stuck in a bad state, are complemented and amplified by a set of external loops that do the same thing. I’ve reorganized my version of the model to show how this works:
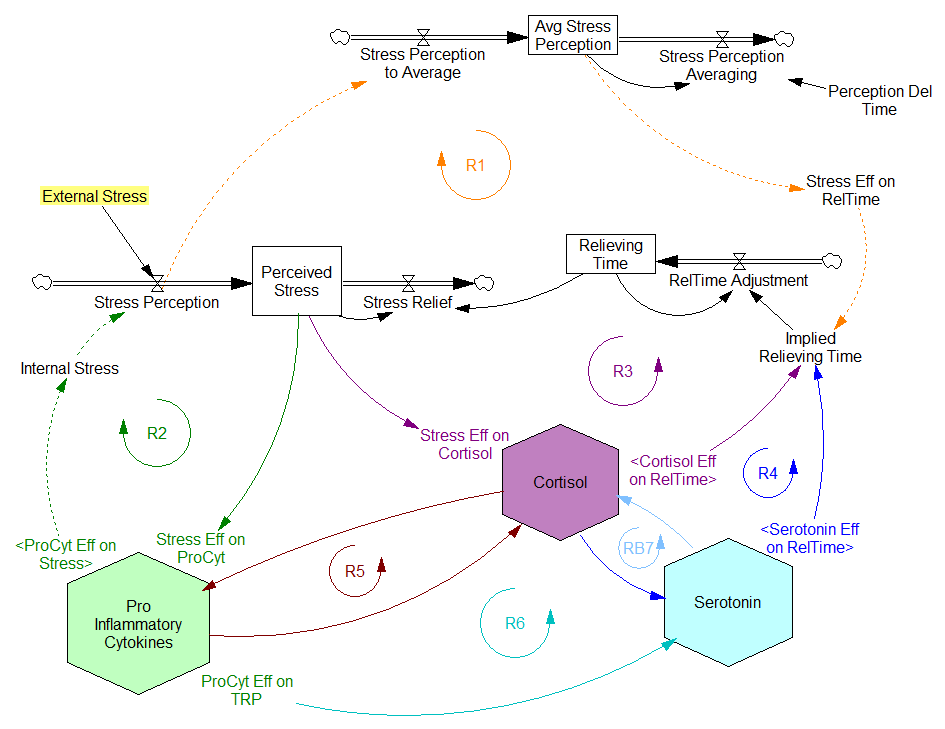
Stress-Hormone Interactions (See also Fig. 1 in the original paper.)
The trigger for the system is External Stress (highlighted in yellow). A high average rate of stress perception lengthens the relieving time for stress. This creates a reinforcing loop, R1. This is analogous to the persistent pollution loop in World3, where a high level of pollution poisons the mechanisms that alleviate pollution.
I’ve constructed R1 with dashed arrows, because the effects are transient – when stress perception stops, eventually the stress effect on the relieving time returns to normal. (If I were reworking the model, I think I would simplify this effect, so that the stock of Perceived Stress affected the relieving time directly, rather than including a separate smooth, but this would not change the transience of the effect.)
A second effect of stress, mediated by Pro-inflammatory Cytokines, produces another reinforcing loop, R2. That loop does create Internal Stress, which makes it potentially self-sustaining. (Presumably that would be something like stress -> cytokines -> inflammation -> pain -> stress.) However, in simulations I’ve explored, a self-sustaining effect does not occur – evidently the Pro-inflammatory Cytokines sector does not contain a state that is permanently affected, absent an external stress trigger.
Still more effects of stress are mediated by the Cortisol and Serotonin sectors, and Cortisol-Pro-inflammatory Cytokines interactions. These create still more reinforcing loops, R3, R4, R5 and R6. Cortisol-serotonin affects appear to have multiple signs, making the net effect (RB67) ambiguous in polarity (at least without further digging into the details). Like R1 (the stress self-effect), R3, R4 and R6 operate by extending the time over which stress is relieved, which tends to increase the stock of stress. Even with long relief times, stress still drains away eventually, so these do not create permanent effects on stress.
