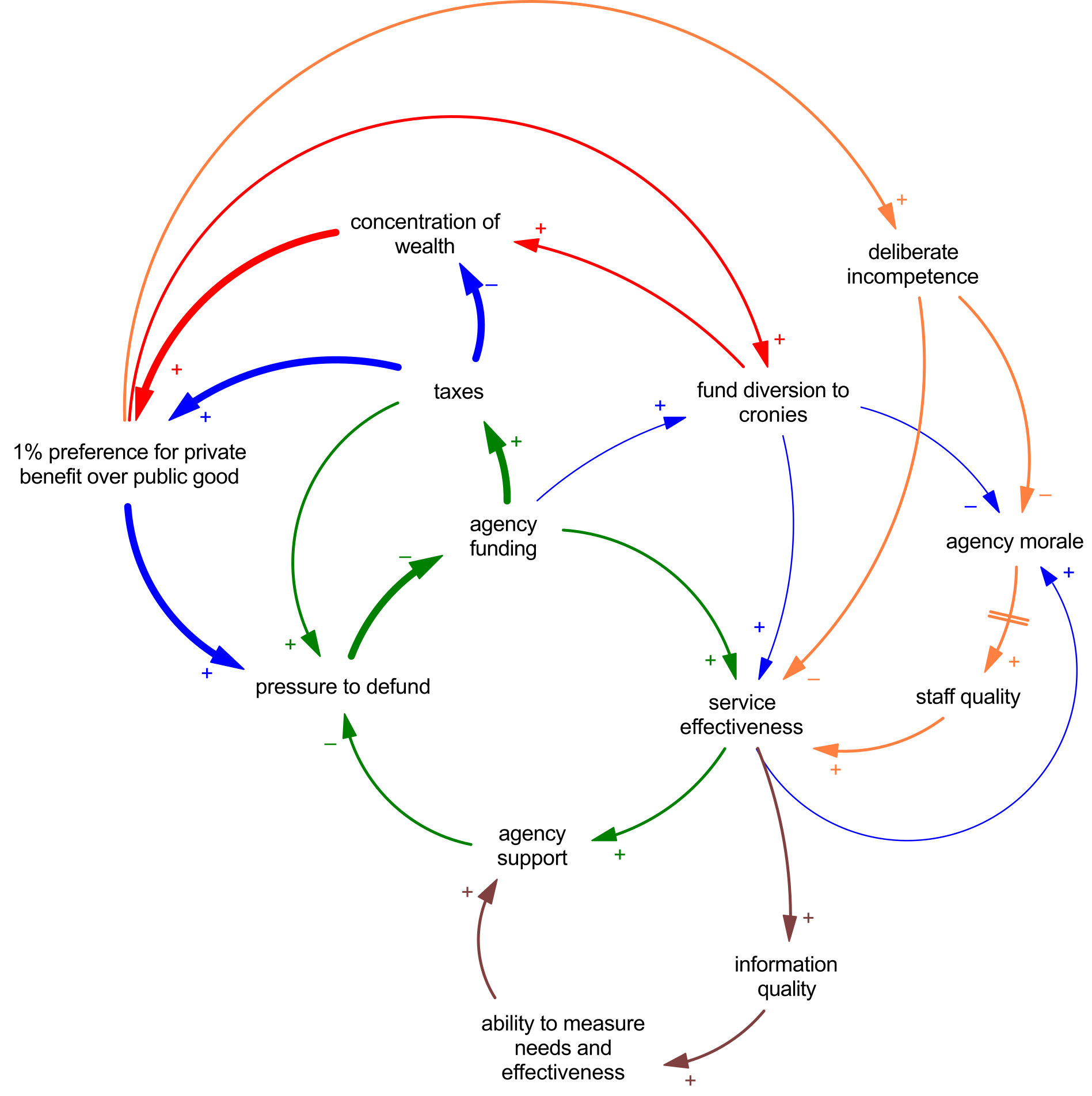
Well, sort of. I decided to use the Beer Game inventory management framework as a test of reasoning in a dynamic situation. I changed “beer” to “televisions” for easy typing, and to avoid triggering any safety provisions on alcohol, but otherwise I tried to stay close to the classic game.
You
I run a retail store. Most weeks, we sell 4 televisions. We typically have 8 televisions in inventory. Each week, we order more televisions to restock the ones sold and maintain our inventory. It takes 2 weeks to receive a television we order. It costs $1 to keep a television in stock for a week, but the opportunity cost of lost sales if no televisions are in stock is $2. This week we sold 8 televisions. How many should we order this week?
