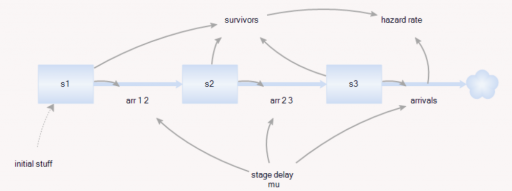
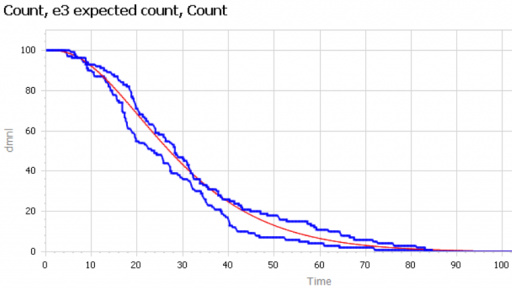
How do we strike the right balance among closed loops revealing all possible leverage points, exogenous drivers for fidelity and economy, and practical focus on feasible policies?
On the SDwisdom blog, Jack Homer wonders whether we should be a little less endogenous:
The party line is that a model’s boundary should be broad enough so that the system’s main observed behaviors—such as S-shaped growth, oscillation, or overshoot and decline—are fully explained by the model’s endogenous structure. One should avoid the use of exogenous time series drivers, because they undermine the ability of the model to explain and to anticipate change.
I mostly agree with this view but want to offer a friendly amendment here. In my experience with real-world clients, I have often encountered situations in which it makes sense to employ exogenous time series for the sake of completeness and realism.
…
My experience suggests that we should be less doctrinaire about the endogenous perspective and understand that “endogenous” is a relative thing. No model can be all-encompassing and explain all observed behavior patterns. That’s why we define a model relative to some subset of behaviors also known as the dynamic problem. As long as the model adequately addresses the dynamic problem, it shouldn’t really matter if the model has some exogenous time series included to improve the model’s realism.
The counterpoint to this might be George Richardson’s excellent article on the value of an endogenous perspective:
But the foundation of systems thinking and system dynamics lies deeper than these and is often implicit or even ignored: it is the “endogenous point of view.” The paper will begin with historical background, clarify the endogenous point of view, illustrate with examples, and argue that the endogenous point of view is the sine%qua%non of systems approaches.
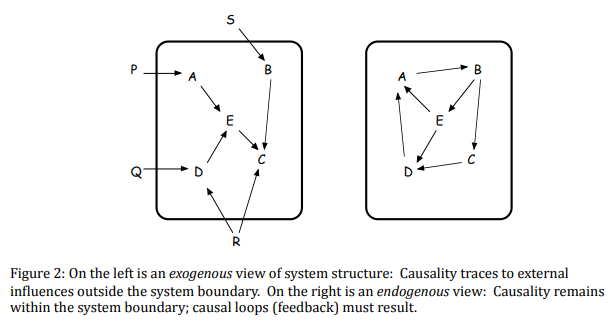
The dead buffalo model on the left in Richardson’s figure is perhaps too extreme. I think what Homer is really arguing for is a middle road that might look like this:
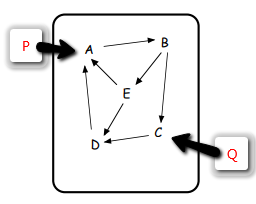
In other words, it’s a hybrid model, with an endogenous core, and a few exogenous drivers from beyond the model boundary. For a firm, this might mean that we model the interactions of marketing, production, human resources, etc. endogenously. But we leave the world crude price and GDP of France exogenous, because we have no plausible means to influence them.