However, within the Cortisol sector, there are persistent states that are affected by stress and inflammation. These are related to glucocorticoid receptor function, and they can be durably altered, making the effects of stress long term.
These dynamics alone make the system hard to understand and manage. However, I think the real situation is still more complex. Consider the following red links, which produce stress endogenously:
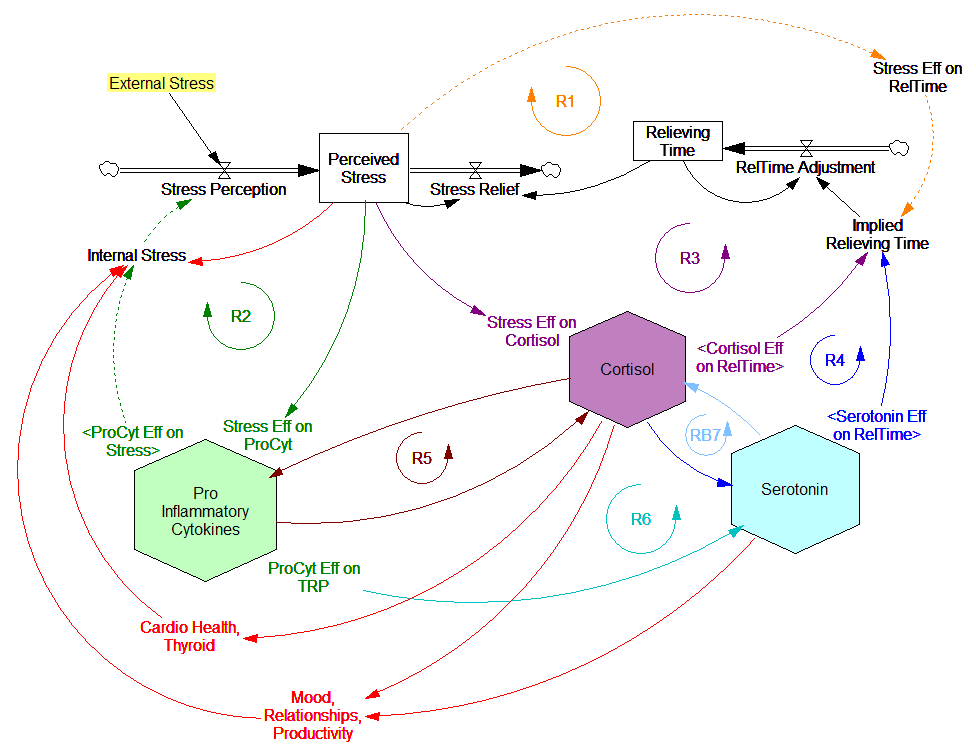
One possibility, discussed in the original paper but out of scope for the model, is that cognitive processing of stress has its own effects. For example, if stress produces stress, e.g., through worrying about stress, it could become self-sustaining. There are plenty of other possible mechanisms. The cortisol system affects cardiovascular health and thyroid function, which could lead to additional symptoms provoking stress. Similarly, mood affects family relationships and job productivity, which may contribute to stress.
These effects can be direct, for example if elevated cortisol causes stressful cardiovascular symptoms. But they could also be indirect, via other subsystems in one’s life. If you incur large health expenses or miss a lot of work, you’re likely to suffer financial stress. Presumably diet and exercise are also tightly coupled to this system.
All of these loops create abundant opportunity for tipping points that can lock you into good health or bad. I think they’re a key mechanism in poverty traps. Certainly they provide a clear mechanism that explains why mental health is not all in your head. Lack of appreciation for the complexity of this system may also explain why traditional medicine is not very successful in treating its symptoms.
If you’re on the bad side of a tipping point, all is not lost however. Positive loops that preserve a stressful state, acting as vicious cycles, can also operate in reverse as virtuous cycles, if a small improvement can be initiated. Even if it’s hard to influence physiology, there are other leverage points here that might be useful: changing your own approach to stress, engaging your relationships in the solution, and looking for ways to lower external stresses that keep the internal causes activated may all help.
I think I’m just scratching the surface here, so I’m interested in your thoughts.