ChatGPT
To determine how many televisions you should order this week, let’s break down the process step by step:
1. *Current Inventory:* You have 8 televisions in inventory.
2. *Demand:* This week, you sold 8 televisions.
3. *Lead Time:* It takes 2 weeks to receive a television after ordering.
4. *Costs:*
* Holding Cost: $1 per television per week.
* Stockout Cost: $2 per television per week.
5. *Objective:* Minimize the total cost, considering both holding and stockout costs.
Given that it takes 2 weeks for new stock to arrive, you need to cover the demand for the next 2 weeks.
Let’s calculate:
* *Demand for the next 2 weeks:* 8 televisions per week * 2 weeks = 16 televisions
Now, let’s calculate the total cost for different ordering quantities:
*Scenario 1:* Ordering 16 televisions
o Holding cost for 2 weeks: $1 * 16 televisions * 2 weeks = $32
o No stockout cost
o Total Cost: $32
*Scenario 2:* Ordering 17 televisions
o Holding cost for 2 weeks: $1 * 17 televisions * 2 weeks = $34
o Stockout cost for 1 television for 1 week: $2 * 1 television * 1 week = $2
o Total Cost: $34 + $2 = $36
*Scenario 3:* Ordering 18 televisions
o Holding cost for 2 weeks: $1 * 18 televisions * 2 weeks = $36
o Stockout cost for 2 televisions for 1 week: $2 * 2 televisions * 1 week = $4
o Total Cost: $36 + $4 = $40
Based on these calculations, ordering 16 televisions would minimize your total cost. Therefore, you should order 16 televisions this week.
Verdict: The problem statement is OK, but GPT seems to have taken this as a one-shot static situation. It appears to be neglecting the possibility of reordering in following weeks, and therefore trying to cover the entire shipping pipeline with the order. Also, it’s misunderstood the stockout cost. In any case, it’s overreacting.
You
16 televisions sounds like a lot. What if I just replace the 8 sold by ordering 8 televisions? Or should I order more than 8 in order to replace depleted inventory?
ChatGPT
Ordering just 8 televisions to replace the ones sold might not be the best strategy because it doesn’t account for potential stockouts and the time it takes for new stock to arrive.
Let’s analyze the scenario if you only order 8 televisions:
1. *Demand:* You sold 8 televisions this week.
2. *Lead Time:* It takes 2 weeks to receive new televisions after ordering.
3. *Inventory Depletion:* If you only order 8 televisions, you won’t have enough stock to cover demand for the next 2 weeks.
4. *Potential Stockouts:* There’s a risk of running out of stock, leading to lost sales and stockout costs.
Given these factors, if you only order 8 televisions, you’ll likely face stockouts and incur additional costs. It’s better to order enough to cover the demand for the next 2 weeks and maintain a buffer to minimize the risk of stockouts.
Ordering 16 televisions allows you to cover the demand for the next 2 weeks and maintain your inventory level, considering the lead time for new stock to arrive. It helps minimize the total cost by balancing holding costs and potential stockout costs.
Therefore, ordering 16 televisions would be a more prudent approach to ensure you meet customer demand while minimizing costs in the long run.
Verdict: I’m not quite sure what it’s “thinking” here. For one thing, what I order this week will have no effect on stock for the next two weeks, due to the shipping delay. So if I’m going to be out of stock next week, that’s inevitable. I’ll try to help it out …
You
I forgot to mention that previously we have been ordering 4 televisions per week to replace those sold. That means there are already 8 televisions being shipped to us – 4 arriving next week, and 4 the week after. Does that change the answer?
ChatGPT
Thanks for the clarification. Considering that you have 4 televisions already on order for each of the next 2 weeks, that changes the situation. Let’s adjust the analysis:
1. *Current Inventory:* You have 8 televisions in inventory.
2. *Demand:* You sold 8 televisions this week.
3. *Lead Time:* You have 4 televisions arriving next week and another 4 arriving the week after.
4. *Total Demand to Cover:* 8 televisions sold this week + 8 televisions to cover the next 2 weeks = 16 televisions.
5. *Costs:* Holding cost is $1 per television per week, and the stockout cost is $2 per television per week.
With 16 televisions to cover the next 2 weeks’ demand, you have a couple of options:
*Ordering 8 televisions:* This would cover the immediate demand for the next week, but you would still have to cover the following week’s demand with the existing order. However, you risk stockouts for the second week’s demand.