Richardson points out, in the context of Urban Dynamics:
How might thinking exogenously have affected conclusions emerging from these urban models? Consider just one: suppose, as a number of critics of various system dynamics studies have suggested, we chose to use time series data for urban population projections. Suppose the data-based projections were very carefully developed by sophisticated statistical tools and econometric methods, and suppose those projections were fed into URBAN1 in place of the endogenous stock of population. To make the implications easiest to see, let’s suppose the base run of the model looks just as it did in Figure 5b. What would Figure 5c look like? Sadly, population would not show a bump as it did in 5c because the sophisticated exogenous time series data would not be influenced in the slightest by the changing conditions in the model. We would not see the compensating urban migration effects we see in Figure 5c, and we would miss the crucial conclusion that population and business construction dynamics would naturally compensate for the jobs program. We’d probably think it was a long term policy success, and we would be dramatically wrong.
Similarly, a key part of my dissertation critique of the DICE model was the idea that its exogenous representation of technology excluded a set competitive dynamics between fossil fuels and renewables that are crucial to understanding climate policy. In both cases, leaving even a few loops exogenous might dramatically alter policy recommendations.
In another article, Homer rejoins:
In 1977, my teacher, SD pioneer Ed Roberts, wrote an important paper called “Strategies for Effective Implementation of Complex Corporate Models”, based on his years of consulting experience. When it comes to policy recommendations, he said, “the organizations’ ability to absorb the associated change must be assessed…The model-builder and the organization both profit from implementation of moderate change proposals leading to some successful results; both lose from grandiose plans which fail to be moved ahead.”
…
Without too much extra effort beyond what we already do in modeling, we could assess policy feasibility by studying the political situation and its dynamics, looking at trends in public opinion surveys and other indicator data, and talking to experts. We could then calculate the “feasibility-adjusted value” of a policy by multiplying its potential impact (as determined by our SD model) by its likelihood of enactment.
In other words, one might ask, what good is it to know the nature of the best endogenous policy if the key leverage points are beyond your control? Or, as economists put it, what good are first-best policies in a second-best world?
I think Richardson might respond along the lines of Pascal’s wager:
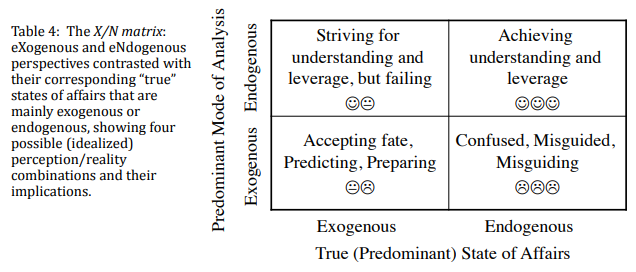
To the extent that we accept some exogeneity in our models, we accept our fate in the lower left box. That choice presumes that our best strategy is to do a good job of predicting and preparing – making the best of a bad situation, or living to fight another day. Is that really a good idea – can we know, or at least make a good guess, whether the true state of affairs is exogenous or endogenous? Richardson argues that if we don’t know which box we’re in, it’s best to choose the endogenous approach:
If one were to recast Table 4 as a decision tree, the decision to take an endogenous point of view in all circumstances would have the highest net payoff, at least in terms of happy faces and the real feelings they represent. An endogenous point of view is potentially empowering, and that feels good to us.
If the right (endogenous) side of the diagram is better in some sense, we should ask a more important question: can we change the state of affairs, so that we can move from the left quadrants to the right? This is related to the idea that we might need to change paradigms to change the system.
This perspective is especially critical for problems like climate change, where the space of politically feasible policies currently does not include anything that actually solves the problem. Treating the infeasible loops as exogenous drivers won’t help. We need to ask, what loops that are now beyond our control can be activated in order to reach a more attractive solution?
Maybe there really is no good solution to climate and other Limits problems. Then perhaps it would be optimal in some sense to take catastrophe as exogenous and use models to plan a personal path through the eye of the storm. Personally, I’m not ready to accept that. My modeling objective remains to die with my boots on tackling the biggest problems.
See also:
Closing loops – practicalities
Why the World Loves Open Loop Models
What kind of model should I use?