Noon Networks
My browser tabs are filling up with lots of cool articles on networks, which I’ve only had time to read superficially. So, dear reader, I’m passing the problem on to you:
Multiscale analysis of Medical Errors
Insights into Population Health Management Through Disease Diagnoses Networks
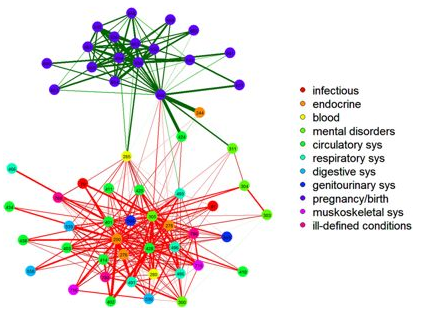
Community Structure in Time-Dependent, Multiscale, and Multiplex Networks
Simpler Math Tames the Complexity of Microbe Networks
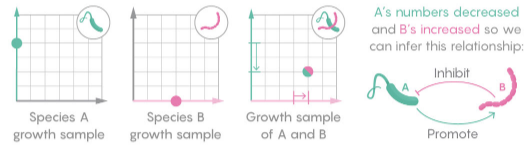
Informational structures: A dynamical system approach for integrated information
In this paper we introduce a space-time continuous version for the level of integrated information of a network on which a dynamics is defined.
A new framework to predict spatiotemporal signal propagation in complex networks
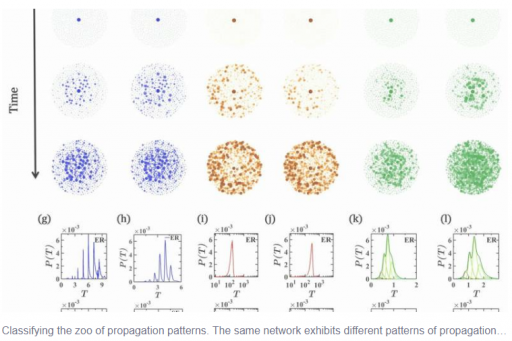
Scientists Discover Exotic New Patterns of Synchronization
Are Project Overruns a Statistical Artifact?
Erik Bernhardsson explores this possibility:
Anyone who built software for a while knows that estimating how long something is going to take is hard. It’s hard to come up with an unbiased estimate of how long something will take, when fundamentally the work in itself is about solving something. One pet theory I’ve had for a really long time, is that some of this is really just a statistical artifact.
Let’s say you estimate a project to take 1 week. Let’s say there are three equally likely outcomes: either it takes 1/2 week, or 1 week, or 2 weeks. The median outcome is actually the same as the estimate: 1 week, but the mean (aka average, aka expected value) is 7/6 = 1.17 weeks. The estimate is actually calibrated (unbiased) for the median (which is 1), but not for the the mean.
The full article is worth a read, both for its content and the elegant presentation. There are some useful insights, particularly that tasks with the greatest uncertainty rather than the greatest size are likely to dominate a project’s outcome. Interestingly, most lists of reasons for project failure neglect uncertainty just as they neglect dynamics.
However, I think the statistical explanation is only part of the story. There’s an important connection to project structure and dynamics.
First, if you accept that the distribution of task overruns is lognormal, you have to wonder where that heavy-tailed distribution is coming from in the first place. I think the answer is, positive feedbacks. Projects are chock full of reinforcing feedback, from rework cycles, Brooks’ Law, schedule pressure driving overtime leading to errors and burnout, site congestion and other effects. These amplify the right tail response to any disturbance.
Second, I think there’s some reason to think that the positive feedbacks operate primarily at a high level in projects. Schedule pressure, for example, doesn’t kick in when one little subtask goes wrong; it only becomes important when the whole project is off track. But if that’s the case, Bernhardsson’s heavy-tailed estimation errors will provide a continuous source of disturbances that stress the project, triggering the multitude of vicious cycles that lie in wait. In that case, a series of potentially modest misperceptions of uncertainty can be amplified by project structure into a catastrophic failure.
An interesting question is why people and organizations don’t simply adapt, adding a systematic fudge factor to estimates to account for overruns. Are large overruns to rare to perceive easily? Or do organizational pressures to set stretch goals and outcompete other projects favor naive optimism?