*Ordering 16 televisions:* This would cover both weeks’ demand without any risk of stockouts. You would not need to hold excess inventory beyond what’s necessary for the next 2 weeks.
Given the potential stockout costs and the need to maintain inventory to cover future demand, ordering 16 televisions seems like the safer option. It ensures that you can meet customer demand for the next 2 weeks without incurring additional costs due to stockouts.
Verdict: I think it still doesn’t get the sequencing of orders and shipments, probably because it’s not really managing with an understanding of bathtub dynamics. I’ll see if it does better on the big picture:
You
I compromised and ordered 12 televisions this week. However, the supplier informed me that they are experiencing stockouts, and it might take 4 weeks to receive televisions in the future. How should I respond by changing my ordering next week?
ChatGPT
Given the new information about the supplier experiencing stockouts and the potential increase in lead time to 4 weeks, you’ll need to adjust your ordering strategy accordingly to mitigate the risk of running out of stock.
Here’s how you can respond by changing your ordering next week:
1. *Assess Current Inventory:* Evaluate how many televisions you have in stock after accounting for this week’s sales and the 12 televisions you ordered.
2. *Estimate Future Demand:* Consider the expected demand for the next 4 weeks based on historical sales data and any other relevant factors.
3. *Calculate Total Demand:* Add up the expected demand for each of the next 4 weeks.
4. *Account for Lead Time:* Since the lead time has increased to 4 weeks, you’ll need to order enough televisions to cover the expected demand during this extended lead time period.
5. *Consider Safety Stock:* Given the uncertainty with the supplier’s stockouts, you may want to increase your safety stock level to buffer against any unexpected fluctuations in demand or delays in delivery.
6. *Place Order:* Based on your assessment of current inventory, future demand, and the need for safety stock, place an order with the supplier for the necessary quantity of televisions to cover the next 4 weeks.
7. *Monitor and Adjust:* Continuously monitor inventory levels, sales data, and any updates from the supplier regarding lead times. Be prepared to adjust your ordering strategy as needed to maintain optimal inventory levels and minimize the risk of stockouts.
Considering the potential for longer lead times and the need to maintain adequate inventory levels during this period of uncertainty, you may want to order a higher quantity of televisions next week to ensure that you can meet customer demand and avoid stockouts.
Verdict: It’s retreated to a list of considerations, rather than proposing specific order numbers, which is probably good. It does mention “lead time” but it doesn’t quite come out and say “keep track of the product in the order pipeline,” which is a key omission. Also, it’s arbitrarily looking at a 4 week horizon.
You
I’ve been talking to some other retail stores, and it turns out that they’re all ordering extra televisions to build up inventory to offset the longer shipping lead times and supplier stockouts. Should I be concerned about this?
ChatGPT
It’s understandable that other retail stores are adjusting their ordering strategies to build up inventory in response to longer shipping lead times and supplier stockouts. However, whether you should be concerned depends on various factors specific to your own retail store, including your sales patterns, storage capacity, financial situation, and the level of risk you’re comfortable with.
Here are some considerations to help you evaluate whether you should be concerned:
1. *Sales Patterns:* Analyze your historical sales data to understand your typical demand patterns. If your sales are relatively stable and predictable, you may not need to build up as much inventory compared to stores with more fluctuating demand.
2. *Storage Capacity:* Consider whether you have sufficient storage space to accommodate extra inventory. Building up inventory can tie up valuable space and increase holding costs if you’re unable to sell the televisions quickly.
3. *Financial Situation:* Evaluate your cash flow and financial resources. Building up inventory requires additional investment, so ensure that you have the financial capacity to handle the increased inventory levels without negatively impacting your cash flow or liquidity.
4. *Supplier Relationships:* Assess the reliability of your supplier and the likelihood of continued stockouts or longer lead times. If you have concerns about your supplier’s ability to fulfill orders consistently, it may be prudent to build up inventory as a precautionary measure.
5. *Competitive Landscape:* Consider how your competitors’ actions might impact your business. If other retail stores are building up inventory to meet customer demand more effectively, you may need to adjust your strategy to remain competitive.
Ultimately, the decision to build up inventory should be based on a careful assessment of your unique circumstances and risk tolerance. While it’s important to be aware of industry trends and competitive dynamics, your focus should be on optimizing inventory levels to meet customer demand efficiently while minimizing costs and risks to your business. If you’re unsure about the best course of action, consulting with a financial advisor or industry expert may provide valuable insights tailored to your specific situation.
Verdict: The list of considerations 1-5 is not bad, but it’s not really on point to the important question, which is whether the bullwhip effect may come around to bite us.
You
Should I be concerned about the possibility that the current supply shortage will eventually be replaced by a supply glut, when manufacturer capacity catches up with these orders? I don’t want to get stuck with a lot of televisions I can’t sell, because suppliers interpreted strategic phantom ordering for real demand.
ChatGPT
Concerns about the possibility of a supply glut once manufacturer capacity catches up with current orders are valid, especially if there’s been a surge in orders due to strategic stockpiling by retailers. Being stuck with excess inventory can tie up capital, lead to storage issues, and potentially result in markdowns or losses if the televisions can’t be sold at full price.
To address this concern, consider the following strategies:
1. *Monitor Industry Trends:* Stay informed about industry trends, including updates on manufacturer capacity, production levels, and market demand. Keep track of news and reports from reliable sources to anticipate potential shifts in supply and demand dynamics.
2. *Maintain Flexibility:* Maintain flexibility in your ordering strategy to adapt to changing market conditions. Avoid overcommitting to large orders or long-term contracts that could leave you vulnerable to a sudden downturn in demand or an oversupply situation.
3. *Diversify Product Range:* Diversify your product range to reduce reliance on any single category or supplier. By offering a broader selection of products, you can mitigate the impact of supply fluctuations in any particular category and capitalize on emerging trends.
4. *Strengthen Supplier Relationships:* Cultivate strong relationships with your suppliers to facilitate open communication and collaboration. Work closely with your suppliers to share information about inventory levels, sales forecasts, and market trends, enabling them to better anticipate your needs and adjust production accordingly.
5. *Implement Just-in-Time Inventory:* Consider implementing a just-in-time inventory system to minimize excess inventory and optimize stock levels based on real-time demand signals. This approach can help you reduce carrying costs and mitigate the risk of overstocking.
6. *Monitor Inventory Levels:* Continuously monitor your inventory levels and sales performance to identify any signs of excess inventory or slow-moving products. Take proactive measures, such as offering promotions or discounts, to clear out excess inventory before it becomes a liability.
By staying vigilant, maintaining flexibility, and fostering strong relationships with suppliers, you can mitigate the risks associated with potential supply gluts and position your retail store to adapt effectively to changing market conditions.
Verdict: again this is a good list, and several of these items might be useful strategic advice for the supply glut problem. #6 mentions inventory monitoring, which is good, but there’s nothing about supply line monitoring, which is bad, though improving communication with suppliers (#4) and switching to JIT (#5) might help. Still, I feel it’s wise to heed the statement at the bottom of every page:
ChatGPT can make mistakes. Check important info.

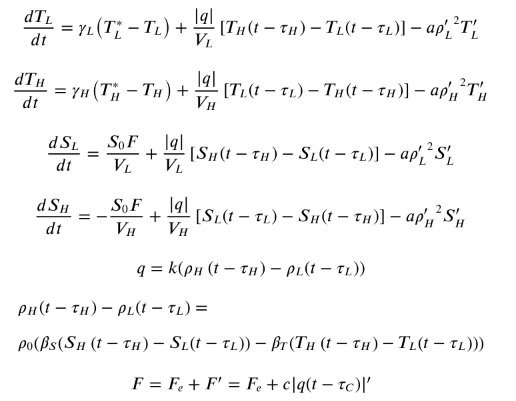 The bad news is that the explanation of these terms is brief to the point of absurdity:
The bad news is that the explanation of these terms is brief to the point of absurdity: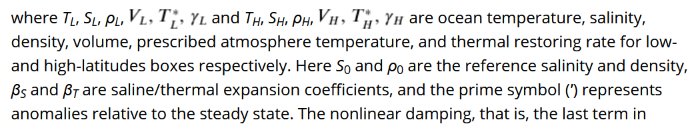 This paragraph requires you to maintain a mental stack of no less than 12 items if you want to be able to match the symbols to their explanations. You also have to read carefully if you want to know that ‘ means “anomaly” rather than “derivative”.
This paragraph requires you to maintain a mental stack of no less than 12 items if you want to be able to match the symbols to their explanations. You also have to read carefully if you want to know that ‘ means “anomaly” rather than “derivative”.